Ollama: как запустить локальную LLM в 2026 году
Практический гайд по Ollama на 7 мая 2026 года: запуск на macOS, Windows и Linux, локальный режим без облака, OpenAI-совместимый API и лимиты VRAM.
Проверено 7 мая 2026 года. Эта страница отвечает на практический вопрос: как запустить Ollama локально на macOS, Windows или Linux, когда нужен именно этот слой запуска, что дают ollama launch, локальный API и OpenAI-совместимый слой, и где заканчивается локальный режим, а начинается облако.
Она не заменяет ни полный гайд по LLM для разработчиков, ни отдельный разбор выбора модели, ни обзор всего локального стека вокруг Ollama, LM Studio и Open WebUI. Но если вам нужен короткий и понятный путь к локальной LLM без лишней романтики, Ollama остаётся сильной стартовой точкой: он быстро поднимает локальный сервер, дружит с привычными SDK и довольно честно показывает, когда вы упёрлись не в промпт, а в VRAM и контекст.
Куда идти, если ваш вопрос уже другой
| Если вам нужно | Куда идти дальше | Почему это отдельная страница |
|---|---|---|
| Получить широкую карту LLM-рынка | Полный гайд по LLM для разработчиков | Это главный обзор по моделям, API, RAG, агентам и типовым архитектурным развилкам, а не узкая инструкция по запуску. |
| Выбрать модель под задачу, бюджет и контур данных | Как выбрать языковую модель | Там главный вопрос в выборе класса модели, а не в запуске Ollama как такового. |
| Сравнить семейства моделей с открытыми весами | Llama, Mistral и Qwen | Это обзор семейств и лицензий, а не страница про локальный запуск и железо. |
| Решить, нужен ли open-weight вместо внешнего API | Открытые модели vs закрытые API | Там основной выбор проходит по модели владения, стоимости системы и политике данных. |
| Получить удобный веб-интерфейс поверх локального сервера | Open WebUI для локальных моделей | Ollama решает запуск и API, а не интерфейсный слой для команды. |
| Разобраться во всём локальном стеке, а не только в Ollama | Ollama, LM Studio и локальный стек целиком | Там фокус шире: маршруты запуска, UI, альтернативные рантаймы и соседние сценарии. |
Что изменилось в Ollama к маю 2026 года
Если вы смотрели на Ollama год назад, продукт стал заметно шире.
- Появился
ollama launch. С января 2026 года команда продвигает Ollama не только как локальный сервер моделей, но и как быстрый слой для Claude Code, OpenCode и Codex без ручной возни с окружением. - OpenAI-совместимость стала практичнее. В официальной документации есть не только старый чатовый контур, но и примеры для
/v1/responsesи vision-сценариев через тот же совместимый слой. - Structured outputs и vision вынесены в отдельные capability-страницы. Это уже не игрушка для локального чата, а рабочий слой для извлечения JSON, обработки изображений и внутренних контуров автоматизации.
- На Apple Silicon идёт MLX preview. Ollama отдельно показывает, что на новых Mac разговор теперь идёт не только о «запустится или нет», но и о том, насколько терпимой будет производительность.
Поэтому в 2026 году Ollama стоит оценивать не как утилиту для одной Llama на ноутбуке, а как локальный или гибридный слой запуска, который всё чаще живёт рядом с инструментами разработчика.
Когда Ollama действительно нужен
Есть три сценария, где Ollama почти всегда оправдан.
- Вы не хотите отправлять данные во внешний API и готовы принять, что локальная модель может быть слабее крупного облачного аналога.
- Вам нужен локальный сервер для редактора, RAG, CLI-инструмента, небольшого внутреннего сервиса или быстрого пилота без отдельной инфраструктурной команды.
- Вы хотите быстро переключаться между моделями и не строить свой контур инференса с нуля.
