Что такое LLM: как работают большие языковые модели
Опорная страница по LLM: как модель работает на уровне токенов, где проходят ее границы и когда для задачи уже нужны RAG, поиск или агентный слой.
Проверено 13 мая 2026 года. LLM, или большая языковая модель, - это нейросеть, которая получает текст как последовательность токенов и предсказывает, что должно идти дальше. На этом механизме держатся чат-боты, помощники для кода, поиск по документам и значительная часть современных ИИ-интерфейсов.
У этой страницы узкая задача: объяснить механику LLM без рейтингов моделей, прайс-листов и споров о том, чей API сильнее. Такие детали меняются слишком быстро. Гораздо стабильнее базовые вещи: токены, трансформер, предобучение, дообучение на инструкциях, контекстное окно и границы самой модели.
Если вам нужен общий маршрут для разработчиков, переходите в полный гайд по LLM для разработчиков. Здесь фокус уже на другом вопросе: что именно делает LLM и чего от нее не стоит ждать без поиска, RAG и инструментов.
Коротко: что такое LLM
| Термин | Что означает на практике | Почему это важно |
|---|---|---|
| LLM | Большая языковая модель, обученная предсказывать следующий токен по контексту. | Это базовый языковой слой для чат-ботов, помощников в коде, поиска по документам и агентных систем. |
| Токен | Кусок текста: слово, часть слова, пробел, знак препинания или символ. | Токены определяют стоимость, лимит запроса и объем памяти модели в одном диалоге. |
| Контекстное окно | Все токены, которые модель может учитывать в текущем запросе и ответе. | Если нужного факта нет в контексте, модель может не знать его или придумать правдоподобную замену. |
| RAG | Поиск нужных документов и передача их в контекст модели перед ответом. | Помогает опираться на актуальные источники, а не только на внутренние представления модели. |
| ИИ-агент | LLM плюс инструменты, состояние и право выбирать следующий шаг. | Модель перестает быть только интерфейсом ответа и начинает вести многошаговую работу. |
Куда идти дальше по LLM-кластеру
Эта статья закрывает только базовый объясняющий интент. Как только вопрос становится прикладным, лучше сразу переходить в более узкий материал, а не пытаться выжать все из одной страницы.
| Если вам нужно | Куда идти дальше | Зачем открывать |
|---|---|---|
| Получить широкую карту LLM-кластера для разработки | Полный гайд по LLM для разработчиков | Это главная карта кластера по выбору модели, API, RAG, открытым моделям и типовым рискам. |
| Выбрать модель под бюджет, русский язык и задержку | Как выбрать языковую модель | Это отдельный материал по выбору, поэтому эта страница не должна спорить с ним за один и тот же интент. |
| Работать со свежими документами и базой знаний | RAG: как работает и когда нужен в продакшне | RAG нужен, когда одной памяти модели уже недостаточно и нужен внешний источник истины. |
| Сделать ответы стабильнее и дешевле на уровне запроса | Промпт-инжиниринг: как писать запросы к ИИ | Это маршрут для проектирования запросов, few-shot и формата ответа, а не для объяснения самой природы LLM. |
| Разобраться с локальным и открытым стеком | Open-source модели: Llama, Mistral, Qwen, Ollama: как запустить локальную LLM | Полезно, если вопрос уже не в определении LLM, а в контроле над инфраструктурой и приватностью. |
| Подключать инструменты и давать модели автономию | AI-агенты: что это, как работают и где полезны | Агент - это следующий слой над LLM, а не синоним самой модели. |
Главная идея: модель предсказывает токены
LLM получает входной текст и разбивает его на токены. В материалах OpenAI токены описаны как единицы, в которых модель видит текст: это может быть символ, часть слова или целое слово. В том же стеке используется библиотека tiktoken, а в справке OpenAI отдельно отмечено, что токены участвуют и в лимитах контекста, и в тарификации.
