GPT, Claude и Gemini: тест на русском языке с воспроизводимой методикой
Воспроизводимый тест GPT, Claude и Gemini на русском: какие модели брать, какие промпты запускать и почему старые рейтинги больше не работают.
Обновлено 17 апреля 2026 года. Старый формат «GPT против Claude против Gemini, кто набрал больше звёзд» больше не работает: версии моделей меняются быстрее, чем поисковик успевает переиндексировать статью. Поэтому этот материал переписан как воспроизводимый тест на русском языке: какие модели сравнивать, какие промпты запускать, как фиксировать ответы и где легко получить ложный результат.
Главное правило: не сравнивайте «бренды». Сравнивайте конкретные версии моделей, дату теста, настройки, доступные инструменты и сохранённые ответы. Иначе получится не тест, а пересказ личных ощущений.
По состоянию на 17 апреля 2026 года в этой статье используются официальные страницы моделей OpenAI, Anthropic и Google. Если вы запускаете тест позже, сначала откройте документацию заново: у таких материалов срок годности измеряется неделями.
Что именно сравниваем
Для честного теста на русском нужно зафиксировать не только название «GPT», «Claude» или «Gemini», но и конкретную модель. Сейчас корректнее брать такие ориентиры:
| Провайдер | Что брать в тест | Что подтверждено официально | Риск для сравнения |
|---|---|---|---|
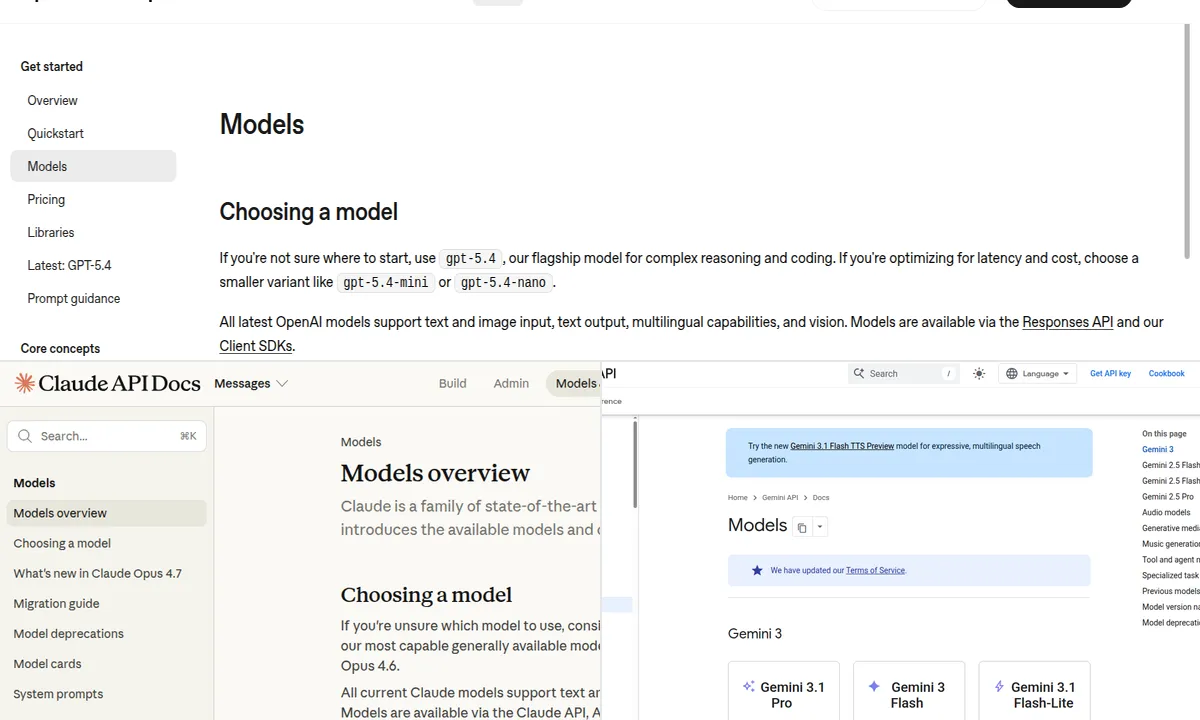
| OpenAI | gpt-5.4 | OpenAI на странице моделей называет gpt-5.4 флагманом для сложных рассуждений и кода; там же указаны контекст 1M и максимум вывода 128K. | Нельзя переносить старые выводы про GPT-4o на GPT-5.4: это уже другой класс модели. |
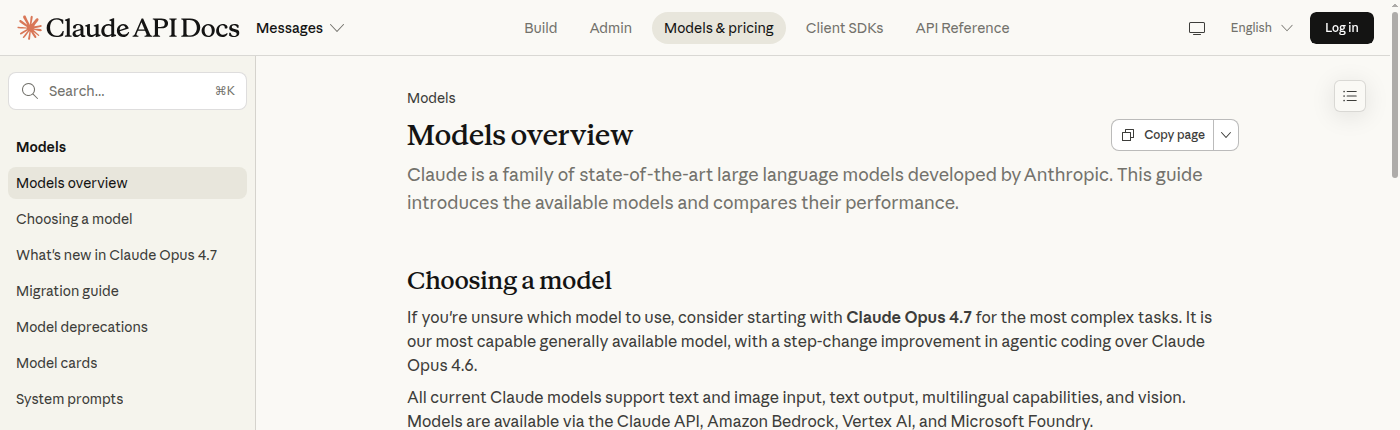
