N-Day-Bench: как LLM ищут реальные уязвимости в коде
N-Day-Bench проверяет, как LLM ищут реальные N-day уязвимости в коде. Главное не leaderboard, а методика, traces и ограничения.
N-Day-Bench LLM уязвимости проверяет практический навык: может ли языковая модель открыть реальный репозиторий, пройти от входных данных к опасной точке в коде и объяснить уже раскрытую уязвимость так, чтобы отчёт выдержал проверку.
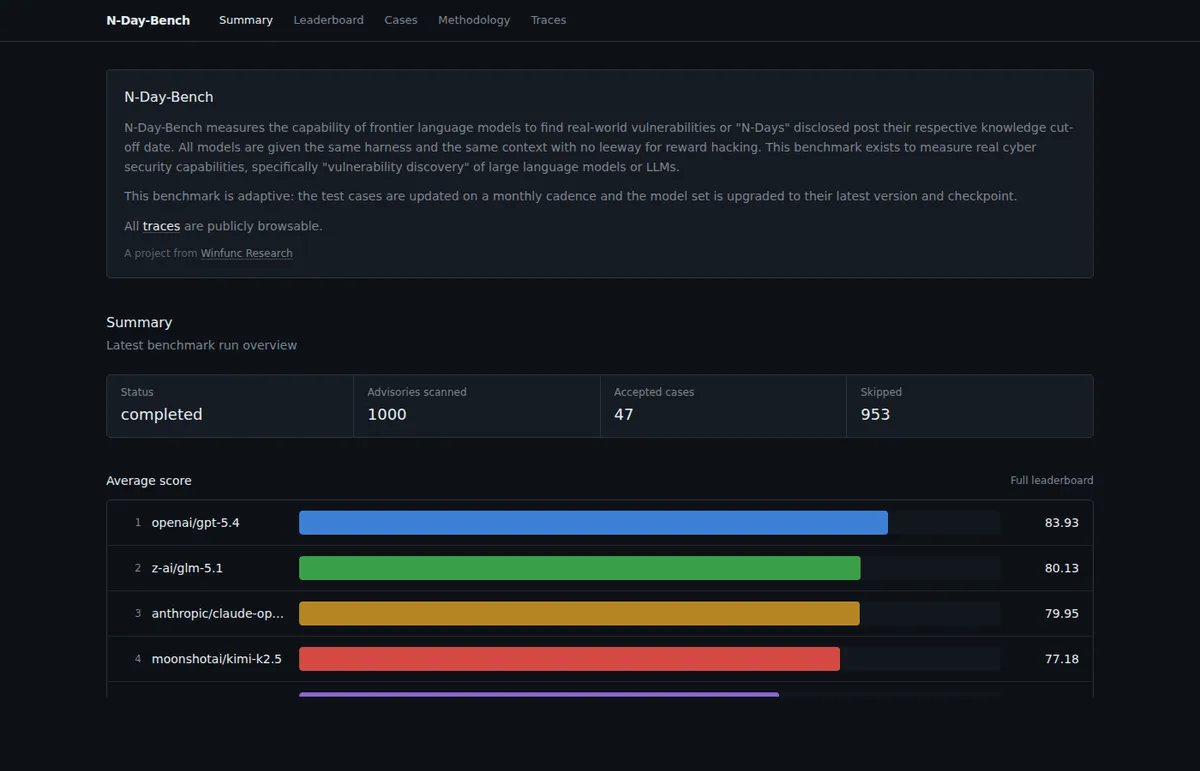
По состоянию на 14 апреля 2026 года последний запуск N-Day-Bench от Winfunc Research завершён: сайт показывает 1000 просканированных GitHub security advisories, 47 принятых кейсов и 953 пропущенных. Бенчмарк не просит модели писать эксплойты и не выбирает «самую безопасную модель». Он меряет узкую, но важную вещь: насколько LLM пригодны для поиска N-day уязвимостей в коде.
Почему это важно сейчас: security-команды уже используют ИИ для первичного разбора кода, triage и подготовки отчётов. Пока это часто выглядит как эксперимент. N-Day-Bench показывает, что такие эксперименты быстро становятся инженерной дисциплиной с трассировками, ограничениями среды, проверяемыми отчётами и публичной методикой.
Что такое N-Day-Bench
N-day уязвимость — это баг, который уже раскрыт публично: например, через advisory, CVE, commit с исправлением или релиз с patch notes. Модель не ищет неизвестный zero-day. Ей дают состояние репозитория до исправления и проверяют, сможет ли она восстановить путь уязвимости по коду.