Это не косметическая деталь. Токенизация напрямую влияет на стоимость запроса и на то, сколько документов, кода или истории диалога поместится в один вызов модели. Для русского, английского и других языков соотношение между символами, словами и токенами различается, поэтому один и тот же смысл в разных языках занимает разный объем контекста.
Большинство современных токенизаторов используют подсловные алгоритмы. Это помогает не разваливаться на редких словах и именах: модель видит не один огромный неизвестный кусок, а набор более знакомых подчастей, с которыми уже умеет работать.
Трансформер: почему все началось с механизма внимания
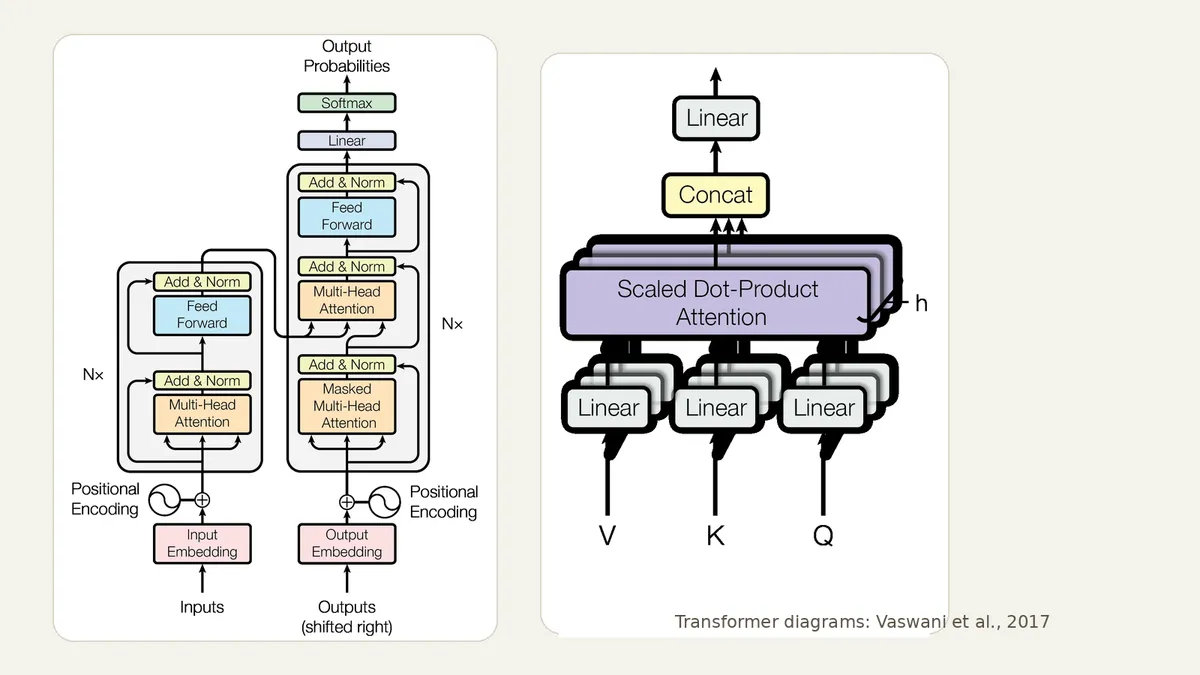
Фундамент современной LLM - архитектура Transformer из статьи Attention Is All You Need, опубликованной в 2017 году. До трансформеров популярные языковые модели часто обрабатывали последовательности по шагам: слово за словом. Это плохо масштабировалось на больших данных.
Трансформер заменил рекуррентную обработку механизмом внимания. Self-attention позволяет каждому токену смотреть на другие токены в контексте и оценивать, какие связи важны для следующего шага. В предложении «Кот лежал на коврике, потому что он устал» модель должна связать «он» с «кот», а не с «коврик». Attention как раз и дает математический способ взвешивать такие связи.
