LLM: полный гайд по большим языковым моделям для разработчиков
Главная страница кластера LLM для разработчиков: карта темы, выбор подхода, облачный API, open-source, RAG, prompt engineering и типичные сбои в продакшне.
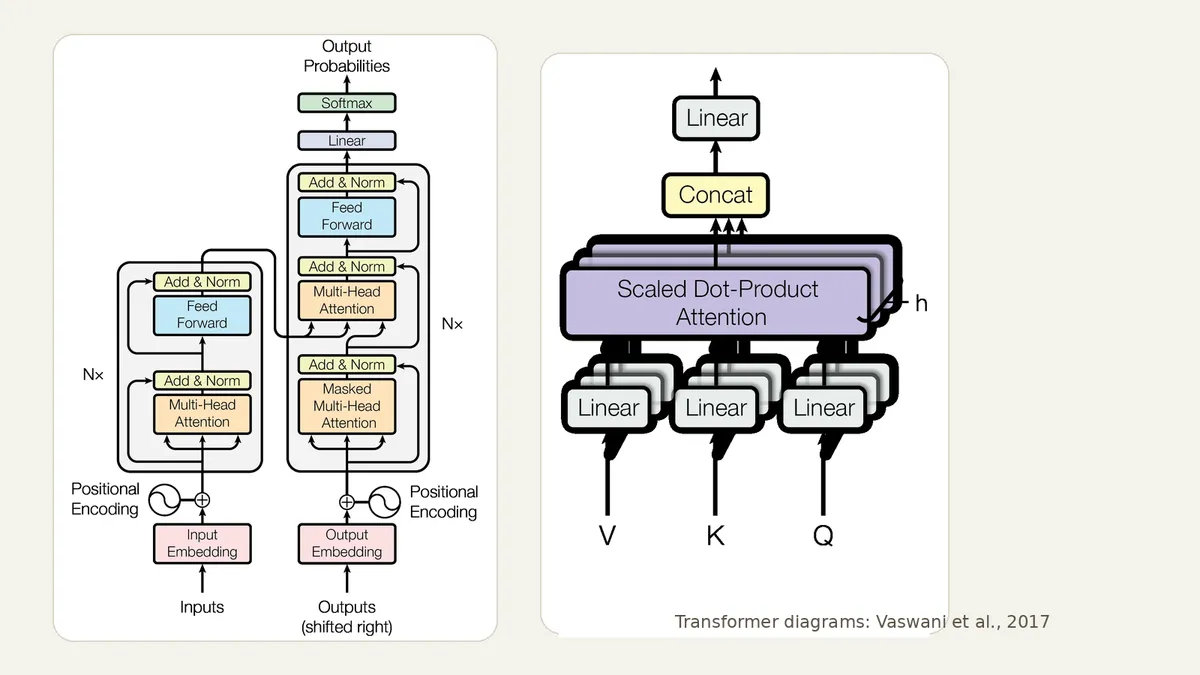
Проверено 26 апреля 2026 года. Эта страница — главная точка входа в кластер LLM на Toolarium. Здесь мы не пытаемся держать в одном тексте все текущие названия моделей, тарифы и лимиты контекста: такие детали меняются слишком быстро. Вместо этого здесь собрана рабочая карта темы для разработчика: что такое большие языковые модели, как выбрать подход под задачу, когда достаточно облачного API, когда нужен open-source стек, где начинается RAG и почему без оценочного набора проект быстро теряет управляемость.
Если вам нужен базовый вход в тему без инженерных деталей, начните со статьи «Что такое LLM: как работают большие языковые модели». Если вы уже строите продукт, используйте этот материал как точку входа в кластер: отсюда удобно перейти в выбор модели, API, open-source инфраструктуру, RAG, prompt engineering и разбор типичных сбоев.
