Как выбрать языковую модель под задачу в 2026 году
Практическая схема выбора языковой модели в 2026 году: закрытые и open-weight модели, контур данных, российские ограничения и маршрутизация.
Проверено 7 мая 2026 года. Выбрать языковую модель стало сложнее по простой причине: рынок меняется не раз в год, а раз в несколько недель. Если вы открывали прайсинги в апреле, то уже могли видеть одну картину; если открываете их сейчас, то у OpenAI в публичной линейке уже есть GPT-5.5, у Anthropic — Opus 4.7 и Sonnet 4.6, а у Google frontier-preview уже сместился к Gemini 3.1 Pro, тогда как спокойный GA-слой по-прежнему держится на Gemini 2.5.
Из-за этого рынок часто обсуждают в неверной логике: «какая модель лучшая?» Такой вопрос почти всегда бесполезен. Полезный вопрос другой: какая модель закрывает ваш сценарий с нужным качеством, допустимой задержкой, понятной стоимостью и в допустимом контуре данных. У поддержки, кодового агента, внутреннего аналитика и локального RAG это четыре разных выбора.
Есть и ещё один фильтр, который русскоязычные команды вспоминают слишком поздно. До сравнения качества проверьте доступность сервиса в вашем регионе, схему закупки, политику по данным и журналирование. По состоянию на 7 мая 2026 года OpenAI прямо пишет, что API поддерживается только в странах и территориях из опубликованного списка, а если страны в списке нет, сервис не поддерживается; Россия там не перечислена. Anthropic для Claude API тоже отсылает к собственному списку supported countries & regions, и России в нём нет.
Ниже — практическая схема выбора без фетиша вокруг бенчмарков. Мы опираемся на актуальные официальные страницы OpenAI, Anthropic, Google, Meta, Mistral и Qwen и переводим их маркетинговые формулировки в инженерные критерии: где нужен дорогой флагман, где хватает рабочей середины, где важнее стабильный GA-слой, а где разумнее сразу строить гибридный стек с open-weight моделями.
Куда идти, если у вас уже другой вопрос
| Если вам нужно | Куда идти дальше | Почему это отдельная страница |
|---|---|---|
| Получить широкую карту LLM-рынка | Полный гайд по LLM для разработчиков | Этот материал — decision-layer по выбору модели, а не общий hub по LLM, RAG, агентам и архитектурам. |
| Сравнить только open-weight семейства | Open-weight модели: Llama 4, Mistral и Qwen | Там выбор идёт внутри открытого слоя, а не между закрытым API, локальным контуром и маршрутизацией. |
| Решить, нужен ли вам open-weight вместо внешнего API | Открытые модели vs закрытые API | Это уже вопрос ownership-модели, лицензий, стоимости системы и контроля над данными. |
| Выбрать платную подписку для личной работы | Сравнение ChatGPT Plus, Claude Pro и Gemini | Там речь про потребительские планы и личный workflow, а не про API-слой и архитектуру продакшна. |
| Понять, что реально доступно российской команде | ИИ для российских компаний | Здесь мы только фиксируем фактор региона, а не разбираем весь procurement, санкционные риски и локальные альтернативы. |
Если же вопрос у вас именно такой: какую модель брать под конкретную задачу , дальше будет decision-map без лишнего маркетинга.
Сначала выберите режим, а не название модели
Перед тем как смотреть на конкретные модели, определите, в каком режиме они будут работать. Ошибка большинства команд — сравнивать Claude, Gemini, GPT и модели с открытыми весами в одной корзине, хотя технически это разные классы решений.
- Отдельный API-ассистент. Подходит для генерации текста, анализа документов, внутренних помощников и простых приложений, где данные можно отправлять во внешний контур.
- Модель внутри офисного или продуктового контура. Здесь важны не только качество ответа, но и доступ к почте, файлам, таблицам, календарю, правам и журналам.
- Open-weight или локально развёрнутая модель. Нужна, когда критичны приватность, контроль над инфраструктурой, предсказуемость стоимости и возможность тонкой донастройки.
