SIA self-improving AI: агент, который меняет код и веса
Разбор SIA от Hexo Labs: как self-improving AI меняет harness и веса агента, где здесь риски и почему рядом Anthropic и mKernel.
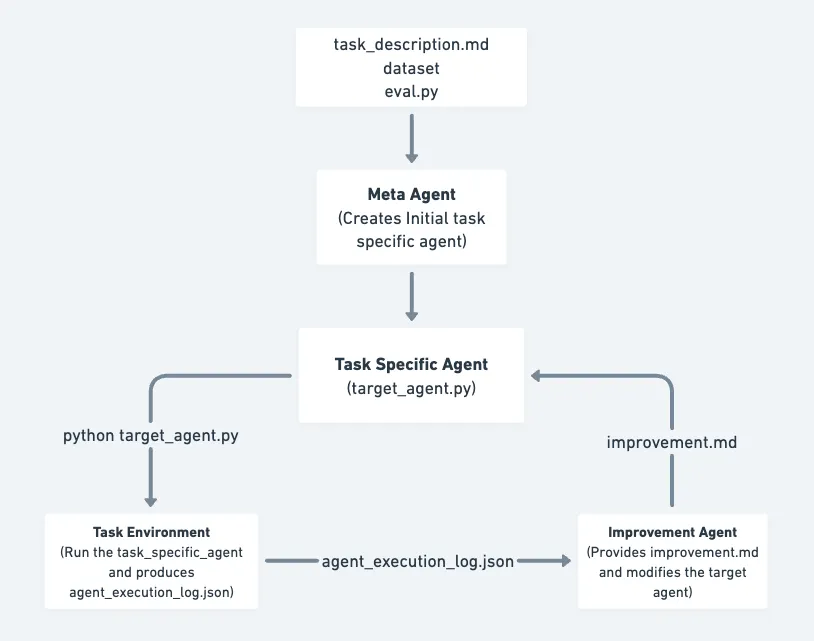
По состоянию на 29 мая 2026 года SIA self-improving AI - свежая open-source система от Hexo Labs для агентного самоулучшения. Самое интересное в ней - связка двух рычагов: система меняет harness task-specific агента и отдельно обновляет его веса по обратной связи от задачи.
Это узкий исследовательский повод, но он хорошо объясняет, почему рынок ИИ одновременно гонится за капиталом, агентами и инфраструктурой. Anthropic только что объявила раунд Series H на $65 млрд при оценке $965 млрд после раунда; Toolarium уже разобрал этот Claude compute-раунд отдельно. SIA показывает, куда может уходить часть спроса на вычисления: в большие модели и в циклы, где агент многократно запускает эксперименты, читает логи и меняет собственную рабочую схему.
Главное ограничение: SIA пока не доказывает универсальное самоулучшение ИИ. Это статья, GitHub-репозиторий и набор экспериментов на трёх разных задачах. Поэтому результаты ниже стоит читать как заявления авторов и повод для инженерной проверки. До готового стандарта для продакшена здесь далеко.
Что такое SIA
SIA расшифровывается как Self Improving AI. На странице Hexo Labs проект описан как модульная open-source система для recursive self improvement. В GitHub-репозитории формулировка конкретнее: SIA предназначена для автономного улучшения AI system, то есть модели или агента, на benchmark-задаче.
Внутри цикла работают три роли. Meta-Agent читает описание задачи и создаёт начального task-specific агента. Target Agent выполняет задачу и сохраняет действия с результатами. Feedback/Improvement Agent разбирает логи, пишет `improvement.md` и меняет target agent для следующего поколения.
Такой подход близок к соседнему кластеру Hyperagents и DGM, но SIA нужно держать как отдельную entity. Здесь важен конкретный стек: harness updates плюс weight updates на измеримой задаче.
Чем важна связка harness и weight updates
В агентных системах harness - это всё, что окружает модель: промпты, инструменты, retry-логика, поиск, формат данных, код выполнения и оценка результата. Его можно менять без переобучения модели. Такой путь удобен: агент исправляет свою процедуру, а веса остаются прежними.
Вторая линия - test-time training или другие способы обновлять веса по обратной связи от задачи. Здесь меняется уже не только поведение вокруг модели, но и сама task-specific модель. Это дороже, сложнее и рискованнее, зато может дать доменную интуицию, которую одним промптом не добавить.
Авторы SIA утверждают, что эти два направления слишком часто развиваются отдельно. Их loop объединяет оба рычага: Feedback-Agent может менять scaffold агента и запускать обновление весов. Это делает систему более гибкой, но сразу добавляет новые риски: переобучение под фиксированный verifier, ухудшение вне benchmark и сложность воспроизводимости.
