ИИ-агенты: что это и когда они действительно нужны
Опорная страница по ИИ-агентам: что считать агентом, когда автономия действительно окупается и в каких случаях команде лучше выбрать workflow, RAG или один LLM-вызов.
Проверено 13 мая 2026 года. Эта страница нужна для одного вопроса: где заканчивается просто LLM-интерфейс и начинается агентный слой. Вокруг термина ИИ-агенты слишком много шума: им называют и чат с одним tool call, и длинные автономные workflow. Практический вопрос другой: когда автономия действительно даёт результат, а когда она просто добавляет стоимость, задержку и лишний риск.
Если нужен короткий ориентир, агент — это система, в которой модель сама выбирает следующий шаг, вызывает инструменты, получает обратную связь из среды и доводит работу до проверяемого результата. Если нужен прикладной маршрут, читайте эту страницу как карту соседних интентов: она помогает быстро понять, нужен ли вам агент вообще и когда честнее уйти в RAG, промпт-инжиниринг или обычный LLM-сценарий без автономии.
Карта кластера ИИ-агентов
Ниже — навигация по соседним интентам. Она нужна, чтобы не смешивать в одной статье базовое определение агента, браузерную автоматизацию, инструментальные протоколы, продакшен-риски и обзоры конкретных продуктов.
| Если вам нужно | Куда идти дальше | Зачем открывать |
|---|---|---|
| Понять базовую механику agent loop и ReAct | Агентный ИИ: архитектуры, ReAct и tool use | Это соседний материал для тех, кто хочет углубиться в паттерны reasoning + acting, а не только в терминологию. |
| Разобраться, как агент подключается к инструментам и данным | MCP: стандарт интеграции ИИ | MCP помогает понять, как устроен слой подключений между моделью и внешними системами. |
| Понять production-слой и ограничения среды | OpenAI Agents SDK и цены и лимиты coding agents | Это маршрут для разработчиков, которым важны orchestration, стоимость, лимиты и правила остановки. |
| Понять browser automation и агентный доступ к интерфейсам | ИИ-агенты в браузере: Computer Use и Operator | Полезно, когда агент должен работать не только с API, но и с интерфейсами, файлами и веб-страницами. |
| Разобрать сбои, риски и ложные ожидания | GTA-2 benchmark, tool-overuse в продакшене, атаки на разработчиков | Это обязательный слой перед любым «давайте дадим агенту доступ ко всему». |
| Связать тему агентов с более широким LLM-стеком | LLM: полный гайд для разработчиков и что такое LLM | Агент — это следующий слой над моделью, retrieval-слоем, инструментами и состоянием. |
Где проходит граница этой страницы
Эта страница не пытается пересказать весь ИИ-стек. Её задача уже: помочь понять, когда модели правда нужен цикл из шагов, инструментов и проверки результата. Если у вашей задачи другой центр тяжести, лучше сразу открыть более точный материал.
| Если вам нужно | Это не сюда | Куда идти вместо этого |
|---|---|---|
| Подобрать модель под бюджет, русский язык и задержку | Это ещё не агентный слой, а выбор базовой модели. | Как выбрать языковую модель и полный гайд по LLM для разработчиков |
| Подключить базу знаний, поиск по документам и цитаты | Если модель должна прежде всего искать и подставлять факты, чаще нужен RAG, а не автономный агент. | RAG: что это и когда нужен в продакшне |
| Научиться писать системные инструкции, few-shot и форматы ответа | Это зона проектирования промпта, а не цикла агента. | Промпт-инжиниринг: как писать запросы и системные промпты |
| Собрать практический стек для разработчика без долгой автономии | Если шаги заранее понятны, чаще выгоднее workflow или обычный LLM-инструмент. | ИИ для разработчиков и ИИ-ассистенты для программистов |
Проверка простая: если между «получил запрос» и «вернул ответ» модели не нужно ничего делать, вы, скорее всего, ещё не в агентном слое. В таком случае сначала выбирают модель, RAG или проектируют промпт, а не тянут в проект агентный фреймворк.
Три фильтра перед пилотом агентной системы
До выбора фреймворка и модели проверьте три вещи. Если хотя бы один пункт не сходится, чаще нужен не агент, а workflow, RAG или обычный LLM-интерфейс.
- Есть внешний контур проверки. Тесты, diff, статус тикета, форма, SQL-результат, отчёт с критериями качества. Агент лучше всего работает там, где среда может быстро сказать «верно / неверно», а не только человек в конце читает длинный ответ.
- Инструменты можно сузить и журналировать. На старте агенту обычно достаточно 2–3 действий, а не доступа сразу к почте, календарю, CRM, shell и продакшену. Если этот слой ещё не разобран, сначала полезнее привести в порядок инструментальный контур и MCP.