Если ни один из этих пунктов не про вас, локальный запуск может оказаться лишней сложностью. Самая частая ошибка здесь простая: брать локальную 7B- или 8B-модель под задачу, где вы на самом деле ждёте качество и устойчивость большой облачной reasoning-модели.
Для русскоязычных команд у Ollama есть и ещё один понятный плюс. Его часто выбирают не из любви к развёртыванию «у себя» как идеологии, а потому, что так проще держать чувствительные данные внутри своего контура и не превращать каждую интеграцию с внешним API в отдельную операционную историю. Но и здесь важно не путать режимы. Если вам нужен полностью локальный запуск без веб-поиска и без обращения к облаку Ollama, это надо фиксировать явно: через disable_ollama_cloud в ~/.ollama/server.json или через переменную OLLAMA_NO_CLOUD=1.
Какой путь запуска выбирать
| Режим | Когда выбирать | Главная оговорка |
|---|---|---|
ollama или ollama run |
Нужно быстро запустить модель вручную, проверить поведение и не думать про SDK. | Это хороший старт для проверки, но не полноценный ответ на вопрос о продакшн-интеграции. |
Локальный REST API на http://localhost:11434 |
Вы пишете свой сервис, простой RAG, внутренний бот или сценарий автоматизации. | Надо заранее понимать, какая модель и какой контекст реально держатся на вашем железе. |
OpenAI-совместимый слой на /v1 |
У вас уже есть клиент под OpenAI SDK, и нужно быстро подменить backend на локальный. | Совместимость упрощает миграцию, но не обещает паритет по качеству и всем возможностям. |
ollama launch |
Сценарий сразу связан с coding tools, и вы не хотите руками собирать переменные окружения и конфиги. | Это удобно для старта, но не отменяет требований к VRAM и длине контекста. |
| Cloud models в Ollama | Локального GPU не хватает, но хочется остаться в том же стеке и API-модели. | Это уже не полностью локальный режим: ollama.com работает как удалённый хост, а часть возможностей локального контура отличается. |
Что проверить до первого запуска
| Что проверить | Что подтверждено в docs | Почему это важно |
|---|---|---|
| macOS | Ollama требует macOS Sonoma 14 или новее; Apple M-series поддерживаются с CPU и GPU, x86 работает только на CPU. | Это сразу отсекает ложное ожидание, что старый Intel Mac даст тот же опыт, что и новый MacBook на Apple Silicon. |
| Windows | Официальная страница Windows указывает Windows 10 22H2 или новее и нативное приложение с поддержкой NVIDIA и AMD Radeon. | Если у команды Windows-машины, здесь нет нужды выдумывать обходной Linux-контур для простого старта. |
| Linux | Официальный install script остаётся базовым путём установки; для серверного режима docs отдельно показывают systemd-сервис. | Это удобный путь для локального сервера и домашней лаборатории, но его стоит сразу отличать от серьёзного серверного стека уровня vLLM. |
| Сеть и полностью локальный режим | По умолчанию Ollama слушает 127.0.0.1:11434; для сети используется OLLAMA_HOST, для полного отключения облака - OLLAMA_NO_CLOUD=1. |
Именно здесь чаще всего ломаются коллективные пилоты: команда думает, что подняла локальный сервер для всех, а сервис по факту виден только с одной машины. |
На Linux базовый старт по-прежнему укладывается в одну команду:
curl -fsSL https://ollama.com/install.sh | shПосле установки документация предлагает не вспоминать список флагов наизусть, а просто открыть интерактивное меню:
ollamaДля локального API минимальный пример всё так же короткий:
curl http://localhost:11434/api/chat -d '{
"model": "gemma3",
"messages": [{ "role": "user", "content": "Hello!" }]
}'Где полезна совместимость с OpenAI API
Один из самых практичных плюсов нынешнего Ollama - не просто «есть похожий endpoint», а официальная страница OpenAI compatibility с рабочими примерами. Документация показывает подключение через base_url='http://localhost:11434/v1/', а api_key='ollama' указывается как обязательный, но игнорируемый. Это полезно, когда у команды уже есть редактор, скрипт или внутренний сервис, заточенный под OpenAI SDK, и вы хотите быстро подменить backend на локальный.
