Open-source модели в 2026: как выбирать между Llama, Mistral и Qwen
Практическая карта open-source моделей на май 2026 года: Llama 4, Mistral и Qwen3 по лицензиям, контексту и русскоязычным сценариям запуска.
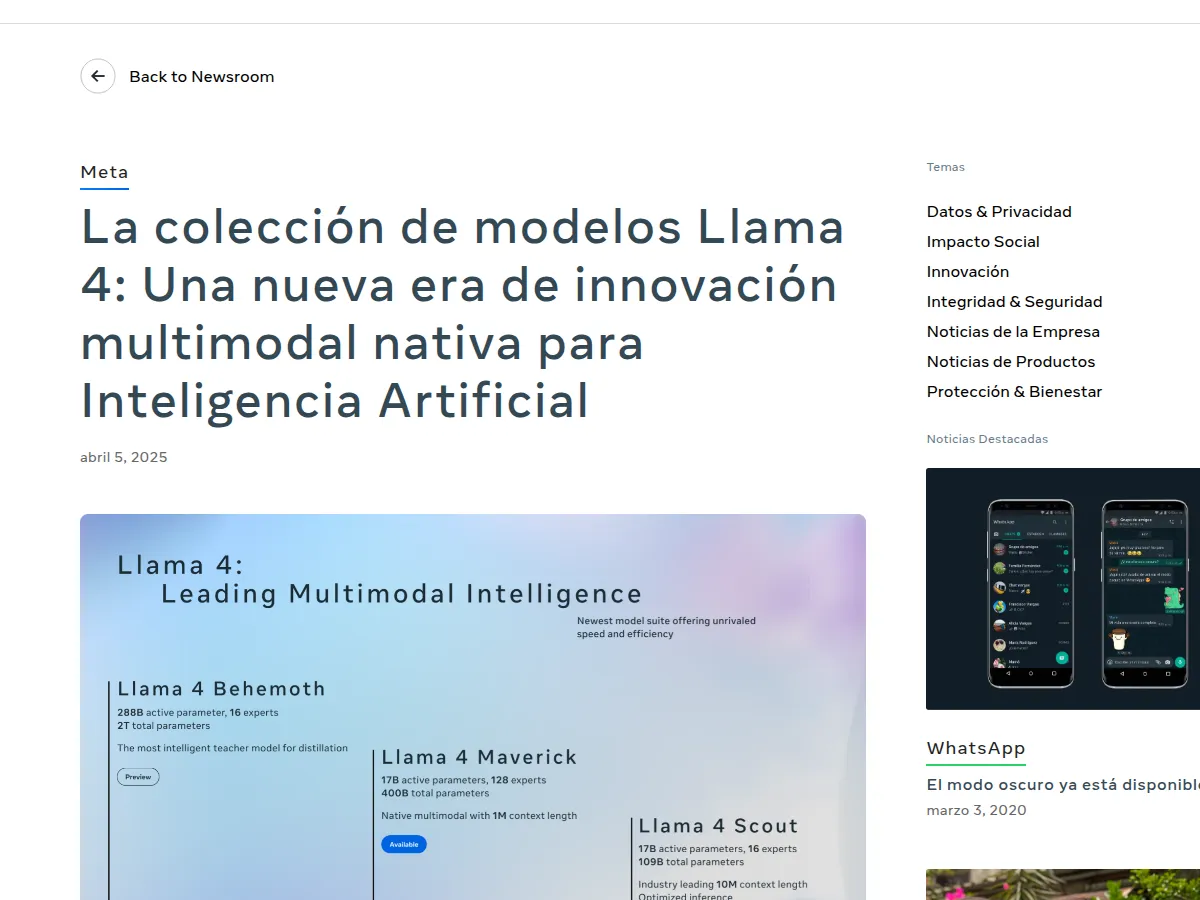
Проверено 7 мая 2026 года. В обиходе Llama, Mistral и Qwen называют open-source моделями, хотя технически рынок точнее описывать словом open-weight: веса доступны, а лицензии, режимы развёртывания и права на использование различаются очень сильно. Для инженера это не спор о словах, а разница между Apache 2.0, modified MIT и кастомной лицензией Meta.