В официальной методологии N-Day-Bench описан как ежемесячный адаптивный бенчмарк для repository-grounded vulnerability discovery. Кандидаты берутся из GitHub security advisories в ограниченном временном окне. Это снижает риск, что модели просто вспоминают старые кейсы из обучающих данных, хотя полностью проблему утечки benchmark-данных не убирает.
Кейс попадает в набор только после строгого фильтра. Advisory должен явно ссылаться на репозиторий, репозиторий должен проходить порог популярности, а исправление должно быть однозначно связано с одним fix reference. Если ссылка мутная, commit merge-овый, repository не резолвится или контекст допускает догадки, кейс пропускают.
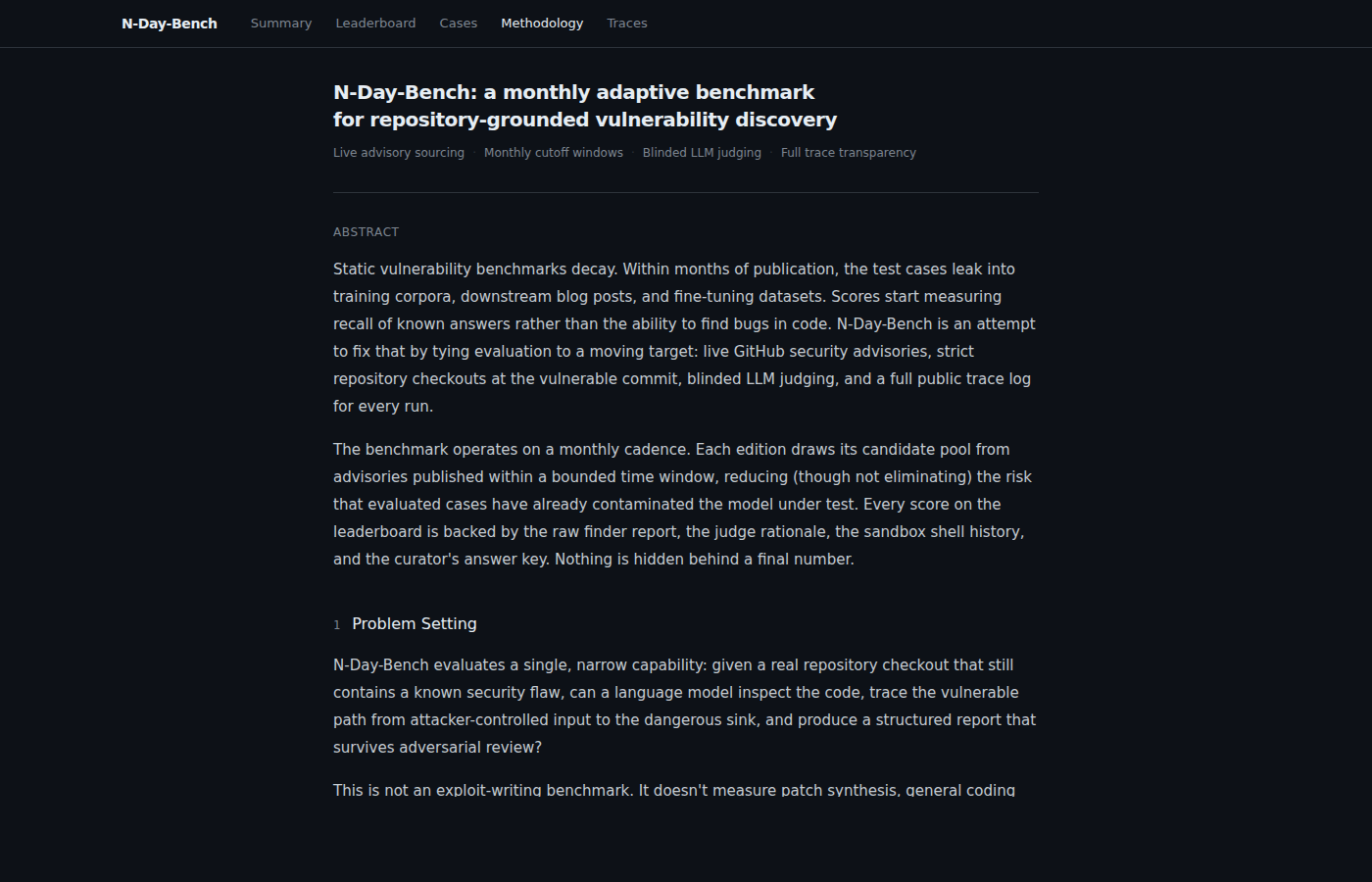
Как устроена проверка
Внутри бенчмарка три роли. Curator получает advisory, изменённые файлы и excerpts из patch, а затем готовит структурированный кейс: синопсис, подсказки по опасным точкам, prompt для finder-модели и answer key для проверки. Finder-модель видит только задачу и read-only shell в уязвимом checkout репозитория. Judge получает отчёт finder-модели, answer key и фиксированную рубрику, но не знает, какая модель сделала submission.