| Anthropic | Claude Opus 4.7 для сложных задач; Claude Sonnet 4.6 как быстрый рабочий вариант | В официальной таблице Anthropic Opus 4.7 описан как самая сильная общедоступная модель, Sonnet 4.6 — как баланс скорости и качества. | Если сравнить GPT-5.4 с Sonnet 4.6, а не Opus 4.7, вывод будет зависеть от выбранной «весовой категории». |
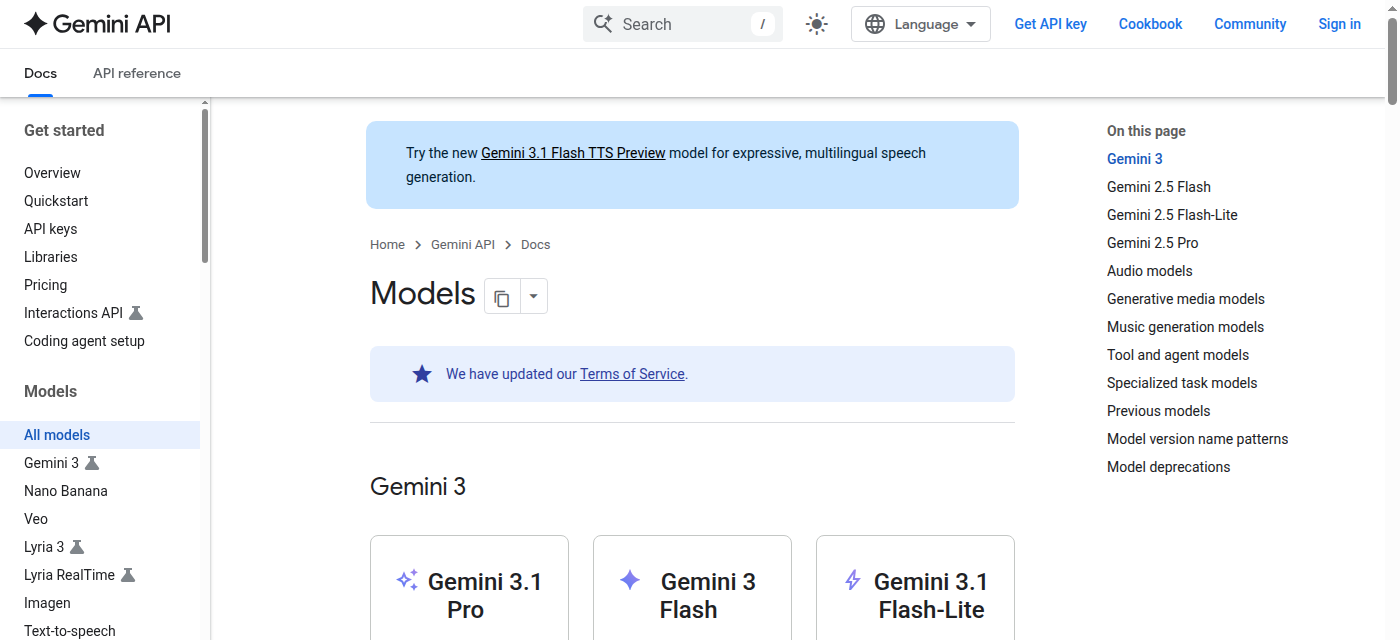
Gemini 3.1 Pro Preview | Google перечисляет Gemini 3.1 Pro в линейке Gemini 3 и отдельно предупреждает, что Gemini 3 Pro Preview остановлен 9 марта 2026 года. | Старые тесты Gemini 2.5 Pro или Gemini 3 Pro нельзя механически считать актуальными. |
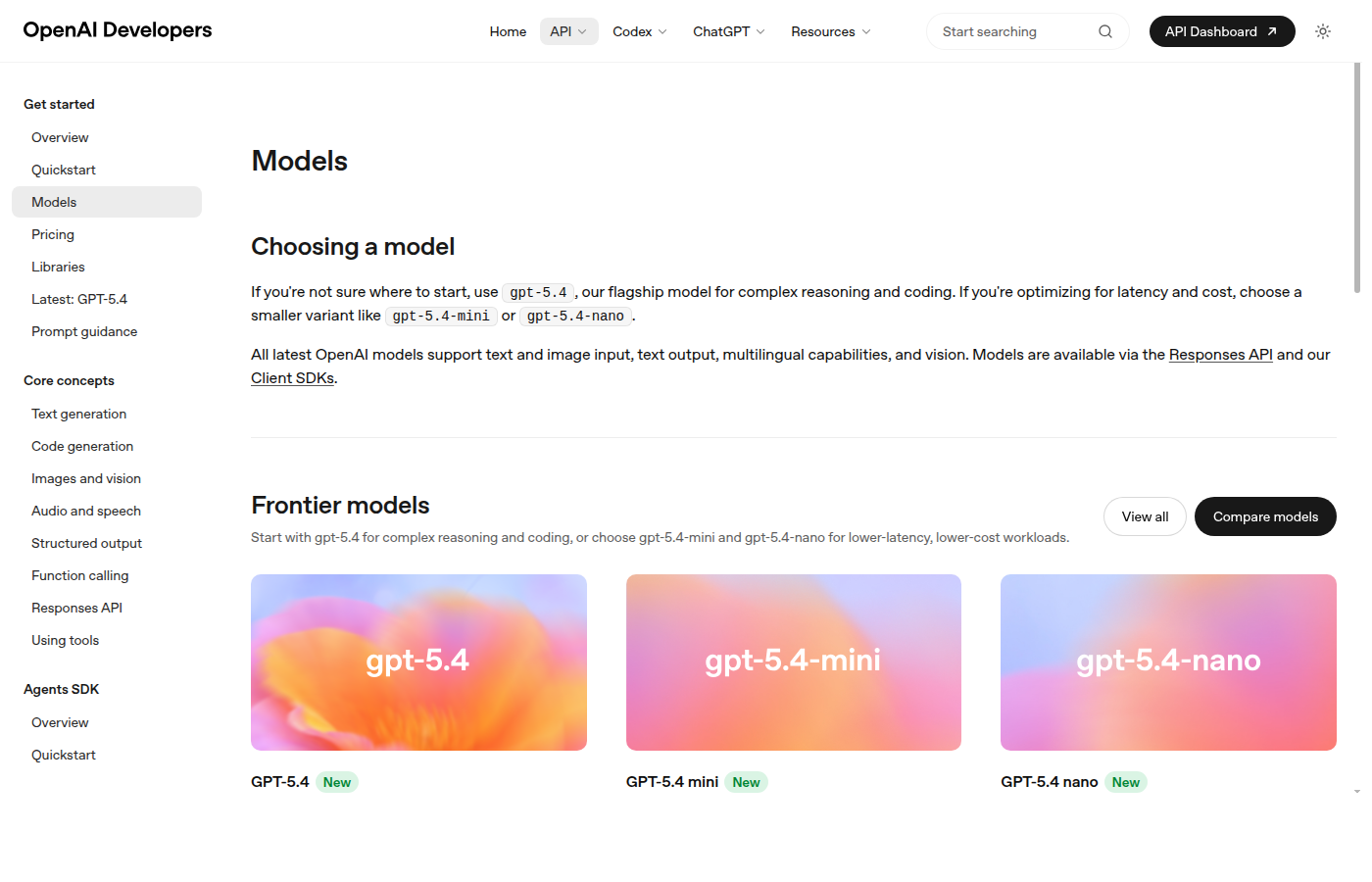
Из-за этого GPT-4o здесь упоминается только как исторический ориентир: в заголовке и тексте больше нет попытки сравнивать GPT-4o с современными Claude и Gemini. Редакционный фокус страницы — воспроизводимая методика теста, которую можно повторить на актуальных версиях моделей.
