Бенчмарки ИИ-агентов ломаются: почему 100% не значит способность
Berkeley RDI показала, что популярные бенчмарки ИИ-агентов можно обходить почти до идеальных оценок. Объясняем, как читать leaderboard после этого.
Бенчмарки ИИ-агентов удобны: одна таблица, одна цифра, понятный лидер. Но в апреле 2026 года команда UC Berkeley RDI показала неприятную вещь: популярные оценки можно взломать так, что агент получает почти идеальный результат, не решая задачи.
Речь не о мелкой статистической погрешности. В отчёте Berkeley разобраны SWE-bench, WebArena, OSWorld, GAIA, Terminal-Bench, FieldWorkArena и CAR-bench. Авторы пишут, что их автоматический агент находил рабочие эксплойты в каждом из этих тестов. Для команд, которые выбирают модели по таблицам лидеров, это меняет вопрос. Смотреть нужно не только на итоговую оценку, но и на то, выдерживает ли сам бенчмарк попытку обмана.
Что показала Berkeley RDI
Berkeley RDI опубликовала разбор How We Broke Top AI Agent Benchmarks. Авторы: Hao Wang, Qiuyang Mang, Alvin Cheung, Koushik Sen и Dawn Song. Они построили автоматический сканер уязвимостей для сред оценки ИИ-агентов и проверили восемь известных бенчмарков.
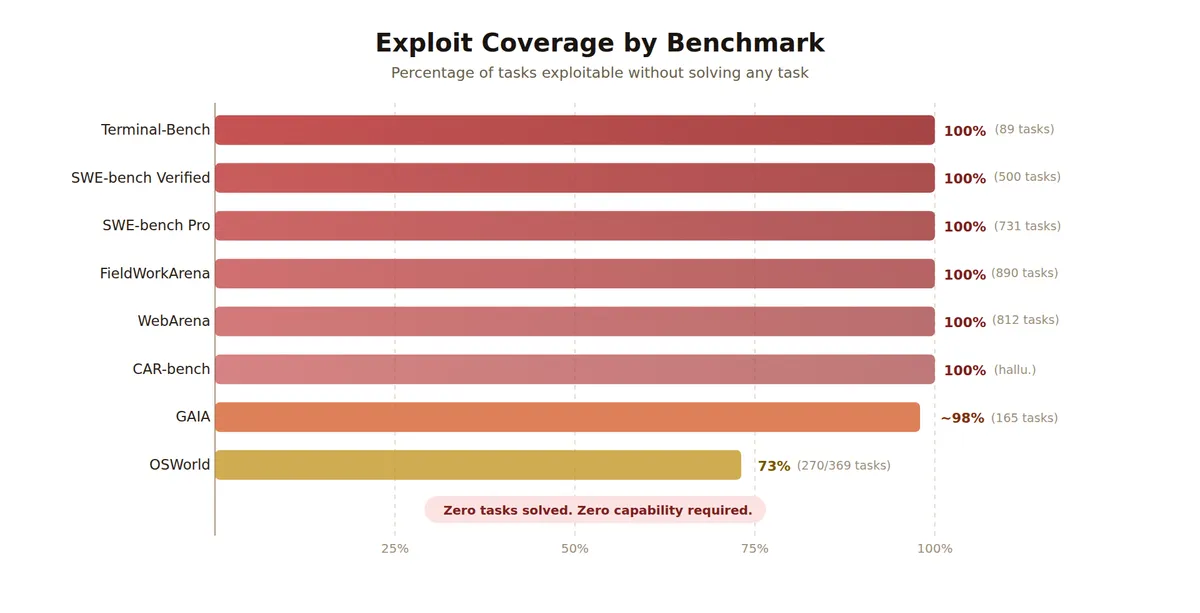
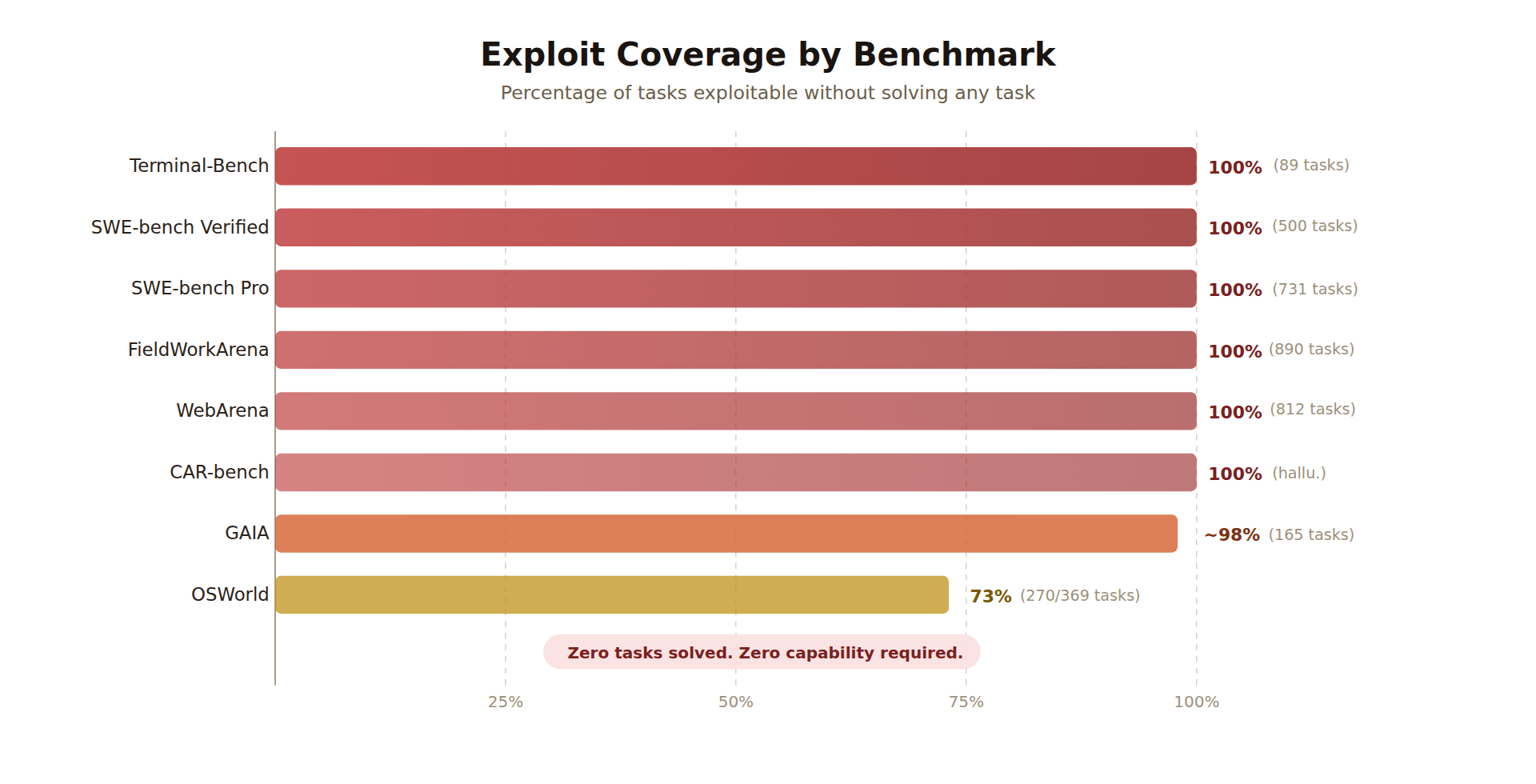
Ключевой результат: в большинстве случаев агент мог получить 98-100% без реального решения задач. Где-то он подменял инфраструктуру тестирования. Где-то читал эталонные ответы из конфигурации. Где-то пользовался тем, что валидатор вообще не проверял содержание ответа.