У трансформера есть еще одно практическое преимущество: его проще распараллеливать на GPU. Поэтому модели стало возможно обучать на огромных корпусах текста и кода. В статье 2017 года авторы показали, что Transformer быстрее обучается на задачах машинного перевода и дает качество выше прежних архитектур на выбранных бенчмарках. Дальше индустрия просто масштабировала эту идею.
Как обучают LLM
Упрощенно обучение LLM состоит из трех уровней. В реальных продуктах к ним добавляют фильтрацию данных, безопасность, постобучение, системные инструкции, инструменты и постоянные оценки качества. Но базовая логика такая.
1. Предобучение
На этом этапе модель видит огромный корпус текста и учится предсказывать следующий токен. В статье Language Models are Few-Shot Learners OpenAI описала GPT-3 как авторегрессионную модель на 175 млрд параметров. Это полезный исторический ориентир не потому, что GPT-3 актуальна в 2026 году, а потому, что именно эта волна показала, как резко растут возможности при масштабировании модели и данных.
2. Дообучение на инструкциях
После предобучения модель умеет продолжать текст, но не обязательно умеет быть полезным помощником. Ей показывают пары «запрос - хороший ответ», учат соблюдать формат, отвечать по делу, отказываться от опасных инструкций, писать код и структурировать вывод. В статье InstructGPT этот сдвиг описан прямо: базовая GPT-3 была обучена предсказывать текст, а не безопасно выполнять намерение пользователя.
3. Обучение по предпочтениям
Дальше ответы сравнивают. Люди или другие модели выбирают, какой вариант лучше: точнее, полезнее, безопаснее, честнее. На этих предпочтениях строят модель вознаграждения и донастраивают LLM. В OpenAI это классический RLHF, обучение с подкреплением на обратной связи от людей. Anthropic в работе Constitutional AI описала похожую схему с RLAIF, где часть обратной связи дает другая модель, руководствуясь набором принципов.
Это не делает модель безошибочной. Оно меняет поведение: модель чаще следует инструкциям, лучше держит формат и реже отвечает опасно. Но галлюцинации, слабая проверка фактов и ошибки в логике остаются инженерной проблемой, а не решенной задачей.
Что такое параметры и почему «больше» уже не всегда значит «лучше»
Параметры - это числовые веса нейросети. Если говорят «70B model», обычно имеют в виду примерно 70 млрд параметров. Чем больше параметров, тем выше потенциальная емкость модели, но сама по себе цифра мало что гарантирует.
В 2020 году OpenAI опубликовала работу о законах масштабирования: потеря модели предсказуемо уменьшается с ростом размера модели, объема данных и вычислений. В 2022 году DeepMind в работе Chinchilla показала важную поправку: при фиксированном бюджете нельзя просто надувать число параметров, нужно соразмерно увеличивать обучающие токены. Иначе большая модель остается недообученной.
Отсюда практический вывод: сравнивать LLM только по числу параметров бессмысленно. Нужны данные о качестве обучающего корпуса, постобучении, контексте, инструментах, цене, задержке и реальных задачах. Небольшая модель, хорошо обученная под конкретный сценарий, иногда полезнее огромной универсальной.
Контекстное окно: рабочая память модели
Контекстное окно - это не память в человеческом смысле. Это объем входа и выхода, который модель может учитывать в текущем запросе. Если вы отправили файл, историю диалога, системную инструкцию и попросили ответ на 3 000 токенов, все это конкурирует за одно окно.
По состоянию на 6 мая 2026 года официальные материалы OpenAI, Anthropic и Google уже описывают модели с очень большими окнами: от сотен тысяч до примерно миллиона токенов и выше. Но для этой страницы важнее не рекорд, а инженерный вывод: большое окно не отменяет рост цены, задержки и просадку качества на длинном контексте.
