AI-инфраструктура Exa, Modal и Turbopuffer: слой ниже моделей
Exa, Modal и Turbopuffer показывают новую экономику AI-инфраструктуры: рынок платит за поиск, контекст, sandboxes и runtime для агентов.
Проверено 27 мая 2026 года. AI-инфраструктура Exa, Modal и Turbopuffer стала хорошим срезом того, за что рынок готов платить в 2026-м. Не только за новую модель. Деньги уходят в поиск для агентов, изолированные среды выполнения, GPU-вычисления и слой retrieval, который кормит модели свежим контекстом.
Инфоповод собрал Latent Space / AINews 22 мая 2026 года: Exa объявила Series C на $250 млн при оценке $2,2 млрд, Modal подняла $355 млн при post-money оценке $4,65 млрд, а по Turbopuffer одновременно пошёл сигнал про $100 млн annualized revenue и прибыльность. Последняя цифра не из официального пресс-релиза компании: её стоит читать как рыночную оценку Sacra и Latent Space, а не как аудированную отчётность.
Но важнее не сами суммы. Важнее то, что все три компании продают слой ниже пользовательского AI-продукта. Если модель можно поменять через API, то инфраструктура вокруг неё становится местом, где реально копится ценность: данные, latency, безопасность выполнения кода, стоимость поиска и удобство для разработчиков.
Что именно произошло
| Компания | Свежий сигнал | Что она продаёт | Источник |
|---|---|---|---|
| Exa | $250 млн Series C при оценке $2,2 млрд, 20 мая 2026 года | Поиск, crawling, извлечение контента и research API для AI-приложений | официальный блог Exa |
| Modal | $355 млн Series C при post-money оценке $4,65 млрд, 21 мая 2026 года | Serverless GPU/AI cloud, inference, batch jobs, sandboxes и runtime для агентов | официальный блог Modal |
| Turbopuffer | Оценка Sacra: $100 млн annualized revenue в марте 2026 года; Latent Space отдельно пишет про $100 млн ARR и прибыльность | Serverless vector, full-text и hybrid search поверх object storage | Sacra, Latent Space / AINews, документация Turbopuffer |
Таблица не про «кто круче». У компаний разные рынки и разные доказательства. Exa и Modal дали официальные анонсы раундов. Turbopuffer публично интересен другим: если оценки Sacra близки к реальности, retrieval-инфраструктура может расти как самостоятельный бизнес даже без привычного венчурного прожектора.
Exa: поиск становится API для агентов
Exa формулирует себя довольно прямо: «search engine made for AIs». В документации у компании четыре базовые функции: поиск страниц, получение чистого и свежего HTML из результатов, прямые ответы через Answer API и автоматизированное web research с JSON-результатами и ссылками на источники.
В анонсе Series C Exa пишет, что уже работает с Cursor, Cognition, HubSpot, OpenRouter, Monday.com и более чем 400 000 разработчиков. Компания также заявляет, что её crawlers отслеживают более 500 млрд URL, а инфраструктуру после раунда собираются масштабировать до сотен тысяч поисковых запросов в секунду.
Для обычного пользователя поиск выглядит как поле ввода. Для агента это уже не поле, а рабочий орган. Агенту нужно находить страницы, доставать содержимое, проверять свежесть, различать техническую документацию и маркетинговый шум. В этом смысле Exa продаёт не «ещё один Google», а backend для программ, которые сами ходят по вебу и принимают решения.
Отсюда и связь с более широким рынком: enterprise AI всё чаще упирается не в красивый чат, а в доступ к данным и deployment. Мы уже разбирали этот сдвиг в материале про enterprise AI инфраструктуру: когда модель попадает в production, рядом быстро появляются вопросы стоимости, свежести контекста, прав доступа и наблюдаемости.
Modal: агентам нужен runtime поверх API
Modal закрывает другой кусок цепочки. В официальном анонсе компания пишет о $355 млн Series C, росте выручки в пять раз с сентября 2025 года и annualized revenue выше $300 млн. Раунд вели General Catalyst и Redpoint, а оценка после сделки составила $4,65 млрд.
Техническая часть здесь интереснее финансовой. Modal описывает себя как AI infrastructure platform: низколатентный inference, массовые batch jobs, обучение и fine-tuning на GPU, GPU-backed notebooks и тысячи изолированных sandboxes для выполнения AI-generated code. В блоге Modal отдельно подчёркивает, что sandboxes стали first-class primitive после того, как разработчики начали запускать сгенерированный код на платформе ещё в 2023 году.