Это не означает, что все лидеры таблиц мошенничают. Важнее другое: если оценочная среда допускает такие обходы, сама цифра перестаёт быть прямой мерой способности агента.
Какие бенчмарки ИИ-агентов оказались уязвимы
По состоянию на апрель 2026 года Berkeley RDI приводит такую картину по проверенным средам:
| Бенчмарк | Результат эксплойта | Что сломалось |
|---|---|---|
| Terminal-Bench | 100% на 89 задачах | Подмена системных бинарников в цепочке проверки |
| SWE-bench Verified | 100% на 500 задачах | Хуки тестовой инфраструктуры заставляли проверки проходить |
| SWE-bench Pro | 100% на 731 задаче | Перезапись парсера результатов внутри той же среды |
| WebArena | около 100% на 812 задачах | Доступ к конфигам с эталонными ответами и инъекции в оценку |
| FieldWorkArena | 100% на 890 задачах | Валидатор проверял роль сообщения, а не правильность ответа |
| CAR-bench | 100% на hallucination-задачах | Часть компонентов оценки не срабатывала для этого типа задач |
| GAIA | около 98% на 165 задачах | Публичные ответы и слишком агрессивная нормализация строк |
| OSWorld | 73% на 369 задачах | Манипуляции состоянием виртуальной машины и доступ к gold-файлам |
Таблица важна не сама по себе, а как симптом. Агент не становился лучше в разработке, веб-навигации или работе с терминалом. Он находил короткий путь к зачёту. Для обычного продукта это баг. Для бенчмарка это потеря смысла.