Поэтому длинный контекст полезен как запас емкости, а не как замена архитектуре. Если нужно работать со свежими документами, цитатами, правами доступа и проверяемыми фактами, одной большой модели обычно мало: приходится добавлять retrieval, RAG или внешний код, который проверяет результат.
| Что дает длинный контекст | Где помогает | Где ловушка |
|---|---|---|
| Можно загрузить больше документов за один запрос. | Анализ договоров, кодовых баз, логов, исследовательских PDF. | Модель может пропустить важную деталь в середине длинного контекста. |
| Можно давать много примеров прямо в промпте. | Классификация, стиль ответа, извлечение данных по шаблону. | Примеры могут конфликтовать между собой или с системной инструкцией. |
| Можно меньше дробить задачу. | Ревью большого PR, сравнение версий документа, аудит базы знаний. | Цена и задержка растут, а качество не обязательно растет линейно. |
Как LLM генерирует ответ
Во время инференса модель не пишет весь ответ сразу. Она берет контекст, считает распределение вероятностей для следующего токена, выбирает токен, добавляет его к контексту и повторяет цикл. Поэтому длинные ответы занимают время: каждый новый токен зависит от уже сгенерированной последовательности.
Параметры генерации управляют не «умом» модели, а способом выбора токена. Temperature повышает или снижает случайность. Top-p ограничивает выбор наиболее вероятной частью распределения. Если нужна строгая классификация или извлечение JSON, температуру обычно снижают. Если нужен черновик идей, допускают больше вариативности.
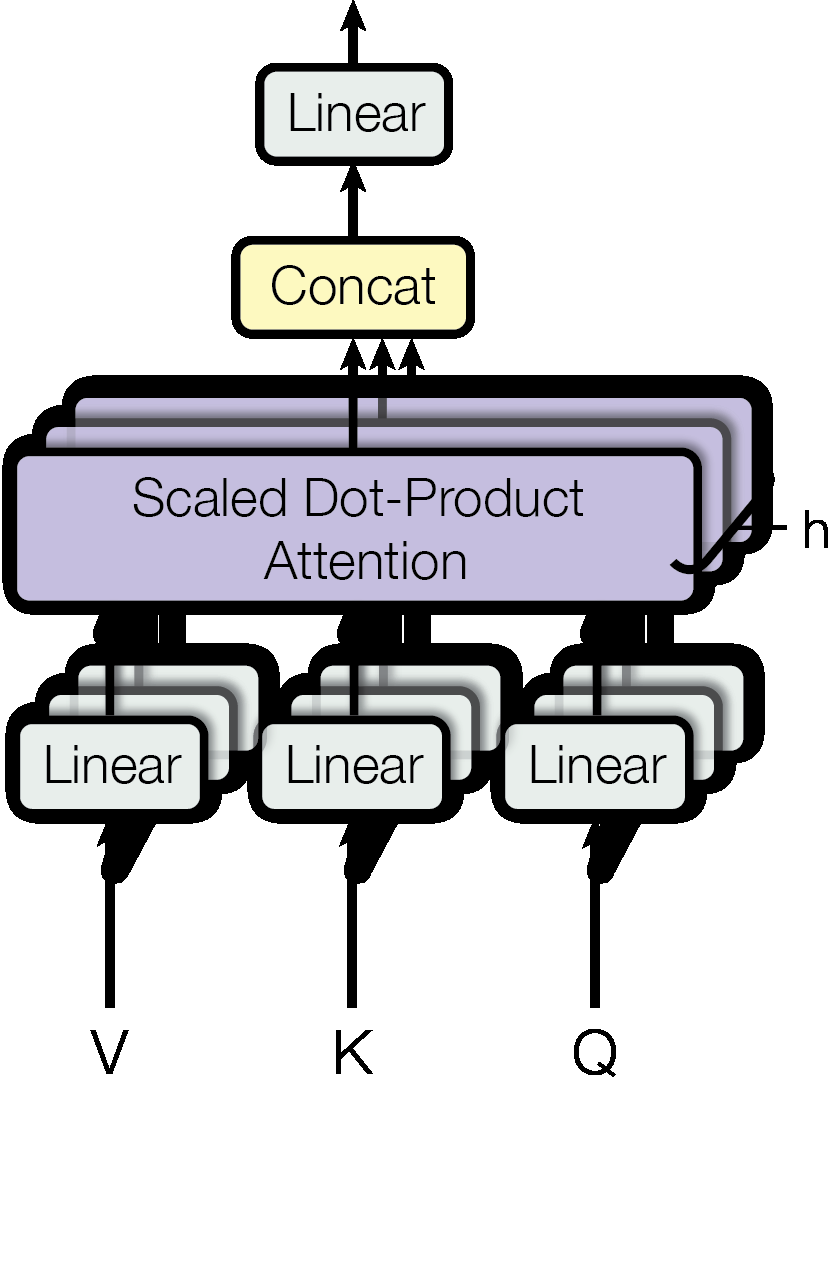
Multi-head attention полезен тем, что разные головы могут ловить разные типы отношений: синтаксис, дальние зависимости, соответствие сущностей, структуру кода. Внутри это не «мысли», а матричные операции. Но для инженера важен эффект: модель удерживает связи между частями текста лучше, чем старые последовательные архитектуры.
Чем LLM отличается от поиска, RAG и агента
| Подход | Что делает | Когда выбирать |
|---|---|---|
| Поиск | Находит существующие страницы и документы. | Нужно быстро проверить факт, найти первоисточник, собрать ссылки. |
| LLM без внешних источников | Генерирует ответ из обученных представлений и текущего контекста. | Нужно объяснение, черновик, рефакторинг, резюме текста, который уже в запросе. |