Карта кластера LLM
Ниже — короткая навигация по соседним интентам. Она нужна, чтобы не смешивать в одной статье выбор модели, RAG, локальный запуск и безопасность.
| Если вам нужно | Куда идти дальше | Зачем открывать |
|---|---|---|
| Выбрать модель под бюджет, язык и задержку | Как выбрать языковую модель | Практическая матрица выбора без мифа про одну «лучшую» модель. |
| Сравнить сильные стороны GPT, Claude и Gemini на русском | GPT, Claude и Gemini — тест на русском | Полезно, когда важны качество ответа, стиль и работа с русскоязычным контентом. |
| Понять open-source слой и локальный запуск | Open-source модели: Llama, Mistral, Qwen, как развернуть LLM-сервер на vLLM | Нужно, если важны контроль над инфраструктурой, приватность или стоимость на большом объёме. |
| Собрать ответы по свежим документам и базе знаний | RAG: Retrieval-Augmented Generation — полный гайд | RAG нужен, когда «памяти модели» уже недостаточно и нужен источник истины вне промпта. |
| Писать запросы стабильнее и дешевле | Prompt engineering: как писать запросы к LLM | Помогает уменьшить шум, сократить расход токенов и улучшить формат ответа без лишнего шаманства. |
| Разобрать риски и слабые места LLM | психотические диалоги LLM, N-Day Bench и уязвимости LLM | Это полезнее любой рекламной презентации, если вы проектируете продакшн-систему. |
Как устроены большие языковые модели
LLM — это нейросеть, которая получает текст в виде токенов и шаг за шагом предсказывает следующий токен по контексту. На этом механизме держатся и чат-интерфейсы, и помощники в коде, и многие агентные системы. Снаружи это выглядит как «понимание», но на практике перед нами вероятностная модель, усиленная дообучением на инструкциях, системными ограничениями и внешними инструментами.
Фундамент современной волны LLM — архитектура Transformer из статьи Attention Is All You Need. Именно она дала индустрии масштабируемый способ работать с длинными последовательностями и параллельно обучать модели на огромных корпусах текста и кода. Если нужен совсем базовый разбор терминов, рядом есть словарь терминов LLM; здесь важнее инженерный вывод: LLM сильна там, где нужно сжать, переписать, объяснить, сопоставить или сгенерировать текст по контексту, но она не заменяет поиск, базу данных и проверяемый вычислитель.
| Слой системы | За что отвечает | Что лучше не перекладывать на него |
|---|---|---|
| LLM | Генерация, переформулировка, суммаризация, извлечение структуры из текста, работа с кодом. | Хранение фактов, проверку актуальности, точные вычисления и право на окончательное решение. |
| Поиск или RAG | Доставка свежих и проверяемых документов в контекст модели. | Саму генерацию ответа без языкового слоя поверх найденных данных. |
| Код, API, бизнес-логика | Проверяемые операции: расчёты, статусы заказов, права доступа, запись данных. | Свободное достраивание ответа «по памяти модели». |
В инженерной практике это важнее красивых демо. Как только команда начинает использовать LLM вместо поиска или вместо системы правил, растёт число уверенных, но неверных ответов. Отсюда и главный принцип: модель должна отвечать за язык, а не за истину в одиночку.
Как выбрать архитектуру под задачу
Вопрос почти никогда не звучит как «какая модель лучшая». Полезный вопрос другой: какой стек решит вашу задачу с нужным качеством, ценой, задержкой и уровнем контроля.
| Подход | Когда выбирать | Главный компромисс |
|---|---|---|
| Облачный API | Нужно быстро запустить прототип, проверить гипотезу и не поднимать собственную инфраструктуру. | Меньше контроля над моделью и ценой на масштабе, выше зависимость от вендора. |
| Open-source модель | Важны приватность, контроль над стеком, кастомные лимиты или экономия на больших объёмах. | Придётся заниматься инференсом, обновлениями, мониторингом и качеством самостоятельно. |
| RAG поверх модели | Нужны ответы по внутренней базе знаний, документации, логам или быстро меняющимся данным. | Качество зависит не только от модели, но и от поиска, чанкинга, цитирования и оценки выдачи. |
| Fine-tuning | Повторяется один и тот же стиль или формат ответа, а длинный промпт уже не спасает. | Нужен чистый датасет, режим переобучения и дисциплина оценок; это не замена RAG. |
| Агентный слой | Модель должна не только отвечать, но и делать: искать, читать файлы, писать код, ходить в API. | Резко растёт риск лишних действий, ошибок инструментов и скрытой стоимости каждого шага. |
Отдельный вопрос — выбор конкретной модели внутри этого стека. Для этого есть отдельный гайд по выбору языковой модели, а для сравнения качества на русском — сравнение GPT, Claude и Gemini. В этой странице важнее другое: не покупать сложность раньше времени. Большинству команд сначала хватает облачного API и маленького оценочного набора. Open-source, собственный инференс и fine-tuning нужны позже, когда появляется понятный повторяемый объём и ограничение, которое нельзя обойти промптом или поиском.