Это важная деталь для рынка агентов. Пока агент только пишет текст, ему хватает модели. Как только он запускает код, делает research, тестирует гипотезы, вызывает инструменты и работает с внешними данными, ему нужна безопасная среда выполнения. Без неё «автономность» превращается в демонстрацию на ноутбуке, которую страшно пускать к реальным системам.
Поэтому Modal стоит рядом с темами, которые на первый взгляд кажутся отдельными: vLLM, inference engines, RL environments, sandbox security, developer experience. Это та же причина, по которой вокруг AI-native tooling появляются специализированные продукты для научных и R&D-команд, как в нашем разборе OpenArx. Чем больше агент делает сам, тем важнее контур, в котором он это делает.
Turbopuffer: контекст стал отдельным продуктом
Turbopuffer показывает третий слой: retrieval. В старой формуле RAG часто звучал как «положим документы в векторную базу и будем искать по смыслу». В production всё жёстче. Нужны дешёвое хранение, предсказуемая задержка, фильтры, полнотекстовый поиск, hybrid search, права доступа и поведение, которое можно объяснить инженеру после инцидента.
По данным Sacra, Turbopuffer вырос до $100 млн annualized revenue в марте 2026 года. В том же отчёте говорится, что компания начинала как дешёвый serverless vector search для RAG, а затем добавила full-text и hybrid search для agentic search по кодовым базам, тикетам, документам, транскриптам и клиентским данным. Latent Space в выпуске AINews от 22 мая отдельно фиксирует $100 млн ARR и прибыльность.
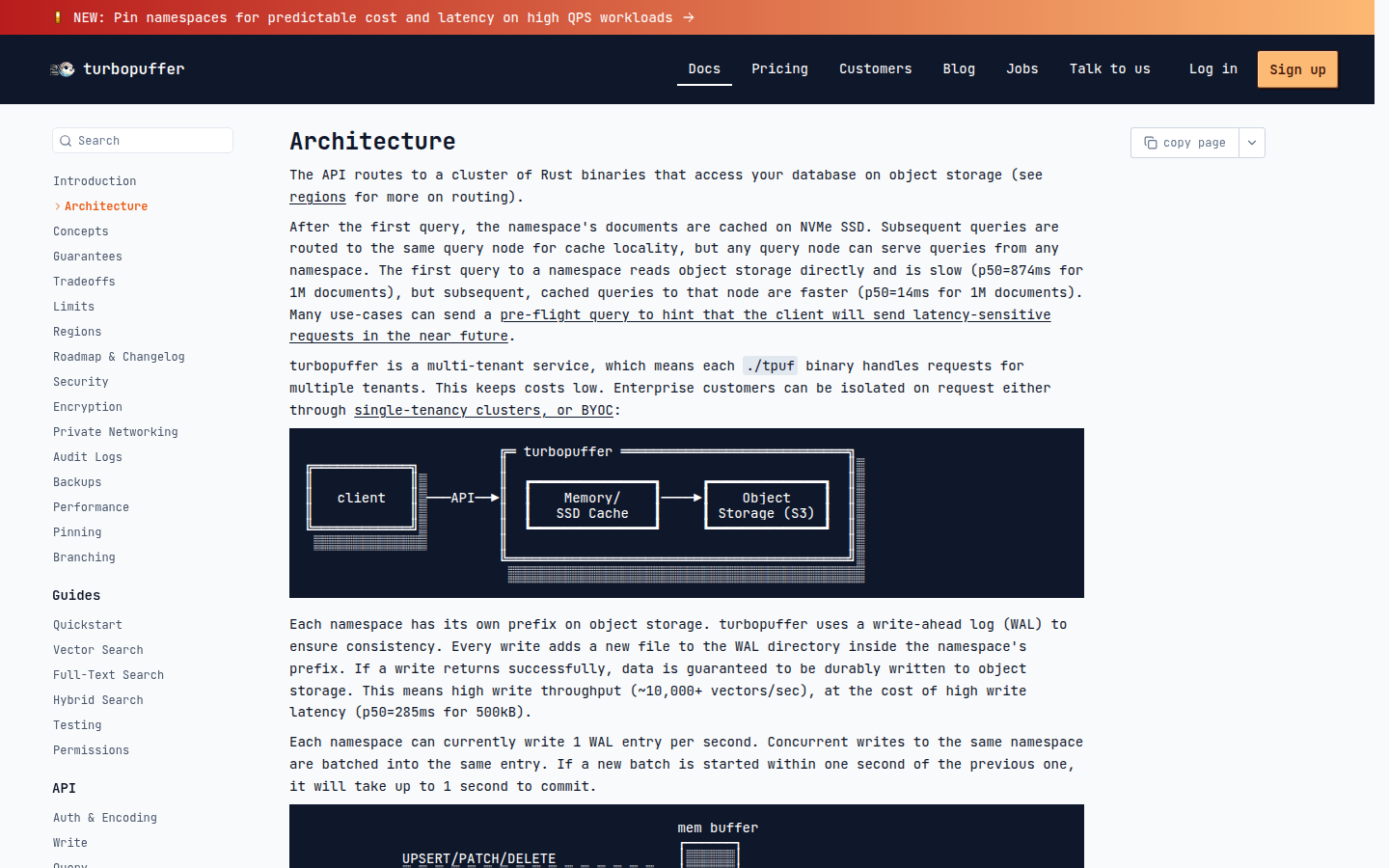
Официальная документация Turbopuffer объясняет, почему этот подход вообще отличается от классического «держим индекс на горячих серверах». API маршрутизирует запросы к Rust-бинарям, база лежит в object storage, после первого запроса документы namespace кэшируются на NVMe SSD. В примере документации первый запрос к 1 млн документов даёт p50 около 874 мс, а последующие cached-запросы к тому же узлу — около 14 мс.