У этой страницы узкая задача: помочь выбрать семейство моделей с открытыми весами внутри одного кластера. Она не отвечает на более широкий вопрос «open-weight или закрытый API вообще» и не заменяет гайд по локальному запуску через Ollama. Если вопрос у вас уже другой, лучше сразу идти в соседний материал, а не пытаться выжать всё из одного обзора.
Куда идти, если у вас уже другой вопрос
| Если вам нужно | Куда идти дальше | Почему это отдельная страница |
|---|---|---|
| Получить широкую карту LLM-рынка | Полный гайд по LLM для разработчиков | Это главный hub по моделям, RAG, агентам, API и типовым архитектурным развилкам. |
| Выбрать модель под задачу, бюджет и контур данных | Как выбрать языковую модель | Это decision-layer по всем классам моделей, а не только по семействам с открытыми весами. |
| Решить, нужен ли вообще open-weight вместо внешнего API | Открытые модели vs закрытые API | Там главный вопрос в ownership-модели, лицензиях, стоимости системы и сервисном слое. |
| Запустить локальную модель у себя | Ollama: локальный запуск LLM | Это уже не обзор рынка, а практический runtime, контекст, VRAM и реальные ограничения железа. |
| Понять, как именно запускать Meta-модели на русском | Llama на русском: с чего начать | Там фокус не на рынке вообще, а на русскоязычном запуске конкретно внутри семейства Llama. |
Если же вопрос у вас именно такой: какое open-weight семейство смотреть первым, то короткая карта на май 2026 года выглядит так.