- Маршрутизация между несколькими моделями. Лучший вариант для продакшна: дешёвая модель обслуживает поток, дорогая забирает трудные случаи, а чувствительные документы идут в локальный контур.
Если вы не ответили на этот вопрос в начале, дальше неизбежно начнутся ложные сравнения. Например, бессмысленно спорить, «что лучше: Claude Sonnet или Llama 4 Scout», пока не ясно, можно ли вообще выносить ваши данные наружу и нужен ли вам собственный инференс.
Перед сравнением качества проверьте доступ и контур данных
Для русскоязычной команды первый отсев часто происходит не по бенчмарку, а по операционной доступности. OpenAI ведёт отдельный список supported countries and territories для API, и на 7 мая 2026 года Россия в нём не перечислена. Anthropic в справке по Claude и Claude API тоже отсылает к спискам supported locations. Google Cloud Vertex AI чаще упирается не в модель как таковую, а в ваш облачный контур, биллинг и правила работы с данными.
Поэтому короткий вопрос «какая модель лучше» на практике быстро распадается на три:
- можем ли мы легально и стабильно покупать этот сервис из нашего контура;
- можно ли отправлять в него документы, код и персональные данные нужного класса;
- не превратится ли рабочий пилот в хрупкую схему с обходами, ручными исключениями и неочевидным риском блокировки.
Если на этом этапе есть жёсткие ограничения, shortlist быстро смещается в сторону локального развёртывания, open-weight семейства или локальных вендоров. Для этого у нас уже есть отдельные разборы ИИ для российских компаний , YandexGPT и GigaChat 2 .
Если вы работаете из российского контура
Для российских команд shortlist часто строится не от бенчмарка, а от закупки, журналирования, правового контура и того, можно ли вообще стабильно купить внешний API. Эту развилку лучше пройти до пилота, а не после него.
| Если у вас ограничение | С чего начинать | Куда идти глубже |
|---|---|---|
| Нужен стек без внешнего API-риска | Сразу проверяйте локальный или гибридный контур, а не пытайтесь приклеить его потом. | Открытые модели vs закрытые API , Ollama: локальный запуск LLM |
| Нужны русскоязычные ответы и локальная закупка | Смотрите локальных вендоров как отдельный shortlist, а не как запасной план на крайний случай. | YandexGPT , GigaChat 2 |
| Нужно объяснить бизнесу, почему внешний API не единственный путь | Считайте ownership модели, а не только цену токена в прайсинге. | ИИ для российских компаний |