- Цена лишнего цикла приемлема. Агентный цикл всегда платит токенами, задержкой и риском лишних действий. Если последовательность шагов заранее понятна, дешевле и надёжнее собрать workflow. Если агент уходит в бесполезную активность, вы получите тот самый tool-overuse в продакшене и счёт за долгий запуск.
Практическое правило простое: сначала определите проверяемый сценарий и бюджет, потом выдавайте автономию. Для инженерных и кодовых задач это особенно важно, потому что экономика агентных запусков быстро уходит из «интересного эксперимента» в реальную статью расходов. Подробно этот слой разобран в материале про цены и лимиты coding agents.
Что такое ИИ-агент
Термин используют слишком широко, поэтому важно сразу провести границу. В Anthropic отдельно различают workflow и agent. Workflow — это схема, где порядок шагов заранее зашит в код. Agent — это система, где модель сама управляет процессом и использованием инструментов. В документации OpenAI, актуальной на 26 апреля 2026 года, agents описаны как приложения, которые планируют, вызывают инструменты, координируют специалистов и хранят достаточно состояния для многошаговой работы.
Практически это даёт четыре признака, без которых слово «агент» обычно оказывается маркетингом:
- у системы есть не только запрос, но и цель с условием «готово»;
- она может выходить за пределы одного ответа и использовать инструменты или внешние системы;
- она получает обратную связь из среды: результат API-вызова, код, скриншот, файл, ошибку, статус задачи;
- она держит состояние между шагами, чтобы не начинать каждый ход с нуля.
Поэтому не каждый чат-бот — агент, и не каждый пайплайн с тремя промптами тоже. Если модель отвечает один раз и на этом всё заканчивается, перед нами обычный LLM-интерфейс. Если цепочка шагов заранее зашита в код и модель не выбирает следующий ход, это workflow. Агент начинается там, где модель получает свободу принятия решений внутри ограниченного контура.
Чем агент отличается от чат-бота, workflow и RAG
| Подход | Кто управляет порядком шагов | Где силён | Где ломается |
|---|---|---|---|
| Чат-бот / один вызов LLM | Пользователь и разработчик | Объяснение, черновики, суммаризация, быстрые ответы | Не умеет надёжно доводить длинную задачу до результата без внешней логики |
| Workflow | Код и заранее заданные ветки | Повторяемые процессы с понятной последовательностью шагов | Плохо переносит нестандартные случаи и меняющийся порядок действий |
| RAG | Разработчик управляет retrieval-слоем, модель пишет ответ поверх найденных документов | Ответы по свежей документации, базе знаний, логам и внутренним данным | RAG не заменяет планирование и выполнение действий; он лишь даёт модели доступ к контексту |
| AI-агент | Модель внутри ограниченного контура | Открытые задачи, где нужно выбирать следующий шаг, инструменты и точки проверки | Цена, latency, накапливающиеся ошибки, prompt injection, лишние действия и сложная отладка |
С практической стороны это значит простую вещь: RAG и agent не конкуренты. RAG — это часто один из инструментов агента. Chatbot может быть интерфейсом к агенту. Workflow может управлять агентом на верхнем уровне. Ошибка начинается тогда, когда вся эта архитектура смешивается в одно слово и команда перестаёт понимать, какой именно слой у неё даёт ценность или создаёт риск.
Из чего состоит современный агентный стек
По официальной документации OpenAI, LangChain и Google ADK зрелый агент — это уже не просто модель плюс список функций. Полезный агентный контур почти всегда состоит из одних и тех же слоёв: модели, инструментов, состояния, runtime-оркестрации и guardrails. Меняются названия фреймворков и интерфейсов, но не инженерная логика: агенту нужна среда, в которой можно ограничивать права, журналировать шаги, восстанавливаться после ошибок и проверять результат.
Если разложить агент на детали, получаются пять отдельных слоёв.
- Модель. Она интерпретирует цель, предлагает следующий шаг и формирует вызовы инструментов.
- Инструменты. API, поиск, браузер, shell, база данных, файловая система, календарь, почта, кодовый рантайм.
- Память и состояние. Краткосрочный state внутри сессии плюс долговременные записи, файлы, артефакты и история выполненных шагов.
- Harness или runtime. Управляющий слой, который задаёт цикл запуска, approvals, handoffs, лимиты, трассировку и восстановление после сбоев.
- Guardrails. Ограничения прав, allowlist инструментов, проверки результатов, человек в контуре и правила остановки.