Эта асимметрия важна. Finder не получает patch и не может просто посмотреть исправление. При этом benchmark не просит её «найти что-нибудь плохое в проекте». Методология прямо говорит: finder prompt всегда начинается от известного sink. Проверяется способность проследить источник данных, контрольный поток и конкретную опасную операцию.
У finder-модели есть до 24 шагов использования инструментов. Shell работает в read-only overlay, команды ограничены таймаутами, а git зашит безопасными stub-ответами для части операций. Это не идеальная симуляция работы аудитора, но она убирает часть шума: модель не должна чинить код, мутировать репозиторий или тратить бесконечный бюджет на обход дерева файлов.
Почему это не тест на «взлом всего подряд»
N-Day-Bench легко неправильно прочитать как leaderboard для AI-хакеров. Это было бы неверно. В методологии прямо сказано, что бенчмарк не измеряет exploit writing, patch synthesis, общую способность писать код или классификацию CWE в отрыве от исходников.
Оценка строится вокруг пяти измерений: попадание в правильную цель, source-to-sink reasoning, impact and exploitability, качество доказательств и контроль чрезмерных заявлений. Если модель называет правильный класс уязвимости, но не показывает файл, sink и путь данных, она получает низкий балл. Если пишет убедительный текст без опоры на код, её тоже штрафуют.
Это ближе к работе сильного triage-инженера: быстро понять, где баг, почему входные данные доходят до опасного места, насколько серьёзен impact и какие claims нельзя делать без доказательств. В нашем разборе бенчмарков ИИ-агентов на exploit-задачах мы уже писали о главной ловушке таких тестов: итоговый балл полезен только вместе с методикой. N-Day-Bench как раз интересен тем, что показывает не только число, но и trail за ним.
Что показал последний запуск
Лидерборд N-Day-Bench на 14 апреля 2026 года помечен caveats: завершены 47 кейсов, сохранены 212 completed submissions, 29 runs timed out, а у запуска перечислены 15 caveat-записей. Поэтому таблицу ниже нужно читать как срез конкретного прогона, а не как универсальный рейтинг моделей для всех задач безопасности.
| Модель в N-Day-Bench | Average score | Completed | Avg findings |
|---|---|---|---|
| openai/gpt-5.4 | 83.93 | 44 | 1.07 |
| z-ai/glm-5.1 | 80.13 | 44 | 1.23 |
| anthropic/claude-opus-4.6 | 79.95 | 43 | 1.16 |
| moonshotai/kimi-k2.5 | 77.18 | 37 | 1.05 |
| google/gemini-3.1-pro-preview | 68.50 | 44 | 0.91 |
Лидерство GPT-5.4 в этом прогоне интересно, но не менее важны два соседних факта. Во-первых, GLM-5.1 и Claude Opus 4.6 находятся рядом по average score. Во-вторых, распределение verdict показывает разные профили ошибок: у GPT-5.4 в сохранённых submissions 34 excellent, 7 partial и 3 missed, у Claude Opus 4.6 — 24 excellent, 19 partial и 0 missed, у Gemini 3.1 Pro Preview есть 2 invalid. Для security-процесса это важнее среднего балла: missed, partial и invalid требуют разных механизмов контроля.
Зачем нужны публичные traces
Самая полезная часть N-Day-Bench — публичный trace log. Сайт показывает 469 traces в последнем запуске: curator, finder и judge runs с prompts, метаданными шагов и shell commands. В методологии указано, что каждый прогон хранит accepted/skipped advisories, checkout reference, curator case, finder submission, judge score, rationale и историю команд sandbox.
Это меняет качество разговора о LLM в кибербезопасности. Без trace мы видим только «модель получила 83.93». С trace можно проверить, какие команды она запускала, где нашла доказательства, где judge согласился, где модель перепридумала impact и почему кейс засчитан частично. Для бенчмарков безопасности это не косметика, а защита от leaderboard theater.