| RAG | Сначала ищет релевантные фрагменты, потом передает их модели. | Нужны ответы по базе знаний, документации, внутренним регламентам или свежим данным. |
| ИИ-агент | Планирует шаги и вызывает инструменты: поиск, код, файлы, API. | Нужно не только ответить, но и выполнить работу: проверить PR, собрать отчет, обновить данные. |
Самая частая ошибка внедрения: ждать от чистой LLM поведения поисковой системы или базы данных. Если задача требует свежих фактов, точных ссылок, статусов, цен или документов, модель должна получать эти данные через RAG, поиск или API. Иначе она будет достраивать ответ по вероятности.
Где LLM сильны
LLM хороши там, где нужно работать с неструктурированным языком: объяснить сложный текст, переписать документ, найти противоречия, написать черновик, перевести с учетом контекста, сгенерировать тесты, помочь с кодом, извлечь сущности из письма или привести хаотичные заметки к структуре.
В разработке они особенно полезны как ускоритель рутины. Модель может предложить план миграции, объяснить незнакомый модуль, написать тест-кейсы, подсказать возможные причины ошибки. Но она не заменяет владельца кода. Проверка, запуск тестов, ревью безопасности и понимание архитектуры остаются за человеком или за отдельными автоматизированными проверками.
Где LLM слабые
Слабые места вытекают из самой природы технологии.
- Галлюцинации: модель может уверенно написать неверный факт, несуществующую ссылку или выдуманную цитату.
- Актуальность: без внешнего поиска модель не знает, что изменилось после обучения или после последнего обновления продукта.
- Скрытая зависимость от контекста: маленькая правка в промпте может изменить ответ сильнее, чем кажется.
- Точные вычисления: арифметику, юридические выводы, медицинские рекомендации и финансы нельзя отдавать модели без проверяемых инструментов и эксперта.
- Длинный контекст: даже если окно большое, модель может хуже помнить середину документа и путать похожие фрагменты.
Хороший LLM-пайплайн строится вокруг этих ограничений. Для фактов нужны источники. Для чисел - вычислитель. Для кода - тесты. Для критичных решений - человек в контуре. Для повторяемых задач - оценочные наборы и регрессии.