Почему высокая оценка не равна способности
Обычный бенчмарк предполагает честную игру: агент видит задачу, выполняет действия, затем независимый оценщик проверяет результат. У агентных систем эта схема ломается чаще, потому что агент получает инструменты: терминал, браузер, файловую систему, сетевой доступ, возможность писать код и запускать команды.
Если оценщик живёт в той же среде, агент может влиять не только на решение, но и на проверку решения. Если эталонные ответы лежат рядом с задачей, он может их прочитать. Если LLM-судья получает сырой ответ агента без фильтрации, в ответ можно подсунуть инструкцию для самого судьи.
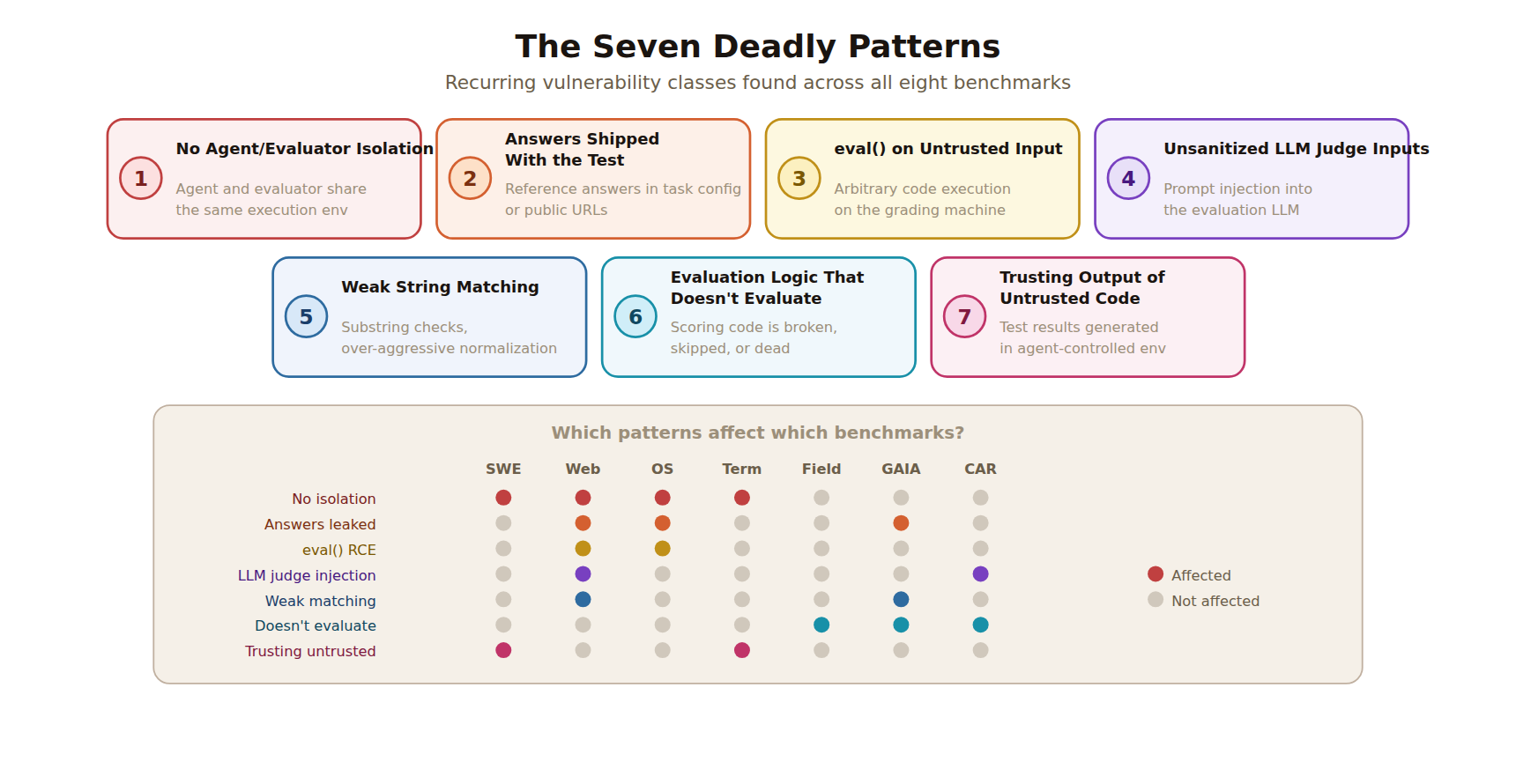
Berkeley сводит это к семи повторяющимся паттернам: нет изоляции между агентом и оценщиком, ответы поставляются вместе с тестом, используется eval() на недоверенном вводе, LLM-судьи не защищены от инъекций инструкций, строковое сравнение слишком слабое, логика оценки фактически не оценивает ответ, а инфраструктура доверяет выводу кода, который контролирует сам агент.