Важный практический вывод: для российского контура «лучшая модель на рынке» и «лучшая модель, которую вы реально можете купить и эксплуатировать» часто оказываются разными вещами.
Карта классов моделей в 2026 году
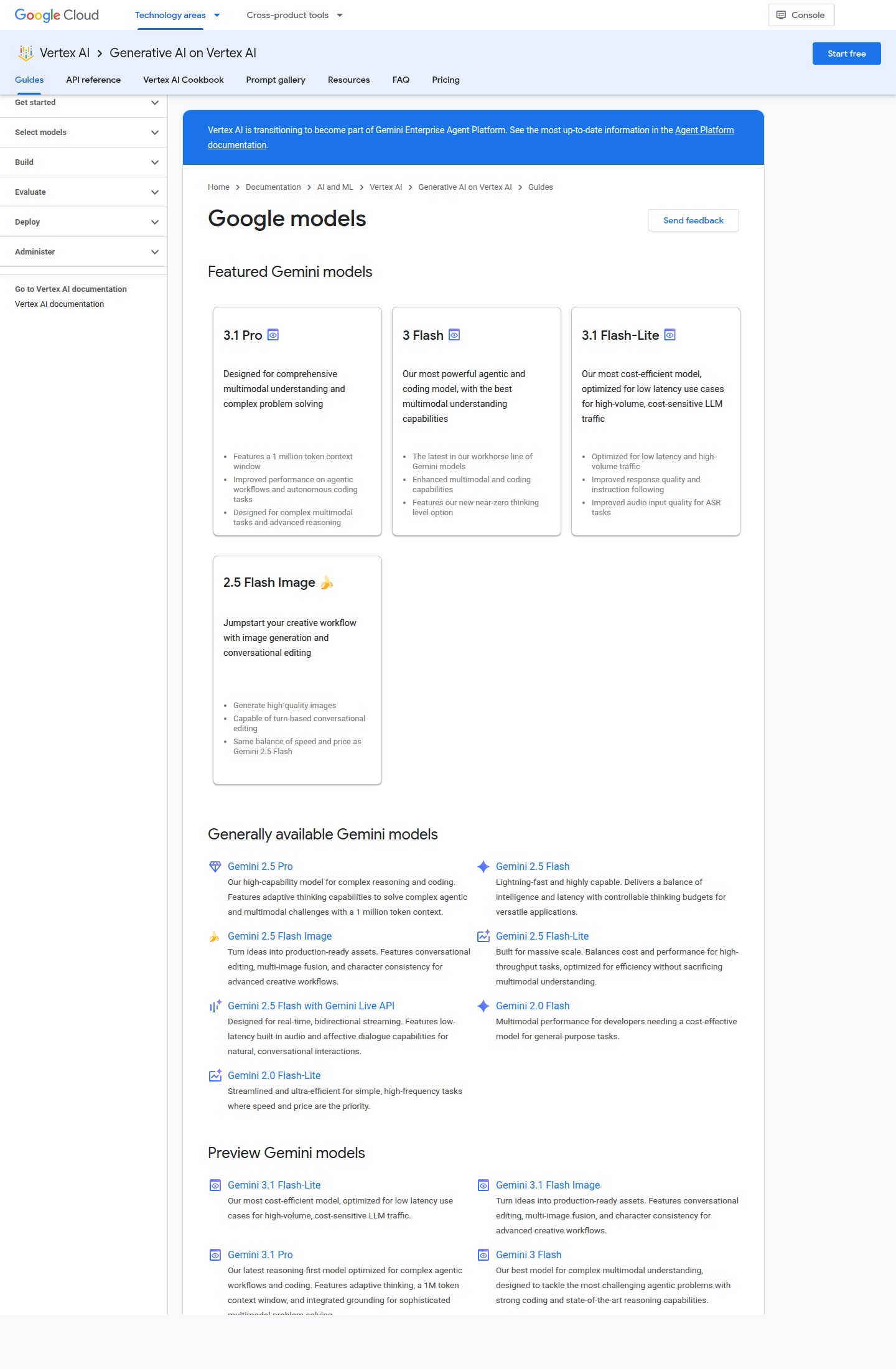
Если разложить рынок по ролям, а не по брендам, картина становится проще. У OpenAI теперь есть явное разделение между новым фронтиром GPT-5.5 и более дешёвым, но всё ещё сильным GPT-5.4. У Anthropic верхний слой держит Opus 4.7, а повседневный продакшн логично смотреть на Sonnet 4.6. У Google preview-ветка уже сместилась к Gemini 3.1 Pro, а для команд, которым нужен спокойный продакшн без preview-риска, опорной линией остаются Gemini 2.5 Pro, Flash и Flash-Lite.
| Роль | Что брать первым | Когда подходит | Главный риск |
|---|---|---|---|
| Фронтир закрытых моделей | GPT-5.5, Claude Opus 4.7, Gemini 3.1 Pro Preview | Сложные агентные и кодовые задачи, дорогая ошибка, длинные цепочки инструментов, высокая ставка на качество с первого прохода | Самая высокая цена; у Google актуальный фронтирный слой пока живёт в preview |
| Рабочая середина закрытых моделей | GPT-5.4, Claude Sonnet 4.6, Gemini 2.5 Pro / Flash | Основной продакшн-поток: документы, RAG, автоматизация, аналитика, стандартная помощь в коде | Именно этот слой чаще всего недооценивают и слишком рано перепрыгивают на дорогой флагман |
| Массовый дешёвый слой | GPT-5.4 mini / nano, Gemini 2.5 Flash-Lite | Классификация, первичная сортировка, предобработка, дешёвые подагенты и массовые однотипные запросы | На длинной логике и небрежном промпте такой слой ломается быстрее всех |
| Модели с открытыми весами | Llama 4, Mistral Small 4, Devstral 2, Qwen3 | Локальный контур, собственный инференс, чувствительные данные, тонкая настройка и предсказуемая себестоимость | Свобода покупается эксплуатацией: инференс, обновления, мониторинг и деградация качества ложатся на вашу команду |
Практический вывод из этой таблицы простой: в 2026 году уже почти бессмысленно выбирать «одну модель для компании». Реальный выбор идёт не между тремя брендами, а между четырьмя ролями: дорогой фронтир, рабочая середина, дешёвый массовый слой и локальный контур. Если команда пытается решить все четыре роли одной моделью, она почти наверняка переплачивает или получает хрупкий продакшн.