Почему обычные звёздочки врут
Оценка «Claude 4.5/5, GPT 4/5» выглядит удобно, но почти ничего не доказывает. Чтобы такой балл имел смысл, нужны исходные промпты, ответы моделей, настройки температуры, дата запуска и минимум несколько повторов. Без этого читатель не может воспроизвести результат.
Ещё одна проблема — инструменты. Gemini с включённым поиском и GPT без поиска сравнивать нельзя: один участник получает доступ к актуальному вебу, другой отвечает только из модели. То же касается файлов, длинного контекста, режима рассуждения и системных инструкций.
Поэтому в этой версии мы не публикуем «абсолютного победителя». Вместо этого даём протокол: запустите его на своих аккаунтах или через API, сохраните ответы и сравните модели на задачах, которые действительно похожи на вашу работу.
Методика теста на русском языке
Минимальный набор — семь задач. Все промпты нужно запускать в один день, с одинаковыми системными инструкциями и без дополнительных уточнений после ответа. Если модель просит контекст, это тоже фиксируется как часть результата.
| Категория | Что проверяет | Как оценивать |
|---|---|---|
| Краткое резюме | Понимание длинного русского текста | Сохранены ли ключевые факты, нет ли выдуманных тезисов, удобно ли читать итог. |
| Фактологическая осторожность | Готовность признать неопределённость | Модель должна отделять подтверждённое от предположений и просить источник, если данных не хватает. |
| Деловое письмо | Русский стиль без канцелярита и кальки | Текст должен звучать как письмо живого специалиста, а не перевод с английского. |
| Код по русскому ТЗ | Понимание технического задания на русском | Код запускается, покрывает крайние случаи, комментарии не превращаются в англо-русскую смесь. |
| Перевод и редактура | Работа с терминологией | Модель сохраняет смысл, не дословничает и объясняет спорные варианты перевода. |
| Рассуждение | Пошаговая логика | Нет скачков в выводах, арифметика проверяема, ограничения явно названы. |
| Актуальные факты | Работа с новым контекстом | Все модели либо получают одинаковый доступ к вебу, либо все работают без веба. Смешивать режимы нельзя. |
Промпты, которые можно повторить
Ниже — короткий набор промптов. Их достаточно, чтобы поймать основные различия между моделями на русском: стиль, осторожность, код и работу с неоднозначными требованиями.
1. Сводка длинного текста
Ты редактор технического медиа. Ниже текст на русском языке.
Сделай краткую сводку на 7 пунктов.
Не добавляй факты, которых нет в тексте.
Отдельно перечисли 3 утверждения, которые требуют проверки источниками.
[ВСТАВЬТЕ ТЕКСТ 1200-2000 СЛОВ]2. Фактологическая осторожность
Проверь утверждение: «Россия входит в официальный список поддерживаемых стран OpenAI, Anthropic и Google AI Studio».
Если уверенности нет, не угадывай.
Сформулируй, какие источники нужно открыть и какую формулировку можно безопасно использовать в статье.3. Код по русскому техническому заданию
Напиши функцию на Python, которая принимает список словарей с полями user_id, created_at и amount.