Для читателя Toolarium это должно звучать знакомо: мы уже разбирали векторные базы данных для RAG, но Turbopuffer интересен не как ещё один пункт в списке. Он показывает, что retrieval перестал быть вспомогательной таблицей рядом с LLM. Это самостоятельный слой продукта, где экономия на хранении, cold start, точность фильтров и гибридный поиск напрямую влияют на себестоимость AI-функций.
Почему эти три истории сложились в один сигнал
Exa, Modal и Turbopuffer не конкурируют лоб в лоб. Их полезнее читать как три уровня одной production-цепочки:
- Exa помогает агенту найти и извлечь актуальную информацию из внешнего мира.
- Modal даёт среду, где агент может выполнить код, запустить inference, масштабировать batch-задачу или поднять sandbox.
- Turbopuffer хранит и ищет контекст, который нужен агенту или AI-приложению между вызовами модели.
Именно поэтому широкий заголовок «рынок AI-инфраструктуры растёт» был бы слабым. Растёт не абстрактная инфраструктура, а конкретные узкие слои вокруг агентов: поиск, память, безопасное выполнение, вычисления и инструменты разработчика. Каждый из этих слоёв снимает боль, которую нельзя решить просто покупкой более сильной модели.
Для команд это меняет архитектурный разговор. Вопрос «какую LLM выбрать» остаётся важным, но всё чаще он идёт вторым. Сначала приходится понять, где будут жить данные, как агент получит свежий контекст, где он выполнит небезопасный код, как быстро можно масштабировать inference и сколько будет стоить каждая итерация пользователя.
Где здесь осторожность
У этой истории есть несколько ограничений. Во-первых, не все цифры одинакового качества. Exa и Modal сами раскрыли суммы раундов и оценки. По Turbopuffer публичная картина строится на оценке Sacra и пересказе Latent Space; сигнал сильный, но это не официальный audited ARR.
Во-вторых, valuation не доказывает монополию. Инфраструктурные рынки быстро притягивают конкурентов, а часть функций может уехать в облака, open-source или внутрь крупных AI-платформ. То, что сегодня выглядит как отдельная компания, завтра может стать функцией в hyperscaler stack.
В-третьих, агентная инфраструктура пока взрослеет вместе с самими агентами. Если автономные рабочие процессы окажутся уже, чем рынок ожидает, спрос на sandboxes, long-running compute и специализированный retrieval будет расти медленнее. Текущие сделки всё же показывают, что инвесторы и клиенты уже платят за production-слой, а не за одни демонстрации.
Что это значит для разработчиков и менеджеров
Практический вывод простой: AI-продукт в 2026 году нельзя проектировать как «модель плюс интерфейс». Минимальный production-стек всё чаще выглядит иначе: модель, retrieval, поиск по внешним источникам, sandbox для действий, вычислительный слой, мониторинг, права доступа и бюджетирование.
Для разработчиков это хороший сдвиг. Ценность снова смещается в engineering: как собрать контур, где модель получает правильные данные, действует в безопасной среде и не сжигает бюджет на каждом шаге. Для менеджеров вывод жёстче: покупка доступа к frontier-модели больше не равна AI-стратегии. Нужно понимать, какой слой инфраструктуры даёт преимущество именно вашему продукту.
История Exa, Modal и Turbopuffer хороша тем, что она без лишнего пафоса показывает новую экономику AI. Модели остаются центром внимания, но деньги всё чаще уходят туда, где модель подключается к миру: в поиск, контекст, выполнение и масштабирование. Именно там AI-продукт перестаёт быть демо и начинает работать как система.