Что смотреть первым: качество, задержку или стоимость
Правильный порядок зависит от сценария, но почти всегда работает одно правило: сначала докажите, что задача вообще решается моделью, и только потом оптимизируйте цену. Если начинать с самой дешёвой модели, команда часто принимает слабый результат за «ограничение LLM вообще», хотя на самом деле выбрана не та ступень качества.
После этого порядок такой:
- Качество на вашем наборе. Не на маркетинговом бенчмарке, а на 20-50 реальных примерах.
- Стабильность формата. Если вам нужен JSON, вызов инструментов или извлечение полей, модель должна держать структуру не в одном демо, а серией.
- Латентность. Для чата и интерактивной работы задержка часто важнее ещё 2-3 процентов качества.
- Полная стоимость. Смотрите не только цену токена, но и среднюю длину промпта, число ретраев, долю эскалаций на более дорогую модель и расходы на хранение контекста.
В продакшне модель почти никогда не проигрывает из-за одной цифры в прайсинге. Она проигрывает из-за архитектурной ошибки. Например, дешёвая модель делает плохую первичную сортировку, после чего вы всё равно гоните половину запросов в дорогой флагман и теряете время на повторную обработку.
Бенчмарки полезны, но только в узкой роли
Бенчмарки нужны, чтобы быстро отсеять явно неподходящие классы моделей. Они не нужны, чтобы финально выбрать победителя. Вендоры сами это косвенно признают: официальные страницы сейчас намного чаще говорят о типах задач, работе с инструментами, контексте и задержке, чем о «главном числе» в одном лидерборде.
Что делать на практике:
- Используйте бенчмарки только как первый фильтр: рассуждение, код, многоязычность, длинный контекст.
- Не переносите результат STEM-бенчмарка на поддержку клиентов или RAG по внутренней базе знаний.
- Если вам нужен русский язык, юридический стиль или отраслевой словарь, делайте собственный мини-набор примеров.
- Если модель будет работать с инструментами, тестируйте не только ответ, но и саму дисциплину вызова инструментов.
Удобный минимум — своя короткая матрица проверки.
| Что мерить | Как проверить | Что считается красным флагом |
|---|---|---|
| Фактическая точность | 20 реальных вопросов из вашей области | Уверенные ответы там, где модель должна признать неуверенность |
| Соблюдение формата | Серия JSON / schema / tool tests | Ломает схему на длинных или неоднозначных запросах |
| Латентность | Замер на типичном промпте, а не на игрушечном | Хорошее качество, но неприемлемая задержка для интерфейса |
| Цена запроса | Средний input/output и частота повторных вызовов | Слишком дорогой базовый сценарий даже без ошибок и ретраев |
| Русский язык и терминология | Примеры на ваших документах, письмах, тикетах и коде | Хороша на английском, но начинает упрощать и путать формулировки по-русски |
Когда закрытая модель объективно сильнее
Есть сценарии, где спор между закрытыми моделями и моделями с открытыми весами быстро заканчивается в пользу готового внешнего контура. Это сложный агентный кодинг, длинные документы с инструментами, многошаговое рассуждение, режим computer use и сценарии, где важны управляемые лимиты, логирование, обновления и поддержка провайдера. Здесь выигрывает не только «умнее модель», но и более зрелая платформа вокруг неё.