Та же проблема была в истории с закрытыми cyber-моделями. В материале про Claude Mythos и безопасность мы разбирали, почему заявления о «слишком опасных» возможностях трудно оценивать без воспроизводимых артефактов. N-Day-Bench не решает всю проблему, но даёт формат: если модель нашла уязвимость, покажите путь к sink, команды, отчёт и решение judge.
Lean/fuzzing показывает тот же сдвиг с другой стороны
Связанный сигнал пришёл 13 апреля 2026 года из статьи «Lean proved this program was correct; then I found a bug». Автор направил Claude-агента на `lean-zip`, проверенную в Lean реализацию zlib, и вооружил его AFL++, AddressSanitizer, Valgrind и UBSan.
По описанию автора, за ночь Claude запустил 16 параллельных fuzzers по 6 attack surfaces, подготовил 359 seed files, выполнил 105 823 818 fuzzing executions примерно за 19 часов и нашёл 4 crashing inputs. В проверенном application code не нашлось memory vulnerabilities, зато обнаружился heap buffer overflow в Lean 4 runtime (`lean_alloc_sarray`) и denial-of-service в архивном парсере `lean-zip`, который не был покрыт доказательствами.
Этот кейс не доказывает, что агент заменит аудитора. Он показывает, что связка LLM, fuzzing и санитайзеров уже достаточно полезна для поиска реальных сбоев на границе формально проверенного кода и доверенной среды исполнения. Для практической безопасности это знакомая история: доказательства сильны там, где они применены, но среда исполнения, FFI, парсеры и непроверенные оболочки остаются частью риска.
Что меняется для разработчиков и security-команд
Первый вывод простой: LLM надо включать в первичный разбор как инструмент с журналом действий. Хороший процесс должен сохранять prompt, команды, найденные пути, ссылки на файлы, вердикт проверяющего и причину принятия или отклонения отчёта. Без этого модельная находка превращается в текст, которому либо верят на слово, либо выбрасывают.
Второй вывод касается подготовки кода. Агентам легче работать там, где есть понятные точки входа, тесты, воспроизводимая сборка, минимум побочных эффектов и нормальная структура репозитория. Если проект нельзя быстро поднять локально, если тесты падают до начала анализа, а чувствительный к безопасности код размазан по неочевидным слоям, модель будет тратить бюджет на инфраструктурный шум.
Третий вывод: открытые модели и закрытые модели придётся оценивать не только по среднему баллу. В статье про открытые модели в кибербезопасности мы отдельно разбирали pipeline, triage и verification как слой безопасности. N-Day-Bench хорошо ложится в эту логику: модель может быть сильной, но процесс должен уметь ловить выдуманные exploit chains, неверные sinks и чрезмерные claims.
Ограничения, о которых нельзя забывать
N-Day-Bench работает с GitHub advisories, а они неровные. Одни advisories дают точные commits и хороший контекст, другие слишком тонкие или неоднозначные. Строгий фильтр отсекает плохие кейсы, но создаёт bias в сторону проектов, которые публикуют машиночитаемые advisory именно через GitHub.
Sink hints тоже важны. Если модель начинает с известной опасной точки, она решает задачу triage, а не полный open-ended audit. Из такой постановки нельзя делать вывод, что модель сама найдёт любую уязвимость в большом коде. Наконец, judge в текущей методике тоже LLM, закреплённый как gpt-5.4. Blinding снижает предвзятость к бренду модели, но не убирает стилистические и методические риски автоматической оценки.
Поэтому лучший способ читать N-Day-Bench такой: это ранний, но полезный формат проверки AI-assisted vulnerability discovery. Не истина в последней инстанции, не сертификат безопасности и не обещание замены pentest-команд. Скорее, это пример того, как должен выглядеть честный разговор о моделях в безопасности: методика, ограничения, traces, caveats и проверяемые отчёты вместо одного красивого числа.
Итог
Главная ценность N-Day-Bench не в разнице между 83.93 и 80.13. Важнее сдвиг в постановке задачи: LLM оценивают по способности читать реальный код, связывать входные данные с опасным sink, удерживать доказательства и не делать лишних claims.
Для разработчиков это сигнал готовить репозитории, тесты и логи к миру, где AI-assisted security review станет обычной частью процесса. Для security-команд — повод строить проверяемый pipeline вокруг моделей, а не ждать от них чудес. Модель может ускорить поиск N-day уязвимостей, но доверять нужно не модели самой по себе, а трассируемому процессу вокруг неё.