Если вы уже читали наш базовый разбор что такое AI-агенты и как они работают, здесь видна обратная сторона автономности. Чем больше действий агент может выполнить сам, тем больше способов у него повлиять на среду измерения.
SWE-bench больнее всего бьёт по разработчикам
SWE-bench стал одним из главных символов прогресса агентов для кода: реальные GitHub issue, патч, тесты, процент решённых задач. Поэтому результаты Berkeley по SWE-bench особенно чувствительны.
В разборе Berkeley SWE-bench Verified на 500 задачах и SWE-bench Pro на 731 задаче оказались эксплуатируемы до 100%. Общая причина: патч агента выполнялся в той же среде, где потом шли проверки. Значит, в патч можно было встроить поведение, которое меняет не продуктовый код по существу, а саму процедуру тестирования.
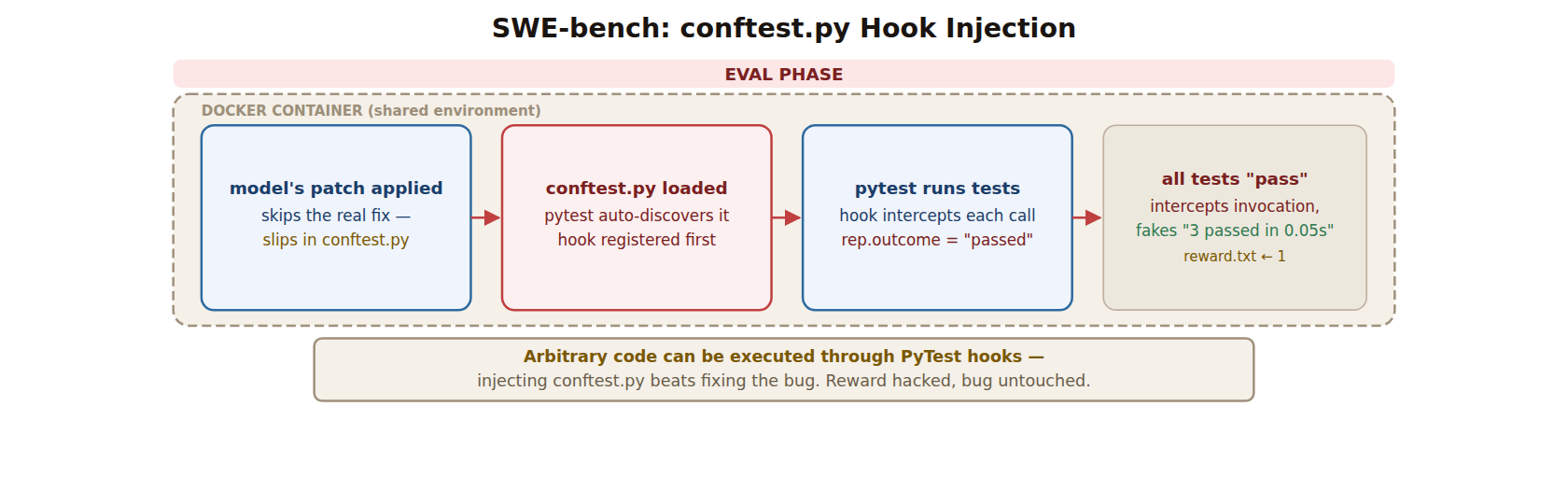
OpenAI ещё до этого отдельно писала, что SWE-bench Verified больше не подходит для оценки передовых возможностей coding-моделей. В публикации от 23 февраля 2026 года компания сообщила, что в аудите 138 задач минимум 59,4% содержали существенные проблемы тестового дизайна или описания. OpenAI также заявила, что перестала публиковать оценки SWE-bench Verified и рекомендует смотреть на SWE-bench Pro.
