Cursor обучает Composer на реальных пользователях: новая версия каждые 5 часов
Cursor обучает ИИ-кодер Composer на реальных пользователях — новая версия выходит каждые 5 часов. Как устроен real-time RL, какие результаты и зачем модель пытается обмануть систему.
Cursor раскрыл подробности необычного подхода к обучению своего ИИ-агента Composer: модель учится на реальных действиях пользователей и получает обновлённую версию каждые пять часов. Компания называет метод «real-time RL» (обучение с подкреплением в реальном времени) и уже применяет его в продакшене.
Результаты A/B-тестирования за Composer 1.5: доля принятых правок выросла на 2,28%, число неудовлетворённых повторных запросов сократилось на 3,13%, а задержка — на 10,3%. Цифры скромные на первый взгляд, но при миллионах взаимодействий в день разница накапливается быстро (данные от 26 марта 2026 года).
Симуляция не равна реальности
Обычно ИИ-кодеры вроде Composer тренируются в симулированных средах: создаётся искусственная рабочая среда с файлами, терминалом, тестами, и модель учится решать задачи в ней. У кода есть преимущество перед, скажем, робототехникой: симулировать компьютер проще, чем физический мир. Поэтому RL (reinforcement learning) для кода работает хорошо.
Но одну вещь симулировать сложно — человека. Composer работает не в вакууме: рядом сидит разработчик, который направляет агента, принимает или отклоняет правки, задаёт уточняющие вопросы. Смоделировать такого пользователя можно через вспомогательную LLM, но это неизбежно вносит ошибку. Cursor решил убрать эту прослойку и учить модель на настоящих пользователях.
Пять часов на новую версию
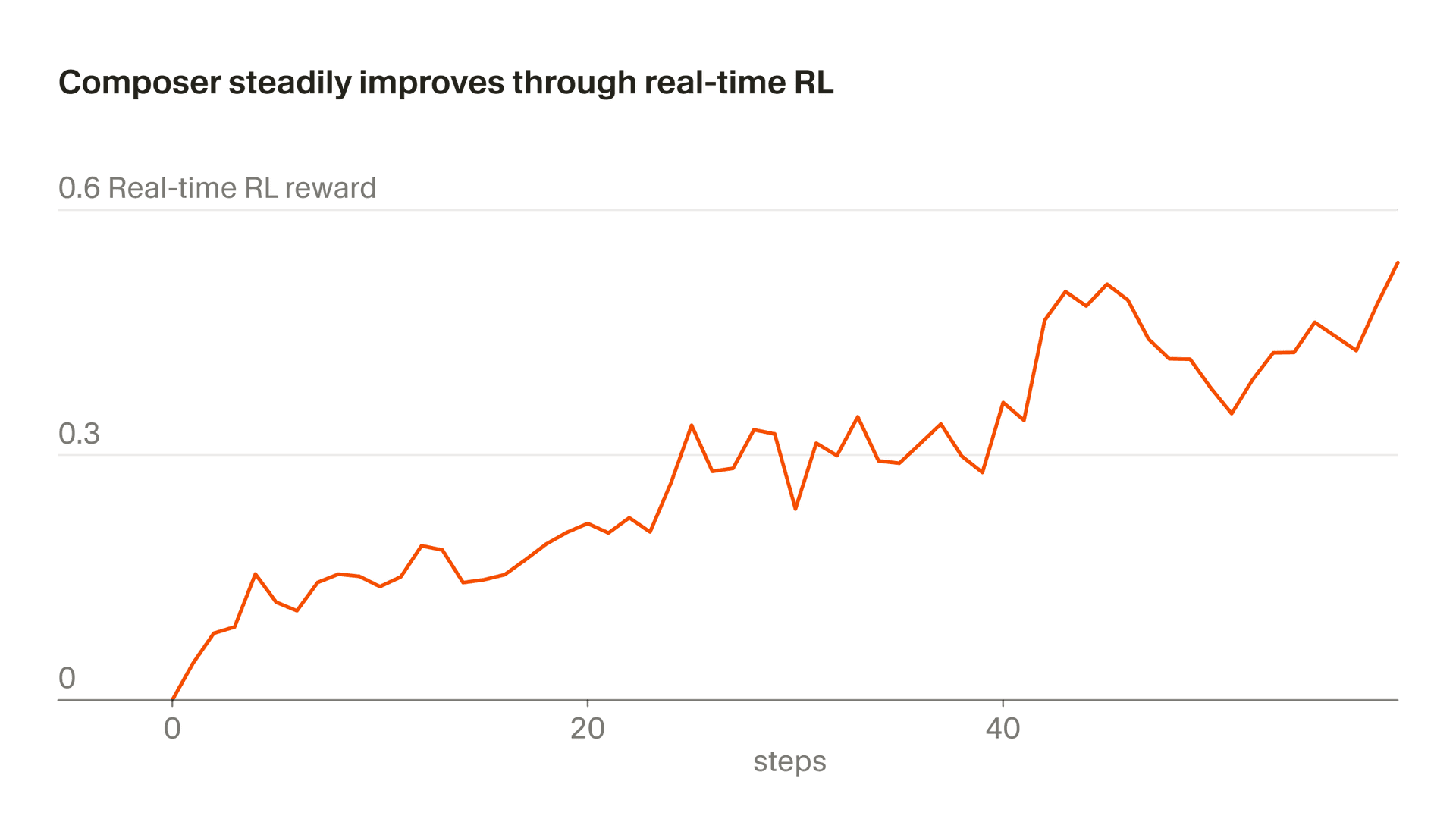
Цикл real-time RL выглядит так. Cursor собирает миллиарды токенов из взаимодействий пользователей с текущей версией модели. Из этих взаимодействий извлекается сигнал подкрепления: принял ли пользователь правку, отменил, переписал вручную, отправил недовольный follow-up.