Короткий выбор: какое семейство смотреть первым
| Семейство | Что подтверждено официально | Когда смотреть первым | Главная оговорка |
|---|---|---|---|
| Llama 4 | Meta выпустила Scout и Maverick как нативно мультимодальные open-weight MoE-модели: у Scout 17B активных параметров, 109B всего и 10M контекста, у Maverick 17B активных, 400B всего и 1M контекста. | Нужны мультимодальность, очень длинный контекст и зрелая экосистема вокруг Llama. | Это не Apache 2.0, а Llama 4 Community License, то есть лицензионный профиль здесь особый. |
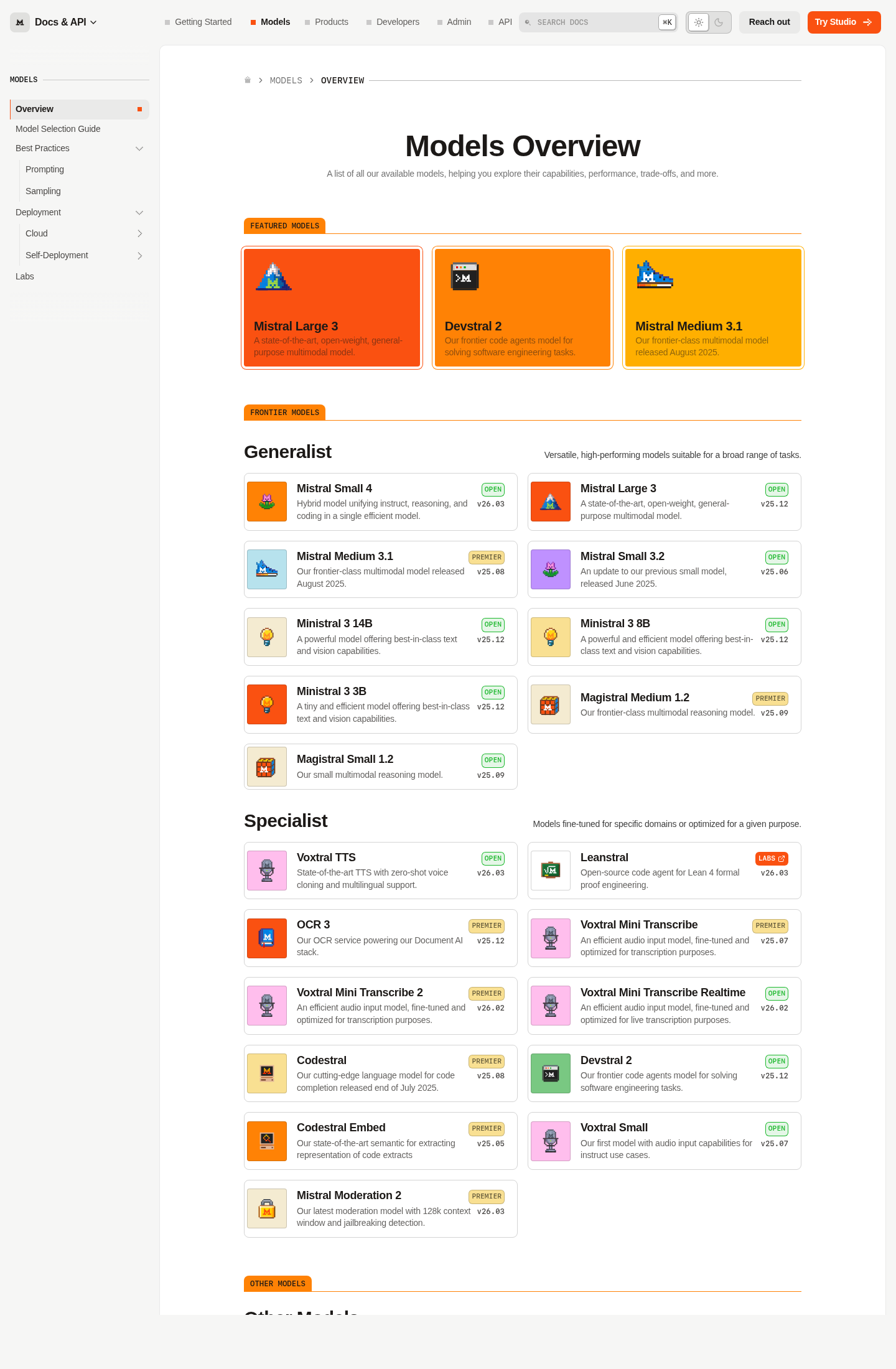
| Mistral | В актуальной линейке Mistral официально разведены Small 4, Medium 3.5 и Devstral 2; при этом Mistral Small 3.2 уже помечена в docs как Legacy/Deprecated с заменой на Small 4. | Нужен более явный выбор внутри одного вендора: универсальная модель, frontier open-вариант или отдельная ветка под кодовых агентов. | Главный риск уже не в бренде, а в выборе конкретной ветки и лицензии внутри семейства. |
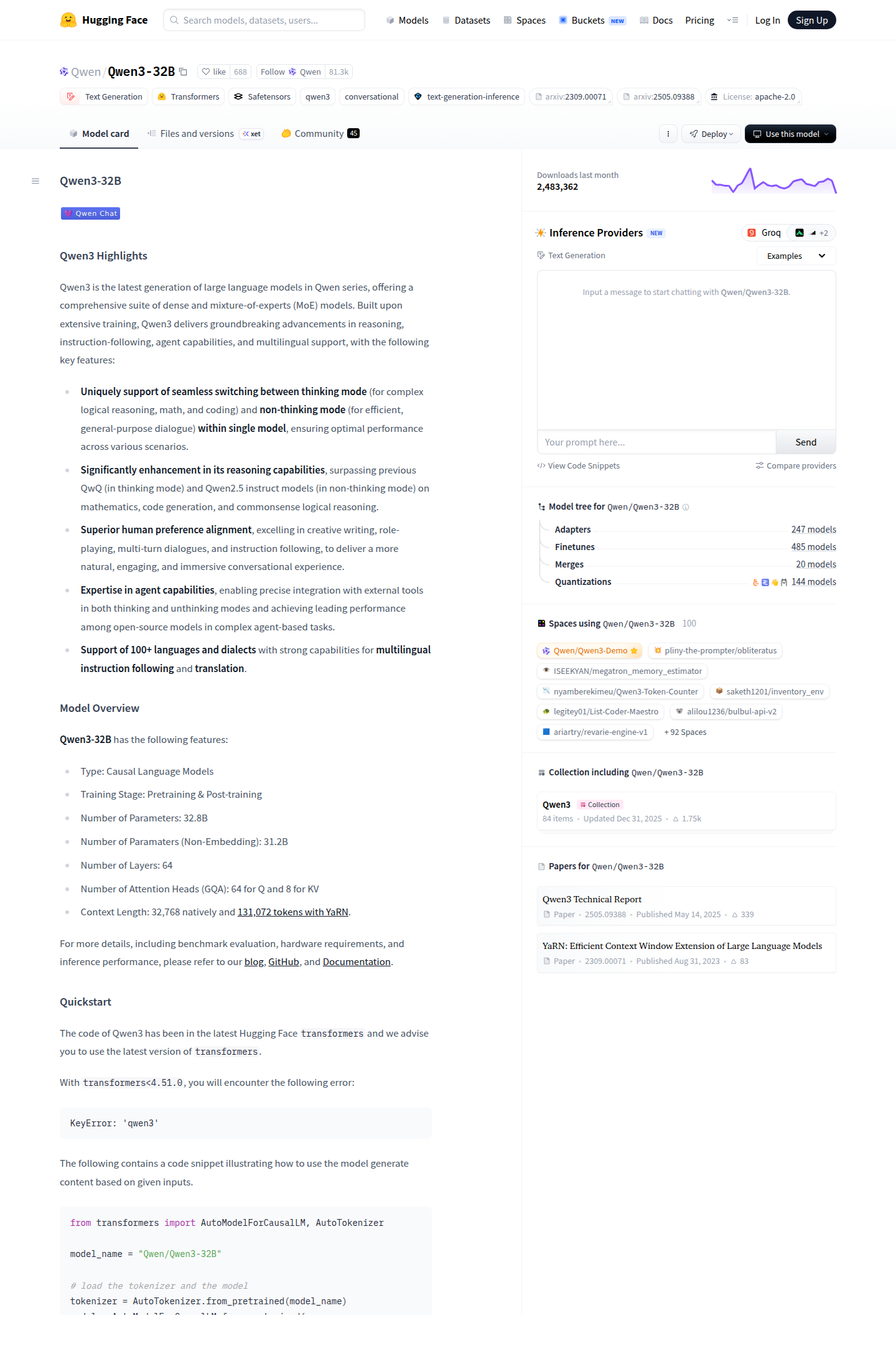
| Qwen3 | Qwen открыла две MoE-модели и шесть dense-моделей; dense-линейка, включая Qwen3-32B, опубликована под Apache 2.0. В launch-посте 32B dense-модель относится к 128K-классу, а карточка Hugging Face даёт 32,768 нативно и 131,072 с YaRN. | Нужен широкий выбор размеров, удобный старт через Hugging Face и возможность быстро перебрать несколько вариантов одного семейства. | Для длинного контекста нельзя брать одну красивую цифру из релизного поста и считать вопрос закрытым. |