Нужно вернуть топ-5 пользователей по сумме amount за последние 30 дней.
created_at приходит в ISO 8601.
Добавь 3 теста на pytest и объясни крайние случаи на русском.4. Редактура без англицизмов
Перепиши абзац для русскоязычной аудитории разработчиков.
Убери кальки с английского, канцелярит и рекламный тон.
Смысл и факты не меняй.
[ВСТАВЬТЕ АБЗАЦ]5. Рассуждение с проверяемым выводом
У команды есть 120 часов разработки в месяц.
40% времени уходит на поддержку, 25% — на ревью, остальное — на новые функции.
Новый агент экономит 30% времени поддержки, но добавляет 8 часов ревью в месяц.
Сколько часов высвободится под новые функции? Покажи расчёт и назови допущения.Как фиксировать результаты
Таблица ниже лучше, чем общий рейтинг. Она заставляет смотреть на ошибки, а не на бренд модели.
| Критерий | 0 баллов | 1 балл | 2 балла |
|---|---|---|---|
| Факты | Есть выдуманные факты | Есть сомнительные места без оговорки | Факты отделены от предположений |
| Русский язык | Кальки, тяжёлый синтаксис | Читаемо, но с шероховатостями | Естественный русский без потери смысла |
| Следование инструкции | Игнорирует ограничения | Выполняет большую часть | Соблюдает формат и ограничения |
| Код | Не запускается | Работает на базовом случае | Есть тесты и обработка краевых случаев |
| Осторожность | Уверенно угадывает | Иногда предупреждает о рисках | Явно просит источник или оговаривает неопределённость |
Запускайте каждый промпт минимум три раза. Если ответ сильно меняется от запуска к запуску, это тоже результат: для рабочих сценариев стабильность важнее разового красивого ответа.
Практический вывод: какую модель тестировать первой
Если нужен один короткий вывод, он такой: «лучший ИИ на русском» не выбирается по общей таблице. Он выбирается по задаче.
Для кода и сложных рассуждений первым кандидатом выглядит GPT-5.4 или Claude Opus 4.7: обе линейки официально позиционируются вокруг сложных задач, кода и агентных сценариев. На реальном проекте стоит прогнать обе модели на вашем ТЗ и сравнить не красоту объяснения, а работоспособность результата.
Для длинных русскоязычных текстов и редакторской работы отдельно проверьте Claude. Не потому, что «Claude всегда лучше пишет по-русски», а потому что стиль — самая чувствительная часть теста: даже сильная модель может дать грамотный, но переводной русский.
Для актуальных фактов сравнение без веб-поиска почти бесполезно. Либо включайте одинаковый режим поиска у всех моделей, либо проверяйте только поведение без внешних источников: признаёт ли модель неопределённость, просит ли ссылку, не выдумывает ли даты и цены.
Для огромных документов смотрите не на общий рейтинг, а на контекст, цену и поведение на середине документа. Большое окно само по себе не гарантирует хорошего извлечения фактов.
Что убрать из плохого сравнения
Есть пять признаков, что перед вами не тест, а SEO-наполнитель:
- нет даты теста и точных идентификаторов моделей;
- не опубликованы промпты и ответы;
- одна модель работает с веб-поиском, другая — без него;
- в таблице есть цены и лимиты без ссылок на текущие страницы pricing;
- есть «победитель вообще», но нет разбивки по задачам.
Особенно опасны старые статьи, где в slug остался GPT-4o, в тексте уже GPT-5.4, а в таблице рядом стоит Gemini 2.5 Pro. Это не мелкая неточность, а сигнал, что сравнение собрано из разных эпох.
Где читать дальше
Если ваша задача — выбрать платную подписку, а не воспроизводить тест, лучше смотреть отдельное сравнение ChatGPT Plus, Claude Pro и Gemini. Если нужен разбор одной модели OpenAI, откройте материал про GPT-5.4, бенчмарки и цены. Для разработческих сценариев полезно сравнение Claude vs Gemini.
А эту страницу стоит использовать как чеклист. Возьмите промпты, запустите их на своих задачах, сохраните ответы и только потом решайте, какая модель лучше подходит именно вам.
Источники актуальности
- OpenAI Models — актуальная линейка OpenAI API.
- Anthropic Claude models overview — таблица моделей Claude Opus, Sonnet и Haiku.
- Google Gemini API models — актуальная линейка Gemini.