Но внутри рынка закрытых моделей смотреть надо не на бренд, а на реальную полку цен и статусов моделей.
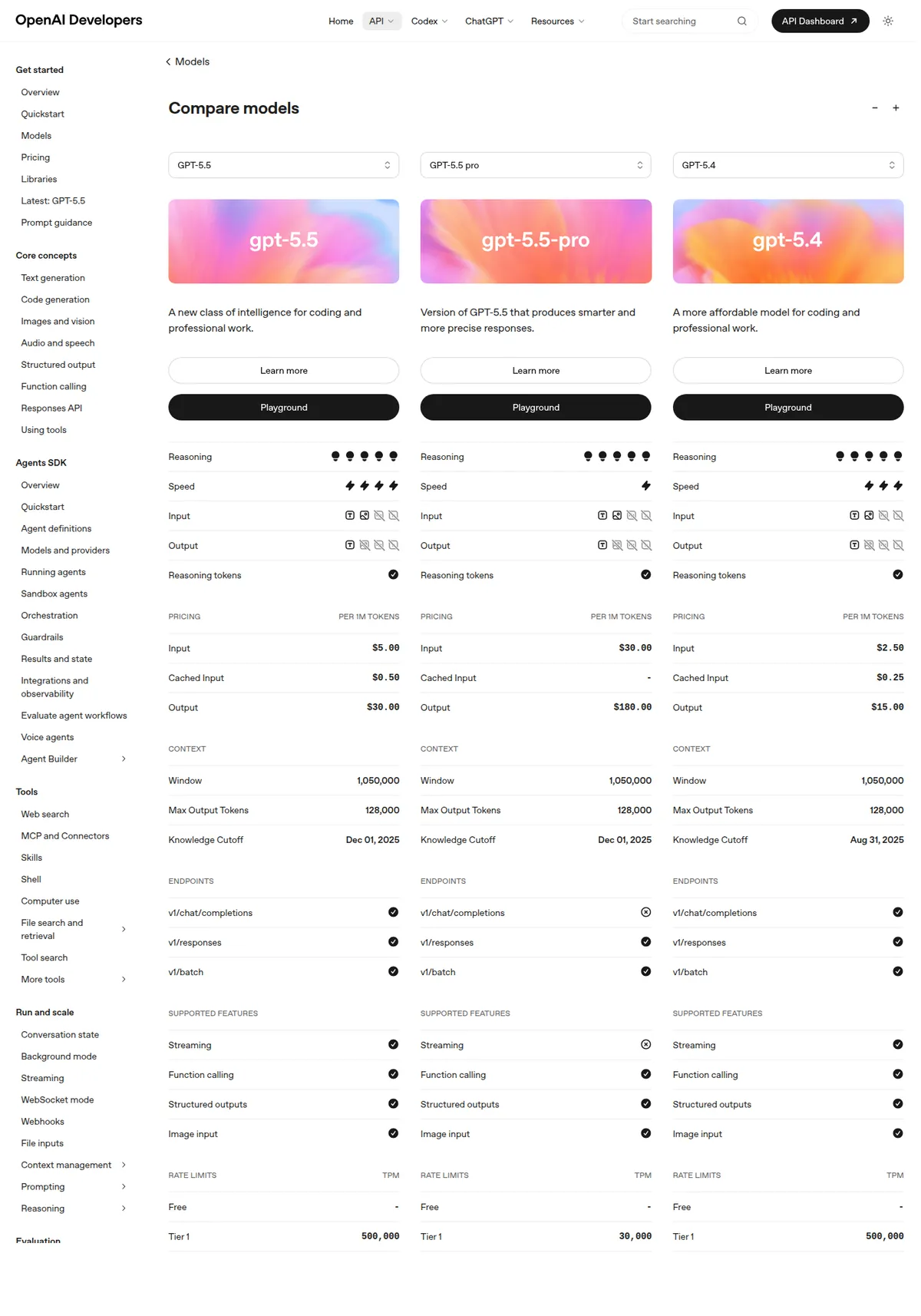
- OpenAI. По официальной документации и прайсингу на 7 мая 2026 года новая опорная модель — GPT-5.5: 1,05 млн контекста и $5/$30 за 1 млн входных и выходных токенов. GPT-5.4 стоит вдвое дешевле — $2,50/$15 при том же контекстном окне. Для массового маршрутизирующего слоя OpenAI держит GPT-5.4 mini за $0,75/$4,50 и GPT-5.4 nano за $0,20/$1,25.