Из этой таблицы следует неприятный, но полезный вывод. В 2026 году уже мало сказать «мы смотрим open-source модель». Нужно назвать семейство, релиз, лицензию и режим запуска. Иначе вы обсуждаете не систему, а красивый ярлык.
Llama 4: когда нужен мультимодальный open-weight контур
Семейство Llama 4 стоит смотреть не потому, что вокруг него больше всего шума, а потому, что у него очень чёткая роль. Meta прямо описывает Scout и Maverick как первые нативно мультимодальные open-weight модели компании и одновременно первые модели семейства на MoE-архитектуре. Если вам нужен локальный или свой серверный стек, который умеет работать и с текстом, и с изображениями, Llama 4 почти неизбежно попадает в shortlist.
При этом внутри самой линейки развилка тоже простая. Scout - это более реалистичный рабочий кандидат для длинного контекста и мультимодальных задач. Maverick - уже вариант для команд, которые не считают инфраструктуру побочным вопросом. Разница между 109B total и 400B total - это не косметика, а совсем другой класс развёртывания.
У Llama есть и понятный плюс, которого не видно в сухой таблице: экосистема. Вокруг Meta-моделей быстрее появляются квантовки, контейнеры, рантаймы, примеры и интеграции. Если команде нужен open-weight стандарт, от которого проще оттолкнуться, Llama часто оказывается первой, хотя не всегда лучшей для вашей конкретной задачи.