Рабочий маршрут разработчика: от API к продакшну
Типичная траектория выглядит так.
- Сначала команда берёт облачный API и проверяет задачу на небольшом, но реальном оценочном наборе. Без этого обсуждать «какую модель брать» бессмысленно.
- Потом появляются требования к формату, цитатам, отказам и защите от галлюцинаций. Здесь уже нужен нормальный промпт-дизайн и явные проверки на выходе. Для этого полезен материал про prompt engineering.
- Когда задача упирается в свежие документы и внутренние данные, к модели добавляют поиск и RAG. Именно в этот момент становится видно, где у команды слабое звено: retrieval, чанкинг, ранжирование или сама модель. Подробности — в большом гайде по RAG.
- Если растёт нагрузка или нужно больше контроля, команда смотрит в сторону open-source моделей и собственного инференса. Дальше уже полезны обзор open-source моделей и инструкция, как развернуть LLM-сервер на vLLM.
- Отдельно решается вопрос API-обвязки. Если вы пишете интеграцию под конкретного вендора, переходите в гайд по OpenAI API на Python или в руководство по Claude API.
Это выглядит приземлённо, но в этом и смысл. LLM-проект обычно проваливается не потому, что команда не знала модный термин, а потому что она слишком рано прыгнула в сложную архитектуру без простого измерения качества на своей задаче.
Где проекты с LLM ломаются
У большинства неудачных внедрений повторяется один и тот же набор ошибок.
- Моделью пытаются заменить источник истины. В результате чат красиво формулирует ответ, но опирается не на документы, а на вероятностную догадку.
- Команда меряет «вау-эффект» на демо, но не собирает собственный оценочный набор из реальных кейсов. Через месяц никто уже не может доказать, стало лучше или хуже.
- В промпт тащат весь доступный контекст. Цена и задержка растут, а качество не обязательно растёт вместе с ними.
- Безопасность и злоупотребления считают второстепенной задачей. На практике это значит инъекции в промпт, утечки через инструменты и неверные действия агента.
- Маршрутизацию по моделям и резервный сценарий оставляют «на потом». Потом оказывается, что даже простой запрос идёт через дорогой путь.
Если нужна не теория, а примеры того, как LLM дают сбой, посмотрите наш разбор психотических диалогов LLM и материал про N-Day Bench и уязвимости LLM. Для разработчика это полезнее очередной маркетинговой презентации про «революцию ИИ».
Что читать дальше по кластеру LLM
Если использовать эту страницу как карту, удобно идти по одному из четырёх маршрутов.
1. Выбор и сравнение моделей
- Как выбрать языковую модель
- GPT, Claude и Gemini — тест на русском
- Модели рассуждения: o3 и DeepSeek-R1
2. Open-source и инфраструктура
- Open-source модели: Llama, Mistral, Qwen
- Ollama: запуск LLM локально
- Как развернуть LLM-сервер на vLLM
3. Прикладной стек вокруг модели
- RAG: Retrieval-Augmented Generation — полный гайд
- Prompt engineering: как писать запросы к LLM
- ChatGPT API на Python: гайд для разработчиков
- Claude API: руководство для разработчиков
4. Ограничения и риски
Что перепроверять вручную и где брать первоисточник
Есть два слоя фактов. Базовая механика меняется медленно: Transformer, токены, instruction tuning, RAG как паттерн, ограничения вероятностной генерации. Их удобно сверять по первоисточникам вроде Attention Is All You Need, GPT-3, InstructGPT и RAG.
Продуктовые детали меняются быстро. Если вам нужны актуальные цены, лимиты контекста, поддержка режимов и названия текущих линеек, проверяйте официальные страницы вендоров перед любым техническим решением: OpenAI Models, OpenAI Pricing, Anthropic Models, Anthropic API Pricing, Gemini API Models.
Главная мысль простая: LLM — это не одна «магическая модель», а слой в системе. Когда вы держите отдельно модель, поиск, инфраструктуру, проверку качества и безопасность, проект начинает работать предсказуемо. Когда смешиваете всё в один длинный промпт, начинается дорогое и плохо управляемое гадание.