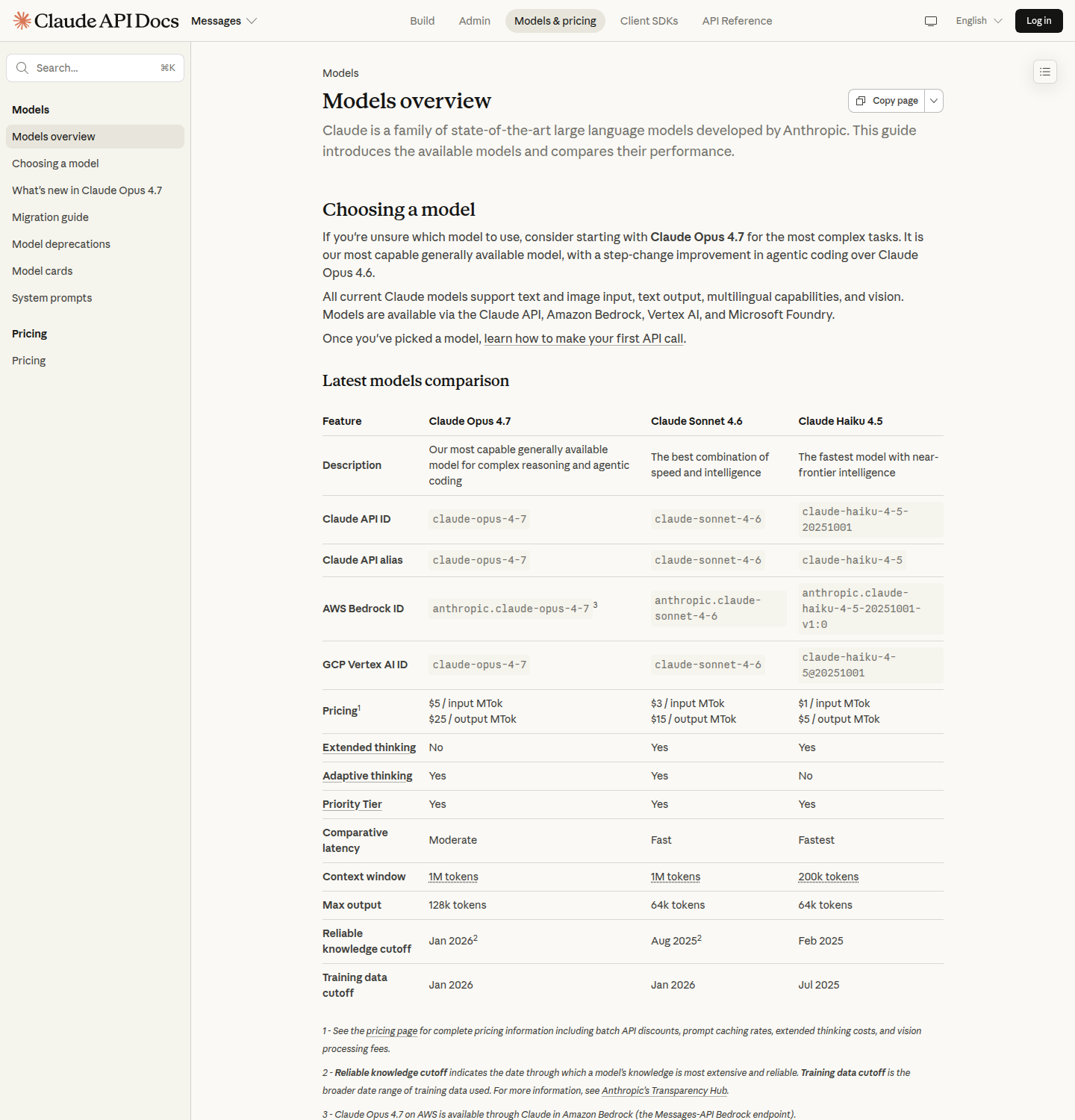
- Anthropic. Claude Opus 4.7 — актуальный верхний слой с ценой $5/$25 за 1 млн токенов. Claude Sonnet 4.6 — рабочая середина, с которой у Anthropic разумно начинать большинство продакшн-задач: $3/$15 за 1 млн токенов.