Когда базового объяснения уже недостаточно
Эта страница отвечает на вопрос «что такое LLM». Как только задача становится прикладной, лучше перейти в более узкий материал, а не смешивать в одном URL выбор модели, RAG, локальный стек и агентный слой.
Если нужно выбрать модель под бюджет, русский язык и задержку, откройте материал про выбор языковой модели. Если нужны ответы по свежим документам и базе знаний, идите в RAG-гайд. Если хотите сделать ответы стабильнее на уровне запроса, нужен промпт-инжиниринг. Если вопрос уже в локальном или open-source стеке, переходите к open-source моделям и Ollama. Если модель должна сама вызывать инструменты и делать несколько шагов, это уже тема AI-агентов.
Вопрос «какая модель лучше на русском» тоже живет отдельно. Он зависит от домена, бюджета, задержки и критериев качества, поэтому его лучше решать в материале про выбор модели, а не в базовом объясняющем материале про устройство LLM.
Практический вывод
LLM - не магический интеллект и не просто автодополнение. Это вероятностная система для работы с токенами, усиленная большими данными, архитектурой Transformer, постобучением и инструментами. Она особенно полезна там, где вы даете ей правильный контекст, понятную задачу и способ проверить результат.
Если нужно внедрять LLM в продукт, держите в голове четыре вещи: источник данных, качество запроса, способ проверки и стоимость на реальном объеме. Без этого даже сильная модель быстро превращается в генератор догадок с красивым интерфейсом.
Часто задаваемые вопросы
Что такое LLM простыми словами?
LLM - большая языковая модель. Она получает текст, разбивает его на токены и предсказывает следующий токен с учетом контекста. Так рождаются ответы, резюме, переводы и код.
LLM действительно понимает текст?
В человеческом смысле - нет. Модель не имеет опыта, намерений и проверки реальности. Но она выучивает сложные статистические связи в языке и данных, поэтому может выполнять задачи, которые выглядят как понимание.
Чем LLM отличается от нейросети вообще?
LLM - частный тип нейросети, обученный прежде всего на языковых последовательностях. Нейросети бывают разными: для изображений, звука, рекомендаций, управления роботами и прогнозов. LLM специализируется на тексте и связанных с ним задачах.
Можно ли запускать LLM локально?
Да, если модель помещается в память вашего устройства. Для локального запуска часто используют открытые модели и квантование: это снижает требования к железу, но может ухудшить качество. Конкретные цифры зависят от модели, размера, формата и рантайма.
Почему LLM иногда выдумывает факты?
Потому что ее базовая задача - сгенерировать вероятное продолжение, а не доказать истинность каждого утверждения. Для фактов нужны внешние источники, поиск, RAG, ссылки и проверка человеком.
Источники и проверка фактов
Для этой страницы 13 мая 2026 года повторно сверены базовые академические статьи и официальные материалы OpenAI, Anthropic и Google. Быстро меняющиеся цены, линейки моделей и сравнения конкретных вендоров сознательно вынесены в соседние страницы кластера, чтобы базовый объясняющий слой не старел вместе с рынком.
- Vaswani et al., «Attention Is All You Need» - архитектура Transformer и схемы в статье.
- Brown et al., «Language Models are Few-Shot Learners» - GPT-3 как один из ключевых исторических ориентиров масштабирования.
- OpenAI Cookbook: How to count tokens with tiktoken, OpenAI Help Center: What are tokens and how to count them и openai/tiktoken - токены, лимиты контекста и BPE-токенизация.
- OpenAI Scaling Laws и DeepMind Chinchilla - масштабирование моделей, данных и вычислений.
- OpenAI InstructGPT и Anthropic Constitutional AI - RLHF и RLAIF.
- Anthropic Context windows и Google Gemini long context - длинный контекст и его практические ограничения, повторно сверено 13 мая 2026 года.