Google ADK и MCP помогают увидеть ту же картину с разных сторон: агенту нужны не только модель и prompt, но и слой подключений к инструментам, session state, артефакты, наблюдаемость и понятные правила исполнения. Иными словами, зрелый агентный стек — это не «ещё один промпт», а связка модели, среды, инструментального протокола и контроля.
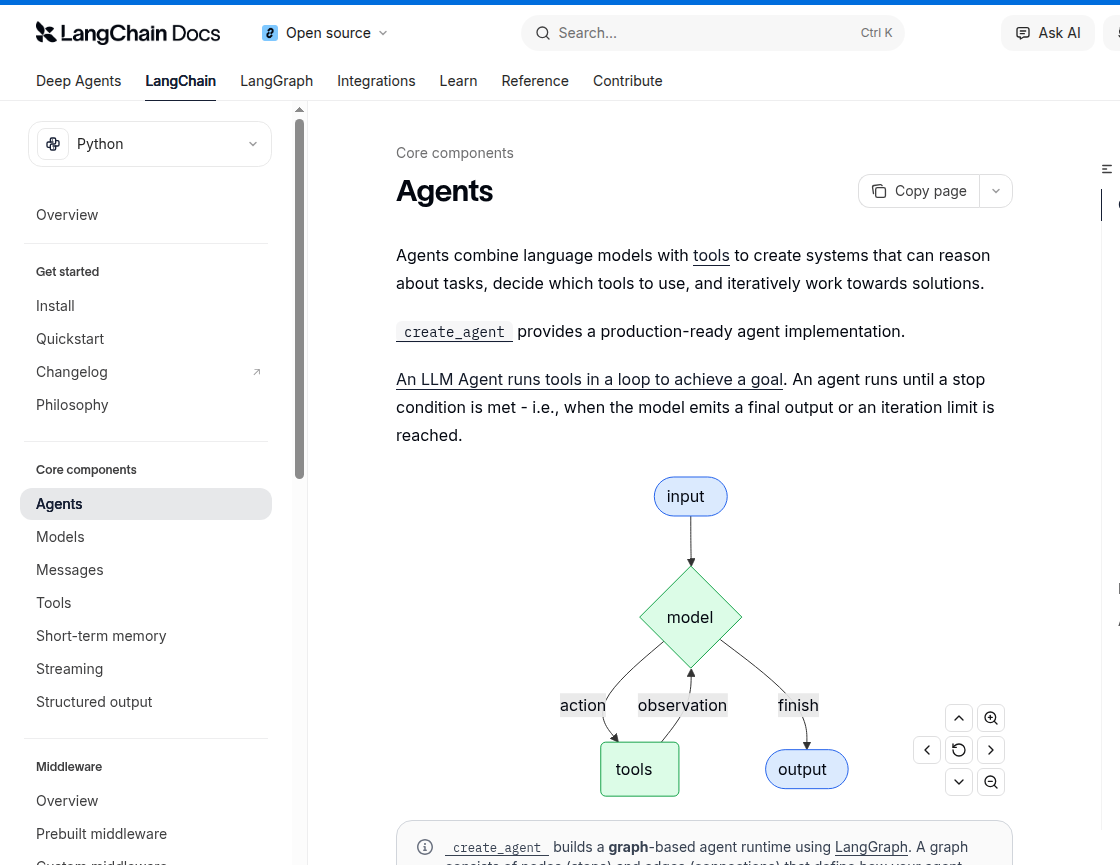
Где ИИ-агенты уже дают результат
Лучше всего агенты чувствуют себя там, где у задачи есть внешний контур проверки. Anthropic прямо пишет, что агентный подход особенно полезен, когда работа сочетает разговор и действие, имеет ясные критерии успеха, допускает feedback loops и оставляет место для человеческого контроля.
Код, инфраструктура и долгие инженерные задачи
Это сейчас самый понятный сценарий. Код можно проверять тестами, линтерами, сборкой и диффами, а ошибки не нужно угадывать «на слух». Поэтому именно coding agents быстрее всего ушли от демо к рабочему контуру. Для этого слоя важны не столько бренды, сколько свойства среды: воспроизводимость, ограничение прав, трассировка шагов и понятная цена запуска. Практический слой мы отдельно разбирали в материалах про OpenAI Agents SDK, agentic coding в OpenAI Codex и цены и лимиты coding agents.
Браузер, десктоп и интерфейсы, где нет нормального API
Второй сильный сценарий — desktop automation. Официальная документация Anthropic по computer use описывает агентный цикл, в котором модель видит экран, запрашивает действия и получает обратную связь из среды. Но там же есть ключевая оговорка: такой контур требует отдельной sandbox-среды и минимальных привилегий. Для практической стороны темы у нас есть отдельный разбор Computer Use и Operator.