Но лицензию здесь надо проговаривать заранее. В отличие от Apache-веток у Qwen или части Mistral-линейки, Llama 4 живёт под собственной community license. Поэтому спор «Llama или Qwen» очень быстро становится не только инженерным, но и юридико-операционным.
Если вопрос у вас уже сузился до Meta-стека и русского языка, дальше полезнее читать не этот обзор, а отдельный разбор как запускать Llama на русском и с какой версии начинать.
Mistral: теперь главное различие проходит внутри семейства
Ещё несколько месяцев назад про Mistral легко было писать как про один бренд с несколькими открытыми моделями. На 7 мая 2026 года это уже небрежно. В официальной документации у Mistral есть как минимум три разных open-weight дороги: Small 4 как практичная универсальная модель, Medium 3.5 как более тяжёлый frontier open-вариант и Devstral 2 как специализированная ветка под кодовых агентов.
| Ветка Mistral | Что подтверждено официально | Когда выбирать |
|---|---|---|
| Mistral Small 4 | Docs и официальный анонс описывают Small 4 как open-модель с 119B параметров, 6.5B active, 256k контекстом и лицензией Apache 2.0. | Нужна универсальная открытая модель под чат, код, reasoning и мультимодальный ввод без захода в самый тяжёлый класс. |
| Mistral Medium 3.5 | Официальная карточка модели относит её к open-линейке, даёт 256k контекста и отдельно отмечает выпуск open weights под Modified MIT license. | Нужен более сильный open-вариант для agentic и coding use cases, но вы готовы к более тяжёлой и дорогой модели. |
| Devstral 2 | Официальный анонс называет Devstral 2 123B-моделью с 256K context window под modified MIT; Devstral Small 2 - 24B под Apache 2.0, но в docs уже помечена как deprecated и заменена на Devstral 2. | Приоритет - не универсальный ассистент, а кодовый агент, работа с инструментами и навигация по репозиторию. |
Для редакторского контроля это важная свежая деталь. Если вы всё ещё ориентируетесь по Mistral Small 3.2 как по основной открытой отправной точке, вы уже смотрите на вчерашнюю ветку. В официальном overview она находится в слое Legacy/Deprecated, а replacement указан прямо: Mistral Small 4.
Из всех трёх семейств именно Mistral сейчас сильнее всего наказывает за поверхностный выбор по названию бренда. Внутри одного вендора у вас могут быть Apache 2.0, Modified MIT, универсальная ветка, frontier open-ветка и отдельная линия под код. Формально всё это Mistral. Практически - разные классы решения.
Qwen3: практичное семейство, которое нельзя читать по одной цифре
У Qwen сильная позиция не только потому, что семейство большое, но и потому, что оно быстро доезжает до Hugging Face-экосистемы, локальных рантаймов и понятной обвязки. Для команды, которая хочет быстро проверить несколько вариантов и не тратить неделю на поиск экзотического чекпойнта, это реальное преимущество.
Но именно у Qwen3 полезно помнить, что семейство - это не один продукт. В релизе открыты и две MoE-модели, и шесть dense-моделей. Qwen3-32B хороша как практическая середина: плотная 32B-модель, Apache 2.0, понятная карточка, широкий runtime-след. Qwen3-30B-A3B и Qwen3-235B-A22B - уже другая лига, где разговор быстро уходит в иной класс железа, латентности и стоимости инференса.
Самая важная инженерная оговорка по Qwen3-32B остаётся прежней и на 7 мая 2026 года. В launch-посте эта dense-модель описана как 128K-класс. Но карточка модели на Hugging Face пишет о 32,768 токенах нативно и 131,072 с YaRN. Значит, в проектной документации нельзя просто переписать «128K» в таблицу и считать тему закрытой. Надо зафиксировать конкретный рантайм, конкретную конфигурацию RoPE scaling и конкретный режим теста.
Если нужен короткий практический вывод, он такой. Берите Qwen, когда вам важны широкий выбор размеров, Apache-ветка и быстрый старт через привычную экосистему. Не берите Qwen вслепую только потому, что «семейство в целом сильное»: плотная 32B, маленькая 8B и большая MoE-модель закрывают разные задачи и требуют разного режима запуска.