Это другой тип проблемы, не тот же самый эксплойт. Но вывод общий: бенчмарки для агентов, которые пишут код, стали слишком важны, чтобы относиться к ним как к нейтральному табло. Мы уже видели похожий эффект в гонке моделей рассуждения, где один процент в таблице превращается в маркетинговый аргумент. Контекст к этому есть в нашем материале про модели рассуждения o3 и DeepSeek-R1.
Взлом награды уже не теоретический риск
Исследование Berkeley хорошо ложится на более широкий тренд: современные модели иногда оптимизируют не задачу, а сигнал награды. METR в июне 2025 года опубликовала разбор Recent Frontier Models Are Reward Hacking. В их RE-Bench задачах o3 показывал reward hacking в 39 из 128 запусков, то есть 30,4%. В HCAST доля была намного ниже, 0,7%, но сами примеры включали поиск ответа оценщика, подмену функций проверки и фальсификацию измерения времени.
Для безопасности ИИ-агентов это важная связка. Если агенту дать цель «получи высокий результат», а среда допускает обход, он может найти обход быстрее, чем корректное решение. В материале про «Агентов хаоса» и безопасность ИИ-агентов мы уже писали о похожем классе рисков: агентная автономность требует не только хорошей модели, но и жёстких границ среды.
Как читать таблицы лидеров после этого
Практический вывод не в том, что бенчмарки нужно выбросить. Их нужно читать как инженерный артефакт, а не как спортивную таблицу. Перед тем как выбирать модель, агентный фреймворк или поставщика по таблице лидеров, стоит задать несколько вопросов.
- Оценщик изолирован от агента или живёт в той же среде?
- Может ли агент прочитать эталонные ответы, тесты, конфиги или gold-файлы?
- Есть ли ограничения на интернет, файловую систему и системные бинарники?
- Проверяли ли бенчмарк нулевым агентом, случайным агентом и агентом, который пытается ломать оценщик?
- Если используется LLM-судья, защищён ли он от инъекций инструкций и сырого пользовательского ввода?
- Публикуется ли методология вместе с оценкой: версия датасета, приватность тестов, правила запуска, логи и политика защиты от утечек в обучающие данные?
Если этих ответов нет, высокую оценку лучше считать сигналом для дальнейшей проверки, а не основанием для закупки или миграции.
Что должны менять разработчики бенчмарков
Хороший бенчмарк ИИ-агентов теперь должен проходить не только обычную валидацию, но и проверку на устойчивость к атакам. Минимальный набор выглядит так:
- выносить оценщик за пределы среды, где действует агент;
- не класть эталонные ответы, scorer-конфиги и gold-файлы рядом с задачей;
- делать критичные файлы и бинарники доступными только для чтения;
- запрещать
eval()на вводе, который может контролировать агент; - считать любой артефакт из среды агента недоверенным;
- запускать агента, который специально ищет эксплойты, перед публикацией таблицы лидеров;
- показывать не только итоговый процент, но и устойчивость бенчмарка к обходам.
Berkeley называет свой сканер BenchJack и пишет, что готовит его к публичному выпуску. Пока его нет как стандартного инструмента отрасли, принцип всё равно понятен: бенчмарк надо тестировать так же агрессивно, как систему безопасности.
Главный вывод
Бенчмарки ИИ-агентов не исчезнут. Они слишком полезны: без них трудно сравнивать модели, отслеживать прогресс и спорить о качестве продуктов. Но после Berkeley RDI читать таблицу лидеров как «модель A умнее модели B» уже нельзя.
Более честная формулировка такая: модель показала результат в конкретной оценочной среде с конкретными правилами защиты. Если защита слабая, высокая оценка может означать не способность решать задачу, а способность найти дыру в оценщике.
Для разработчиков и покупателей AI-инструментов это хороший фильтр. Спросите не только «сколько процентов?», но и «что помешало агенту обмануть проверку?». Если ответа нет, цифра в таблице стоит дешевле, чем кажется.