Повторяемые рабочие процессы внутри команды
Ещё один рабочий сценарий — shared workflow с approvals, правами и мониторингом, а не личный чат-бот в отдельном окне. OpenAI продвигает это направление через workspace agents: идея в том, что агент живёт внутри командного процесса, собирает контекст из нужных систем и двигает работу дальше по согласованным правилам. Если нужен именно этот слой, смотрите наш материал про workspace agents.
Где агенты ломаются и почему это важно
Самая опасная ошибка — судить об агентах по ярким роликам. На длинной дистанции всё жёстче. В benchmark GTA-2, опубликованном 17 апреля 2026 года, авторы отдельно проверяли open-ended workflow-задачи и получили неприятный вывод: top model показала только 14.39% успеха на длинных сценариях. Это не означает, что агенты бесполезны. Это означает, что между «умеет вызвать инструмент» и «доводит рабочий процесс до результата» всё ещё огромная пропасть.
Второй провал — лишние действия. Агент может выглядеть активным и при этом бессмысленно тратить токены, время и права доступа. Мы отдельно разбирали это в материале про tool-overuse в продакшене. Для бизнеса это не академическая тонкость, а счёт за инфраструктуру и скрытый риск побочных эффектов.
Третий провал — безопасность. OWASP LLM01:2025 Prompt Injection прямо напоминает, что уязвимость бывает и прямой, и косвенной. Как только агент читает внешние файлы, веб-страницы, тикеты, README или почту и при этом может делать действия от вашего имени, prompt injection перестаёт быть абстрактной темой из research. У нас есть практический пример в статье про атаки на разработчиков через тестовые задания.
Четвёртый провал — накопление ошибок. Агент может несколько шагов подряд идти в целом верно, а потом медленно испортить результат мелкими допущениями. Именно поэтому полезно читать не только vendor-анонсы, но и разборы вроде почему benchmark'и вводят в заблуждение, GTA-2 и кейс про libGDX и быстрое накопление ошибок.
Когда агент не нужен
Агентный слой легко переоценить. И Anthropic, и Google ADK подталкивают к одной и той же мысли: сначала проверьте, не решается ли задача более простым способом. Во многих командах агент пока не нужен в четырёх типовых случаях.
- Если задача сводится к одному ответу или трансформации текста, часто хватает одного вызова LLM.
- Если порядок шагов заранее понятен и редко меняется, дешевле и надёжнее собрать workflow без автономии модели.
- Если главная проблема — доступ к свежим документам, а не выполнение действий, чаще нужен RAG, а не агент.
- Если у команды нет eval-набора, логов, ограничений прав и точки человеческого подтверждения, автономия только ускорит хаос.
Полезный вопрос звучит не «можем ли мы сделать агента», а «что конкретно он должен довести до результата лучше, чем workflow или обычный LLM-интерфейс».
Как начинать без дорогой ошибки
- Возьмите открытую, но проверяемую задачу. Хороший старт — код, triage, поиск по документам, отчёт с критериями качества или повторяемый рабочий процесс.
- Дайте агенту 2-3 инструмента, а не 12. Чем шире свобода в первый день, тем труднее понять, что именно ломает результат.
- Сразу введите бюджет: лимит шагов, лимит стоимости, таймаут, политика остановки и fallback на человека.
- Разведите read-only и mutating actions. Читать тикет и писать в CRM — это разные уровни риска.
- Соберите свой benchmark на реальных задачах и сравните агента с более простой альтернативой: workflow, RAG или обычным чатом.
Если на этом этапе хочется идти дальше, следующий логичный маршрут такой: сначала MCP и инструментальный слой, потом production-стек OpenAI Agents SDK, затем экономика агентных запусков и только после этого — расширение прав и долгих workflow.
Что читать дальше по кластеру
Если использовать эту страницу как карту, дальше удобно идти по одному из трёх маршрутов.
1. База и архитектура
- Агентный ИИ: архитектуры, ReAct и tool use
- MCP: стандарт интеграции ИИ
- LLM: полный гайд для разработчиков
2. Production и среда исполнения
3. Риски и надёжность
- GTA-2 benchmark AI-агентов
- Почему метрики агентных систем обманывают
- Tool-overuse в продакшене
- Атаки на разработчиков через агентный контур
Источники и проверка фактов
Для этой опорной страницы официальные источники повторно сверены 13 мая 2026 года. Быстро меняющиеся продуктовые детали убраны из ключевых определений, а оставшиеся ссылки привязаны к первоисточникам и документации. Если вам нужны текущие цены, доступность или лимиты конкретного агентного продукта, перепроверяйте их перед внедрением: этот слой меняется заметно быстрее, чем evergreen-объяснения архитектуры.