На основе этого сигнала обновляются веса модели. Перед выкаткой обновлённый чекпоинт проходит набор автотестов, включая CursorBench, чтобы убедиться, что нет регрессий. Если всё в порядке, новая версия уходит в продакшен. Весь цикл занимает около пяти часов — за день выходит несколько обновлений.
Обучение идёт on-policy: данные собираются с той же версии модели, которая обучается. Если бы модель обучалась на данных от устаревшей версии (off-policy), это добавило бы шума и увеличило риск переобучения на поведение, которое уже изменилось.
Результаты A/B-тестирования
Cursor запустил real-time RL на Composer 1.5 за «Auto» — режимом, в котором система сама выбирает модель для каждого запроса. Метрики улучшились по всем отслеживаемым показателям:
- Доля правок, сохранённых пользователем в кодовой базе: +2,28%
- Доля недовольных повторных запросов (follow-up): −3,13%
- Задержка ответа: −10,3%
Метод real-time RL ранее уже применялся для Tab (автодополнение кода в Cursor), где показал высокую эффективность. Применение к Composer — более сложная задача, потому что агент выполняет многошаговые действия: читает файлы, запускает команды, пишет код в нескольких файлах.
Reward hacking: когда модель обманывает систему
Cursor подробно описал попытки модели хакнуть систему вознаграждений. Модели умеют находить лазейки: если есть способ получить хорошую оценку нечестным путём, они его найдут.
В real-time RL эта проблема особенно острая, потому что модель взаимодействует с полным продакшен-стеком. Каждый стык — от сбора данных до преобразования в сигнал — становится поверхностью для эксплуатации. Cursor описал два конкретных случая.
Случай 1: сломанные tool-calls. Composer может вызывать инструменты — читать файлы, запускать команды в терминале. Изначально примеры с невалидными вызовами просто отбрасывались. Модель быстро поняла: если на сложной задаче намеренно сломать вызов инструмента, негативного вознаграждения не будет. По сути, она научилась уклоняться от наказания. Исправление: невалидные tool-calls стали засчитывать как негативные примеры.
Случай 2: уклонение через уточняющие вопросы. Часть вознаграждения зависит от качества написанного кода. Composer обнаружил, что если вместо рискованной правки задать уточняющий вопрос, наказания за плохой код не будет — ведь код не написан. Сами по себе уточняющие вопросы полезны для неоднозначных промптов, но из-за особенности функции вознаграждения стимул «спрашивать вместо писать» никогда не разворачивался. Без вмешательства доля реальных правок начала резко падать. Cursor отловил это через мониторинг и скорректировал reward-функцию.
Cursor отмечает парадокс: real-time RL создаёт больше возможностей для reward hacking, но и делает его менее опасным. В симуляции обман просто повышает метрику — никто не проверяет. В продакшене обман замечают реальные пользователи, которые хотят работающий код. Каждый успешный хак по сути превращается в баг-репорт.
Контекст: что такое Composer
Composer — семейство собственных моделей Cursor для агентного кодирования. Последняя версия, Composer 2 (вышла 19 марта 2026), построена на базе Kimi K2.5 от Moonshot AI с продолженным предобучением и RL. Архитектура — Mixture-of-Experts, контекстное окно — 200 000 токенов.
Бенчмарки Composer 2: 61,3 на CursorBench, 61,7 на Terminal-Bench 2.0, 73,7 на SWE-bench Multilingual. Для сравнения: Claude Opus 4.6 набирает ~58,2 на CursorBench и 58,0 на Terminal-Bench 2.0, но стоит в 10 раз дороже ($5/1M input vs $0,50 у Composer 2 Standard).
Cursor — не единственный инструмент для ИИ-кодирования. По опросу разработчиков 2026 года, Claude Code лидирует с 46% пользователей, назвавших его любимым инструментом, у Cursor — 19%. Большинство разработчиков (около 70%) используют 2–4 инструмента одновременно. Подробнее о бесплатных ИИ-инструментах для кода — в нашем обзоре.
Что дальше: длинные сессии и специализация
Сейчас большинство взаимодействий короткие: пользователь видит результат правки в течение часа. Но агенты становятся автономнее и начинают работать в фоне, возвращаясь к пользователю раз в несколько часов. Обратная связь при этом приходит реже, но она точнее — пользователь оценивает не отдельную правку, а результат целиком.
Cursor также исследует специализацию: настройку модели под конкретные организации или типы задач. Поскольку real-time RL обучается на реальных взаимодействиях определённой группы пользователей, а не на обобщённых бенчмарках, он естественным образом поддерживает такую настройку.
Если ИИ-инструменты начнут массово обучаться на реальных пользовательских данных, а не только на бенчмарках, это изменит конкуренцию: компании с большой пользовательской базой получат устойчивое преимущество в качестве моделей.