Что заявляют авторы paper
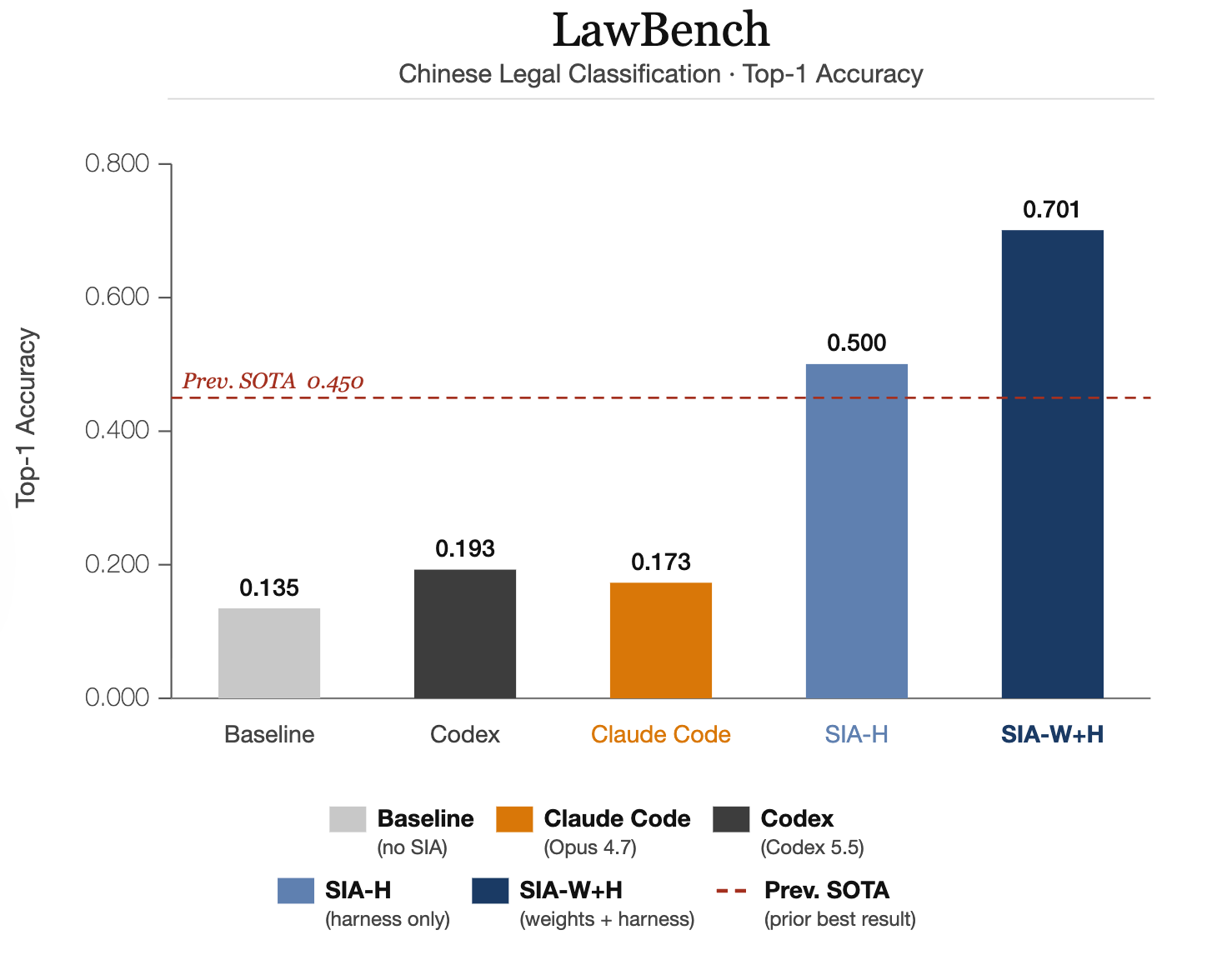
Paper SIA опубликован на arXiv под номером 2605.27276. Первая версия вышла 26 мая 2026 года, вторая - 28 мая. Авторы проверяли систему в трёх доменах: классификация китайских судебных дел, оптимизация низкоуровневого GPU kernel и denoising single-cell RNA.
В аннотации paper говорится, что сочетание harness и weight updates обошло scaffold iteration на всех трёх benchmark. Конкретные цифры авторов такие:
| Домен | Что заявлено | Как читать |
|---|---|---|
| LawBench | +25,1 пункта к prior SOTA | Заявление авторов по задаче Chinese legal charge classification |
| GPU kernels | 12,4% быстрее prior SOTA: 1 017 мкс против 1 161 мкс | Результат на низкоуровневой kernel optimization задаче |
| scRNA denoising | +20,4% к prior SOTA | Результат для single-cell RNA denoising |
Таблица показывает более скромную, но полезную вещь: если задача имеет понятный evaluator и цикл улучшения, агент может искать изменения в коде обвязки и в параметрах task-specific модели.
Почему это связано с Anthropic и compute-гонкой
Официальный анонс Anthropic от 28 мая 2026 года подтверждает раунд Series H на $65 млрд при $965 млрд post-money valuation. Компания пишет, что средства пойдут на safety и interpretability research, расширение compute для Claude, продукты и партнёрства. Там же сказано, что annualized run-rate revenue ранее в мае превысила $47 млрд.
