Агентный ИИ: архитектуры AI-агентов, ReAct и tool use
Как устроены агентные системы вокруг LLM: ReAct, tool use, память, маршрутизация, мультиагентные схемы и контроль рисков в production.

Агентный ИИ — это не отдельный тип модели, а способ собрать систему вокруг LLM: модель рассуждает, вызывает инструменты, читает наблюдения и продолжает работу до результата. В этой статье фокус на архитектуре: ReAct, tool use, память, планирование, мультиагентные схемы и ограничения в production.
Если нужен базовый разбор без технических деталей, начните с evergreen-материала AI-агенты: что это такое и как работают.
Что значит агентная архитектура
В агентной архитектуре LLM не просто пишет ответ. Она выбирает следующее действие из разрешённого набора, получает результат и решает, завершать задачу или продолжать. Это делает систему полезнее обычного prompt-to-answer, но добавляет новые точки отказа.
- Модель — центр принятия решений.
- Инструменты — безопасные функции с явной схемой входа и выхода.
- Среда — всё, куда агент может смотреть или что может менять.
- Состояние — память о задаче, пользователе, промежуточных шагах.
- Политики — лимиты, права, проверки, правила остановки.
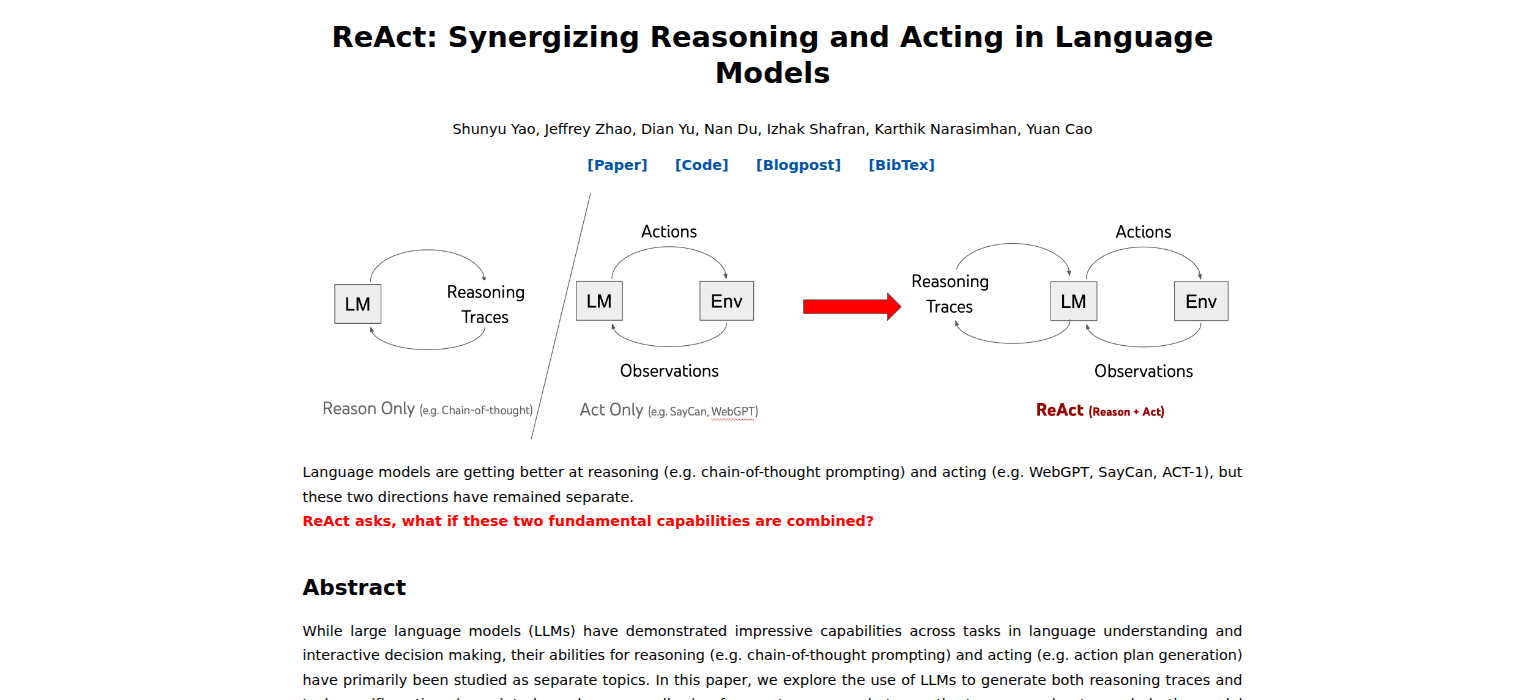
ReAct: reasoning плюс acting
Классический паттерн ReAct описан в работе 2022 года ReAct: Synergizing Reasoning and Acting in Language Models. Идея простая: модель чередует рассуждение, действие и наблюдение. Рассуждение помогает выбрать шаг, действие обращается к инструменту, наблюдение возвращает факты в контекст.