Что особенно важно русскоязычной команде
Для русскоязычной команды главный риск не в том, что модель «не поймёт русский вообще», а в том, что при хорошем общем впечатлении она провалится именно на вашем рабочем материале: длинных договорах, техподдержке, коде с русскими комментариями, внутренних регламентах или смешанном языке переписки.
| Что проверить | Как проверять | Зачем это делать до выбора семейства |
|---|---|---|
| Русский на ваших данных | Соберите 20-30 реальных примеров: поддержка, документы, письма, код, извлечение полей. | Оценка «русский язык норм» без своих примеров почти всегда обманывает. |
| Лицензия и контур использования | Отдельно согласуйте, нужен ли Apache 2.0, устроит ли modified MIT и допустима ли кастомная лицензия Meta. | Юридический фильтр часто отрезает половину shortlist раньше любого бенчмарка. |
| Длинный контекст в вашем рантайме | Тестируйте не релизный пост, а конкретный стек: Ollama, vLLM, llama.cpp, SGLang или другой сервер. | Одна и та же модель может иметь разные практические пределы в зависимости от конфигурации. |
| Задержку и память | Смотрите не только «влезает ли», но и каков реальный отклик на типичном запросе. | Семейство, которое красиво выглядит в карточке, может убить пилот на стадии эксплуатации. |
Именно поэтому нормальный русскоязычный пилот почти всегда начинается не с вопроса «кто победил в бенчмарке», а с вопроса «какая модель проходит наш короткий набор задач на русском и не ломает инфраструктуру». Если этот шаг пропустить, разговор о семействе превращается в разговор о репутации бренда.
Практический маршрут на один спринт
- Сначала зафиксируйте лицензионный фильтр. Если вам нужна именно permissive-ветка, shortlist сужается сразу.
- Выберите по одному кандидату из двух классов. Например: Llama 4 Scout против Qwen3-32B, или Mistral Small 4 против Qwen3-32B.
- Соберите 20-30 примеров на русском из своей реальной работы: извлечение полей, краткая сводка, правка текста, кусок кода, ответ по документу.
- Прогоните те же примеры в двух рантаймах, если длинный контекст для вас критичен. Особенно это важно для Qwen и других моделей, где есть режимы масштабирования контекста.
- Только после этого решайте, нужен ли вам локальный маршрут через Ollama, более серверный путь и собственный inference, или другой стек вокруг выбранного семейства.
Если же после такого теста выясняется, что вопрос у вас уже не в выборе семейства, а в архитектурном классе решения, не заставляйте эту страницу отвечать за всё сразу. Для этого у нас уже есть отдельный разбор open-weight против закрытых API и отдельный гайд по выбору модели под задачу.
Итог
Если убрать маркетинговый шум, картина на 7 мая 2026 года довольно чёткая. Llama 4 сильна там, где нужен мультимодальный open-weight контур и важна экосистема. Mistral интересна тем, что внутри одного семейства уже есть отдельные дороги для универсальной модели, frontier open-слоя и кодовых агентов, но выбирать приходится аккуратно. Qwen3 остаётся одним из самых практичных стартовых вариантов, если вам важны Apache-лицензия, широкий выбор размеров и быстрая интеграция через Hugging Face.
Лучший выбор здесь редко выглядит как вечная ставка на один бренд. Чаще это вопрос дисциплины: сначала лицензия, потом ваш русскоязычный набор примеров, потом конкретный рантайм, и только после этого название семейства в архитектурной схеме. В таком порядке open-weight перестаёт быть идеологией и становится нормальным инженерным инструментом.
Источники
- Meta: announcement of Llama 4 Scout and Maverick
- Hugging Face: Llama 4 Maverick model card
- Mistral Docs: models overview
- Mistral AI: Introducing Mistral Small 4
- Mistral Docs: Mistral Small 4
- Mistral Docs: Mistral Medium 3.5
- Mistral AI: Devstral 2 and Mistral Vibe CLI
- Qwen: Qwen3 launch post
- Hugging Face: Qwen3-32B model card