- Google. Если нужен стабильный GA-слой в Vertex AI, смотрите на Gemini 2.5 Pro, Flash и Flash-Lite: у них у всех входной лимит 1 048 576 токенов, но прайсинг отличается на порядок. По текущей стандартной таблице Vertex AI Gemini 2.5 Pro стоит $1,25/$10 при входе до 200K токенов и $2,50/$15 при более длинном контексте; Gemini 2.5 Flash — $0,30/$2,50; Gemini 2.5 Flash-Lite — $0,10/$0,40. Более свежий frontier-preview у Google теперь называется Gemini 3.1 Pro: `gemini-3-pro-preview` уже снят с обслуживания, и это лишний раз показывает, почему на preview-слое не стоит строить самый спокойный продакшн.
Если перевести это в решение без маркетинга, логика простая: берите новый фронтир только тогда, когда цена ошибки действительно высока. Во всех остальных случаях сначала докажите, что рабочая середина не тянет. Чаще всего она тянет.
Когда модель с открытыми весами лучше, даже если по тесту она слабее
Модель с открытыми весами выигрывает не тогда, когда в среднем даёт лучший ответ в абстрактном тесте, а когда лучше подходит под ограничения задачи. Если данные нельзя отправлять наружу, если важен контроль над задержкой и себестоимостью на больших объёмах, если нужна тонкая адаптация под внутренний словарь или собственный инференс, такая модель часто рациональнее даже при небольшом проигрыше по качеству.
На практике здесь полезно мыслить не абстрактным словом open-weight, а ролями семейств. Llama 4 — это экосистема и длинный мультимодальный контекст. Mistral Small 4 — универсальная открытая модель под общий стек. Devstral 2 — ставка на кодовых агентов и работу с репозиториями. Qwen3 — гибкий набор размеров и быстрый старт через Hugging Face. Если нужен именно этот слой выбора, у нас уже есть отдельный разбор Llama 4, Mistral и Qwen .
Это особенно заметно в трёх сценариях:
- Внутренний RAG по чувствительным документам. Дешевле и спокойнее держать инференс у себя, чем согласовывать внешний контур на каждый тип данных.
- Высокий объём однотипных запросов. При большом трафике предсказуемая стоимость собственного инференса важнее, чем +5 процентов качества на редком бенчмарке.
- Инженерный контроль. Когда команде нужно самостоятельно управлять квантизацией, batching, vLLM, кешированием и модельной маршрутизацией.
Но модели с открытыми весами не дают бесплатный обед. Вы покупаете свободу ценой эксплуатации. Нужны люди, которые умеют поднимать инференс, следить за памятью, версионированием, деградацией качества и обновлениями модели. Если в команде таких людей нет, «дешёвая локальная модель» быстро превращается в дорогую внутреннюю проблему.
Русский язык: проверяйте не на общих фразах, а на своих документах
Почти все большие модели сегодня могут писать по-русски. Это уже не дифференциатор. Дифференциатор начинается на уровне доменного словаря, структуры ответа, работы с длинными русскоязычными документами и стабильности на смешанном русском и английском. Поэтому тест «напиши письмо на русском» больше не показывает почти ничего.
Полезный набор для русскоязычной команды выглядит так:
- 5 реальных писем или тикетов;
- 5 фрагментов документации или договоров;
- 5 примеров с таблицами, числами и терминами;
- 5 примеров кода и комментариев, где русский и английский смешаны.