Goal: найти актуальный статус заказа A-1042
Thought: нужно получить данные из CRM
Action: get_order(order_id="A-1042")
Observation: заказ оплачен, доставка запланирована на 15 апреля
Thought: нужно сформулировать короткий ответ клиенту
Final: Заказ A-1042 оплачен, доставка запланирована на 15 апреля.В production не обязательно показывать рассуждения пользователю. Важно другое: каждое действие должно быть структурированным, журналируемым и проверяемым.
Tool use: слой действий
Tool use — граница между моделью и реальным миром. Модель не должна сама менять данные. Она просит вызвать инструмент с аргументами, а приложение проверяет права, выполняет функцию и возвращает результат.
- Read-only инструменты безопаснее: поиск, чтение документа, получение статуса.
- Write-инструменты требуют подтверждения или строгих политик: отправка письма, изменение заказа, создание платежа.
- Каждый инструмент должен иметь схему аргументов, описание и понятный формат ошибки.
- Чем больше инструментов видно модели одновременно, тем выше риск неверного выбора.
Память и состояние
Память в агенте — это не «всё, что когда-либо сказал пользователь». Обычно нужны несколько уровней: текущая задача, краткое резюме диалога, профиль пользователя, долговременные факты и внешние документы. Каждый уровень должен иметь срок жизни и источник.
- Short-term memory держит текущий контекст задачи.
- Long-term memory хранит устойчивые предпочтения и факты.
- Retrieval memory подтягивает документы из базы знаний.
- Execution state фиксирует уже выполненные шаги, чтобы агент не повторял одно и то же.
Планирование и маршрутизация
Не каждый агент должен строить длинный план. Для многих продуктов лучше работает маршрутизация: классифицировать задачу, выбрать короткий сценарий и выполнить его под контролем. Длинное автономное планирование нужно там, где маршрут заранее неизвестен: исследование, отладка, работа с несколькими источниками.
| Паттерн | Где полезен | Главный риск |
|---|---|---|
| Router | Поддержка, triage, выбор workflow | Неверная классификация |
| ReAct loop | Поиск, анализ, работа с инструментами | Бесконечные или лишние шаги |
| Planner-executor | Сложные задачи с несколькими этапами | План устаревает после первого сбоя |
| Multi-agent | Разделение ролей: исследователь, исполнитель, ревьюер | Спор агентов вместо результата |
Мультиагентные системы
Мультиагентная схема имеет смысл, когда роли действительно разные. Например, один агент собирает источники, второй пишет код, третий проверяет тесты и безопасность. Если все агенты получают один и тот же контекст и одинаковые инструменты, вы просто умножаете стоимость и шум.
- Роли должны быть узкими и проверяемыми.
- Передача между агентами должна идти через артефакт: diff, таблицу, отчёт, список фактов.
- Нужен один владелец финального решения.
- Параллельность полезна только там, где задачи независимы.
Наблюдаемость и оценка качества
Агент без трассировки невозможно отлаживать. Логи должны показывать не только финальный ответ, но и последовательность шагов: какой инструмент вызван, с какими аргументами, что вернулось, сколько это стоило и почему цикл остановился.
- Trace ID для каждого запуска.
- Список tool calls с аргументами и результатами.
- Счётчики токенов и внешних API-вызовов.
- Причина остановки: успех, лимит шагов, ошибка инструмента, ручное подтверждение.
- Набор eval-задач для регрессионной проверки.
Ограничения в production
Агентная система ломается не так, как обычный сервис. Сервис падает или возвращает ошибку; агент может сделать правдоподобный, но неверный шаг. Поэтому безопасность строится не только вокруг модели, но и вокруг инструментов.
- Минимизируйте права инструментов: read-only по умолчанию.
- Добавляйте подтверждение человека для дорогих и необратимых действий.
- Проверяйте входные документы на prompt injection.
- Ставьте лимит шагов, времени и бюджета.
- Делайте idempotency для write-операций, чтобы ретрай не дублировал действие.
Как выбрать архитектуру
- Задача одношаговая — обычный LLM-запрос или tool call без агента.
- Есть 2-4 понятных маршрута — router/workflow.
- Нужны внешние данные и несколько попыток — ReAct loop с лимитом шагов.
- Нужны роли и независимые подзадачи — multi-agent, но только с явным владельцем финального ответа.
- Нужны действия в браузере или интерфейсе — отдельный sandbox и ручное подтверждение критичных шагов.
Что читать дальше
- AI-агенты: что это такое и как работают — объяснение без архитектурной глубины.
- MCP: стандарт интеграции ИИ с инструментами — подключение внешних инструментов.
- LangChain vs LlamaIndex: фреймворки для RAG — соседний стек для retrieval-сценариев.