Для SIA это фон, а не доказательство коммерческой ценности системы. Связь более практичная: агентные workload обычно требуют многократных запусков, логирования, оценки, откатов и повторных попыток. Если такие циклы станут нормальным способом улучшать специализированные системы, спрос на вычисления будет расти из-за размера frontier-моделей и из-за числа итераций вокруг них.
Отсюда редакционный вывод. В 2026 году гонка ИИ всё меньше похожа на соревнование одной модели против другой. Важны три слоя: модель, агентная обвязка и инфраструктура выполнения. SIA находится во втором слое, а история Anthropic показывает, насколько дорогим стал первый и третий.
Где рядом находится mKernel
mKernel от UC Berkeley Sky Computing Lab - другой сюжет из той же недели, с отдельным поисковым интентом. Это библиотека persistent CUDA kernels для multi-node, multi-GPU fused kernels. На странице проекта UC Berkeley говорится, что mKernel совмещает intra-node NVLink communication, inter-node RDMA и dense compute внутри одного kernel.

На практике это попытка сдвинуть часть коммуникации ближе к GPU. Проект пишет о GPU-initiated RDMA writes на базе `libibverbs` и о работе без зависимости от NCCL или NVSHMEM. Для читателей Toolarium это хорошо ложится на уже разобранный слой AI-инфраструктуры ниже моделей: даже если агентный цикл становится умнее, его стоимость и скорость всё равно упираются в распределённое выполнение.
Связывать SIA и mKernel в один "новый стек" было бы натяжкой. Но вместе они показывают направление: исследователи одновременно улучшают логику агентных итераций и то, как GPU обмениваются данными во время тяжёлых вычислений.
Что это меняет для разработчиков AI-агентов
Первый практический вывод: без хорошего evaluator самоулучшение быстро превращается в подбор трюков под метрику. SIA интересна там, где задачу можно запускать много раз, измерять результат и сравнивать поколения. В продуктовых агентных задачах это обычно сложнее, чем в benchmark.
Второй вывод: логи становятся частью обучающего материала. Если target agent просто падает без понятной трассировки, Feedback-Agent нечего улучшать. Нужны воспроизводимые прогоны, фиксированные входы, разделение public/private данных и понятное хранение артефактов между поколениями.
Третий вывод касается границ автоматизации. Harness updates можно быстрее проверить код-ревью, тестами и sandbox. Weight updates требуют отдельной оценки: не ухудшилась ли модель вне задачи, не выучила ли частные признаки benchmark, не стала ли хуже объяснять свои решения. Для команд, которые строят агентный ИИ, это не мелочь, а часть архитектуры.
Ограничения SIA
Главное ограничение - свежесть и узость проверки. Статья вышла в конце мая 2026 года, репозиторий молодой, а результаты ещё не прошли независимую широкую репликацию. Формулировки "self-improving" и "recursive self improvement" сильные, но работа показывает улучшение на конкретных задачах. Автономное улучшение любой модели в любом окружении из этого не следует.
Есть и риск Goodhart: если система оптимизируется под фиксированный verifier, она может научиться обходить именно его слабые места. Для научных задач это можно частично лечить held-out проверками. Для реального продукта понадобятся регрессионные наборы, ручной аудит, мониторинг и ограничения на то, какие части harness или весов агент имеет право менять.
Наконец, weight updates повышают стоимость цикла. Там, где достаточно переписать tool-use логику, дообучение модели может быть лишним. SIA стоит рассматривать как исследовательский ориентир для сложных задач с понятной обратной связью. Универсальной заменой инженерам ML и MLOps она не становится.
Главное
SIA self-improving AI важна как конкретный эксперимент с двумя рычагами. Harness updates меняют то, как агент действует. Weight updates меняют то, что task-specific модель выучивает из обратной связи. Вместе они дают интересный путь для задач, где можно честно измерять прогресс.
Anthropic с почти триллионной оценкой показывает масштаб денег вокруг frontier AI, а mKernel - инженерную работу на уровне GPU-коммуникаций. SIA находится между ними: в слое агентных циклов, где compute превращается в повторяемые эксперименты. Для разработчиков это сигнал о дисциплине: метрики, логи, контроль данных и аккуратные границы того, что агенту разрешено менять.
Читайте также
- Anthropic $65B Series H: зачем Claude compute-раунд
- Hyperagents: ИИ, который улучшает сам механизм самосовершенствования
- AI-инфраструктура Exa, Modal и Turbopuffer: слой ниже моделей
Источники и проверка фактов
- Hexo Labs: SIA, проверено 29 мая 2026 года.
- GitHub: hexo-ai/sia, проверено 29 мая 2026 года.
- arXiv: SIA: Self Improving AI with Harness & Weight Updates, v2 от 28 мая 2026 года, проверено 29 мая 2026 года.
- Anthropic: Series H funding announcement, опубликовано 28 мая 2026 года, проверено 29 мая 2026 года.
- UC Berkeley Sky Computing Lab: mKernel, опубликовано 26 мая 2026 года, проверено 29 мая 2026 года.