Важно и то, что совместимость в 2026 году не ограничивается старым чатовым контуром. В документации Ollama есть отдельный пример для /v1/responses, а рядом - vision-сценарий через /v1/chat/completions. Для интеграций это означает мягкий переход: не всё придётся переписывать, если вы тестируете локальный запуск рядом с привычным OpenAI-клиентом.
Но не стоит делать из этого неверный вывод. Совместимость с частями OpenAI API - это способ быстро подменить слой доступа к модели. Это не обещание полного паритета по качеству, задержке и поведению конкретных моделей.
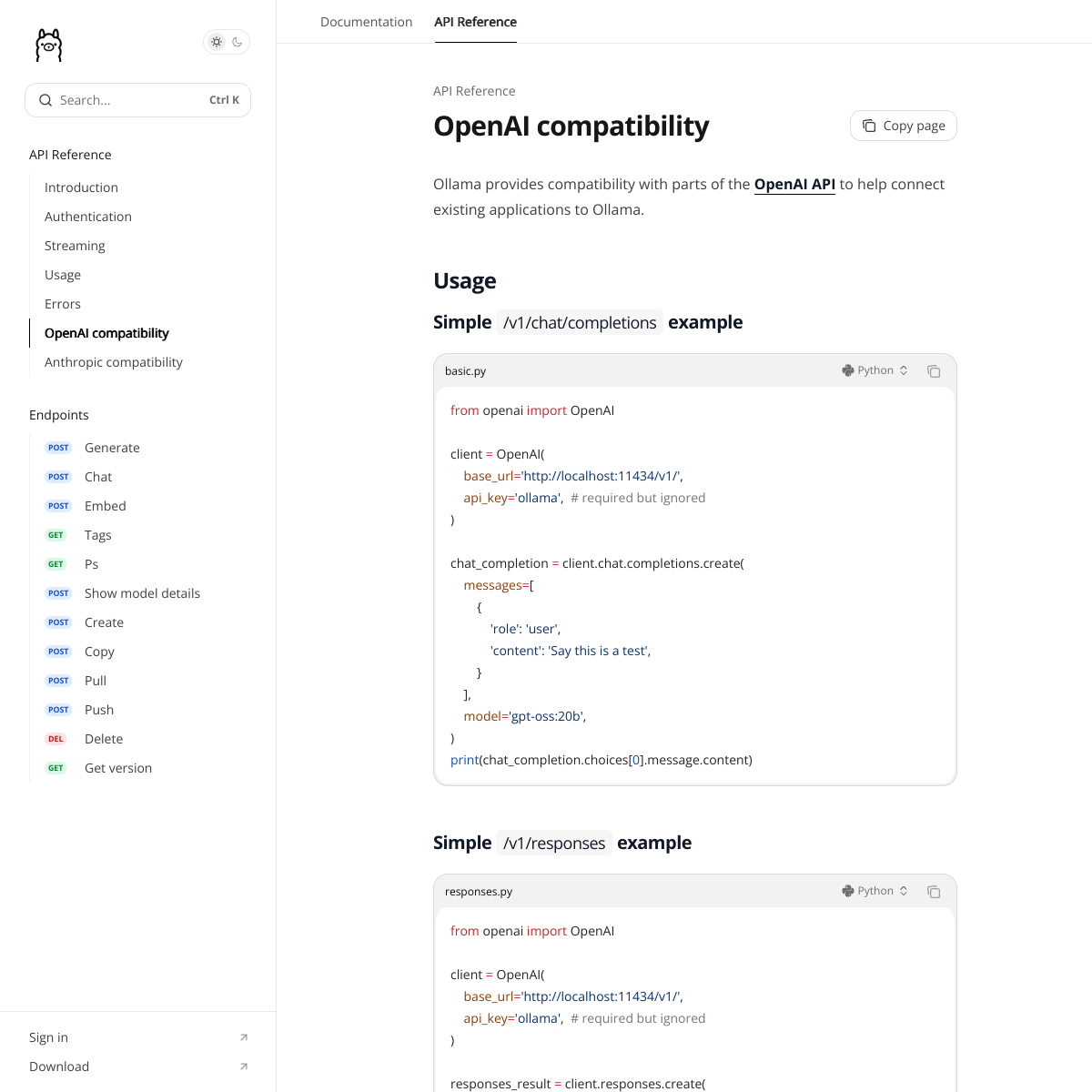
/v1/responses, и vision-примеры через OpenAI-совместимый слой. Источник: Ollama Docs.Structured outputs и vision: где польза, где ловушка
У Ollama уже есть отдельные capability-страницы и для vision, и для structured outputs. Это важный сдвиг: локальная модель нужна не только для чата, но и для задач, где ответ должен вернуться в JSON-схеме, а не в свободном тексте. Для внутренних классификаторов, extraction-пайплайнов и простых агентных контуров это часто полезнее, чем ещё один красивый демо-чат.
Но здесь есть ловушка, о которую команды регулярно спотыкаются при переходе с локального пилота на гибридный режим. В официальной документации Ollama прямо указано, что Ollama Cloud сейчас не поддерживает structured outputs. Значит, сценарий «локально схема работает, потом просто переносим всё в cloud» не всегда пройдёт без изменений.
С vision картина проще: API принимает изображения вместе с текстом, а SDK могут работать с путями, URL или байтами. Это делает Ollama удобным локальным слоем для задач вроде описания скриншотов, классификации картинок и полуформального OCR, когда данные нежелательно выносить в сторонний API.
Что нужно знать про железо, прежде чем ругать результат