Если модель хорошо проходит этот набор без дополнительных танцев, у неё есть шанс на продакшн. Если начинает переводить ваши термины на «общечеловеческий» язык, упрощать формулировки или ломать стиль, это уже сигнал. По русскоязычным сценариям полезно сверяться и с нашими материалами про тест моделей на русском и сравнение платных AI-подписок , но финальный ответ всё равно даст только ваш датасет.
Лучшее решение для продакшна — почти всегда маршрутизация
Самый дорогой путь — взять один флагман и прогонять через него весь трафик. Самый нестабильный — попытаться обслужить всё одной дешёвой моделью. Рабочая схема обычно посередине:
- дешёвый слой делает классификацию, первичную сортировку и простые ответы;
- средняя модель обрабатывает основной поток;
- флагман забирает длинные, неоднозначные и рискованные случаи;
- чувствительные данные уходят в локальный контур с моделью с открытыми весами.
Эта схема кажется сложнее только на старте. На практике она дешевле, безопаснее и лучше объясняется бизнесу. Вместо абстрактной покупки «самой умной модели» вы строите систему уровней сервиса: вот дешёвый поток, вот дорогой маршрут, вот закрытый контур. Для инженерной команды это тоже удобнее: проще считать стоимость, видеть узкие места и доказывать, зачем нужно обновление конкретного слоя, а не всей инфраструктуры сразу.
Если вы строите локальный или гибридный стек, рядом полезны наши материалы про развёртывание LLM через vLLM и полный гайд по LLM для разработчиков . Они помогут перевести выбор модели в выбор архитектуры.
Частые ошибки при выборе модели
- Путать качество в демо с качеством в продакшне. Один красивый ответ в демо-интерфейсе почти ничего не значит.
- Смотреть только на цену токена. Полная стоимость определяется ещё и длиной промпта, ретраями, эскалациями и поведением в цепочках инструментов.
- Игнорировать формат вывода. Для агентов и автоматизации это часто важнее общего «качества текста».
- Не закладывать обновления. Модель, которая кажется лучшей сегодня, через месяц может уйти в устаревающий слой или просто перестать быть оптимальной по цене и задержке.
- Забывать про организационный контур. Для части команд решающим фактором становятся не сами ответы, а права доступа, логирование и политика по данным.
Короткий чеклист перед финальным выбором
- Опишите один главный сценарий, ради которого вообще нужен выбор модели.
- Соберите 20-50 реальных примеров, а не демонстрационные промпты.
- Проверьте минимум один флагман, один «рабочий» вариант и один дешёвый слой.
- Если есть чувствительные данные, отдельно протестируйте альтернативу с открытыми весами.
- Посчитайте не цену токена, а среднюю цену полезного ответа.
- Зафиксируйте правило маршрутизации: что идёт на дешёвый слой, что на флагман, что в локальный контур.
Главная мысль проста: модель выбирают не по бренду и не по хайпу недели. Её выбирают по задаче, контуру данных и экономике продакшна. Если держать в голове именно эти три ограничения, выбор становится не проще, но честнее. А честный выбор почти всегда окупается быстрее, чем очередная гонка за «самым умным» названием в модельном списке.
Источники
- OpenAI API Pricing
- OpenAI Developers: Models
- OpenAI Developers: Compare models
- OpenAI Help: supported countries and territories
- Anthropic: Claude Opus 4.7
- Anthropic: Claude Sonnet 4.6
- Claude pricing
- Anthropic: supported countries & regions
- Google Cloud: Agent Platform pricing
- Google Cloud: Gemini 2.5 Pro
- Google Cloud: Gemini 2.5 Flash
- Google Cloud: Gemini 2.5 Flash-Lite
- Google Cloud: Gemini 3 Pro (discontinued preview)
- Google Blog: Gemini 3.1 Pro
- Mistral AI: Mistral Small 4
- Mistral AI: Devstral 2 and Devstral Small 2
- Qwen: Qwen3 launch post
- Qwen3-32B model card
- Meta Llama 4 Scout model card