У Ollama есть сильная инженерная привычка: документация не прячет аппаратные ограничения под ковёр. На странице Context length прямо показано, как связаны доступная VRAM, длина контекста и рабочий режим модели. Это полезнее почти любого маркетингового обещания.
| Что пишет документация | Что это значит на практике |
|---|---|
| Меньше 24 GiB VRAM - 4k контекста по умолчанию | Для coding, agents и длинных рабочих сессий этого почти всегда мало. |
| 24-48 GiB VRAM - 32k контекста | Это уже рабочий режим для части боевых пилотов, но не для всего подряд. |
| 48 GiB VRAM и выше - 256k контекста | Длинный контекст становится реалистичным, но это уже другой класс железа. |
| Для web search, agents и coding tools рекомендованы минимум 64000 токенов | Если вы тестируете кодового агента на дефолтных 4k, вы проверяете не модель, а заведомо урезанный режим. |
ollama ps показывает колонку PROCESSOR |
Это самый дешёвый способ проверить, сидит ли модель на GPU, CPU или в смешанном режиме. |
Именно поэтому локальный coding-агент на ноутбуке часто разочаровывает не из-за «плохого промпта», а из-за короткого контекста, частичного ухода на CPU или банальной нехватки VRAM. Тут важна не идеология локальности, а дисциплина измерений.
С поддержкой GPU формулировки тоже достаточно конкретны. На странице hardware support Ollama пишет про NVIDIA с compute capability 5.0+ и driver version 531+, а для AMD на Linux отдельно указывает ROCm v7. Это полезный индикатор зрелости: продукт сразу объясняет, где проходит граница между «должно завестись» и «будет нормально работать».
Когда использовать Modelfile
Многие останавливаются на ollama run, хотя реальная ценность начинается чуть дальше. В документации Modelfile описан как blueprint для создания и распространения кастомных моделей в Ollama. На практике это значит, что вы можете закрепить системные инструкции, параметры, шаблон, адаптеры и даже минимальную требуемую версию Ollama.
Для внутренней команды это часто удобнее, чем держать критичные настройки в README, shell-скриптах и памятках в чате. Если локальный ассистент должен вести себя одинаково у поддержки, аналитиков и разработчиков, Modelfile даёт повторяемость. Не «у меня на ноутбуке было похоже», а воспроизводимый конфиг.
Матрица выбора: где Ollama хорош, а где нет
| Сценарий | Насколько подходит Ollama | Почему |
|---|---|---|
| Локальный прототип, приватные документы, внутренний RAG | Высоко | Низкий порог запуска, локальный API и понятный контроль над тем, куда уходят данные. |
| Подмена облачного backend в редакторе или внутреннем инструменте | Высоко | Помогает OpenAI-совместимый слой и возможность не переписывать всё окружение с нуля. |
| Структурированное извлечение и vision на локальных данных | Средне или высоко | Сценарий рабочий, если схема и модель подобраны заранее, но облачный режим уже требует дополнительных оговорок. |
| Долгие coding-сессии на слабом ноутбуке | Средне или плохо | Ограничения по VRAM и контексту упираются раньше, чем заканчиваются идеи для промпта. |
| Полная замена сильных облачных reasoning-моделей | Плохо | Ollama решает приватность и контроль, но не стирает разницу между локальной и большой облачной моделью. |
Типичные ошибки
- Берут слишком большую модель под слабое железо. В итоге модель уходит в CPU или смешанный режим, а виноватым почему-то объявляют промпт.
- Оставляют короткий контекст для coding и agent-задач. Для длинной рабочей сессии 4k или 8k почти всегда мало.
- Не проверяют
ollama ps. Без этого легко спорить о качестве модели, не понимая, где она вообще работает. - Путают локальный и облачный режимы. Если пилот держался на предпосылке «всё остаётся локально», потом нельзя молча унести его в облако и ждать идентичного поведения.
- Забывают про ограничения structured outputs. На локальном сервере JSON-схемы работают, а в Ollama Cloud - пока нет.
Вывод
Ollama в мае 2026 года - это уже не просто способ локально дёрнуть одну модель. Это удобный слой запуска, интеграции и частичной стандартизации локального LLM-контура: с quickstart, OpenAI-совместимым API, ollama launch, Modelfile, vision и structured outputs.
Относиться к нему лучше без романтики. Берите Ollama там, где приватность, локальный доступ и контроль над стеком действительно важнее максимального качества модели. Не пытайтесь делать из него универсальную замену облака. Тогда это сильный инструмент. И довольно честный.
Источники и дата проверки
Факты по установке, поддерживаемым платформам, OpenAI-совместимости, облачному режиму, context length, structured outputs, vision, MLX preview и полностью локальной настройке перепроверены 7 мая 2026 года по официальным страницам Ollama.
- Ollama Docs - стартовая карта продукта, quickstart, cloud и API reference.
- Quickstart - установка, команда
ollama, базовый локальный API и старт через меню. - Linux - install script, ручная установка и server-mode через systemd.
- macOS - системные требования для Apple Silicon и x86.
- Windows - требования к Windows 10 22H2+ и нативное приложение.
- Cloud - cloud models, удалённый хост и
OLLAMA_API_KEY. - OpenAI compatibility - совместимость с
/v1/chat/completions,/v1/responsesи vision-примеры. - Structured Outputs - JSON schema, validation и текущее ограничение Ollama Cloud.
- Vision - работа с изображениями через API и SDK.
- Modelfile Reference - создание и распространение кастомных моделей.
- Context length - связь VRAM и дефолтного контекста, рекомендации для coding tools и проверка через
ollama ps. - FAQ - поведение в полностью локальном режиме,
OLLAMA_NO_CLOUDиOLLAMA_HOST. - Hardware support - поддержка NVIDIA и AMD, driver / ROCm требования.
- Blog: ollama launch - запуск coding tools через отдельную команду.
- Blog: MLX on Apple Silicon - ускорение на новых Mac через MLX preview.