Векторные базы данных для RAG: как выбрать Qdrant, Weaviate, Pinecone, pgvector и Chroma
Как выбрать Qdrant, Weaviate, Pinecone, pgvector и Chroma для RAG: где хватает Postgres, когда нужен managed retrieval и зачем важны фильтры.
Проверено 11 мая 2026 года. Векторная база данных для RAG не делает систему «умной». Она решает более приземлённую задачу: быстро и предсказуемо найти нужные фрагменты данных по смыслу, с фильтрами, изоляцией и приемлемой задержкой. Если поисковый слой слабый, хорошая модель всё равно будет отвечать по мусорному контексту.
Поэтому выбирать между Qdrant, Weaviate, Pinecone, pgvector и Chroma лучше не по моде и не по количеству звёзд на GitHub. Полезнее другой вопрос: где живут ваши данные, нужен ли отдельный поисковый слой, насколько важны гибридный поиск и фильтры, есть ли многопользовательская изоляция и кто будет сопровождать это через полгода. Если вам нужен базовый контур RAG, а не выбор векторной базы, сначала откройте гайд по RAG и практический разбор поиска с эмбеддингами в приложении. Здесь разбираем именно поисковый слой.
Что векторная база делает в RAG на самом деле
Она хранит эмбеддинги и связанные с ними метаданные, а потом помогает ответить на простой вопрос: какие куски стоит отдать модели в контекст прямо сейчас. На этой точке и начинаются инженерные развилки.
- Как фильтровать результаты по tenant, документу, типу данных или времени.
- Как совмещать векторный поиск с лексическим, когда одной семантики недостаточно.
- Как работать с обновлениями, чтобы поиск не отставал от живых данных.
- Как держать баланс между recall, задержкой и стоимостью сопровождения.
Именно здесь продукты расходятся по-настоящему. Один делает ставку на гибридный поиск, другой — на управляемую многопользовательскую изоляцию, третий — на то, что у вас уже есть Postgres и вы не хотите вытаскивать данные в отдельный сервис без серьёзной причины.
Почему «хранить векторы» недостаточно
Тонкие материалы про RAG часто выглядят одинаково: эмбеддинг, запрос, ближайшие соседи, ответ модели. В продакшене этого мало. Нужны фильтры, изоляция, повторяемость и понятное объяснение, почему именно эти документы попали в контекст.
Хороший пример — pgvector. В README прямо сказано, что с approximate index filtering фильтрация применяется уже после сканирования индекса. Если условию соответствует 10% строк, а hnsw.ef_search оставлен по умолчанию, вы просто получите меньше подходящих результатов, чем ожидали. Начиная с 0.8.0, для этого добавили iterative index scans. Это важная практическая мысль: retrieval может «плавать» не потому, что эмбеддинги плохие, а потому, что индекс и фильтрация настроены не под вашу нагрузку.
Сравнение пяти вариантов
| Система | Что подтверждает документация | Когда брать |
|---|---|---|
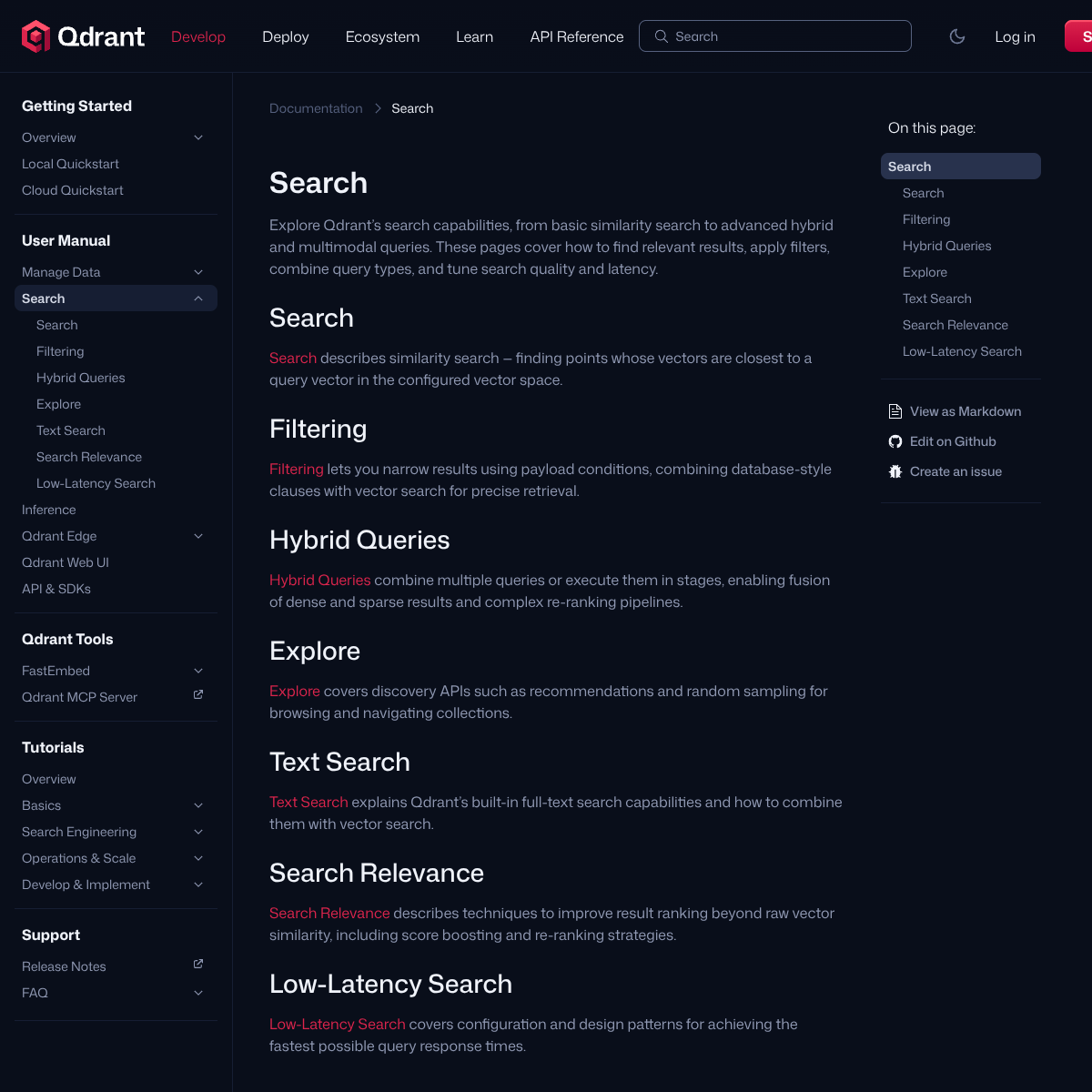
| Qdrant | Similarity search, payload filtering, hybrid queries, text search, relevance tuning и паттерны низкой задержки описаны как единый поисковый слой. | Когда нужен самостоятельный поисковый сервис с сильным упором на фильтры, dense+sparse-поиск и контроль над ранжированием. |
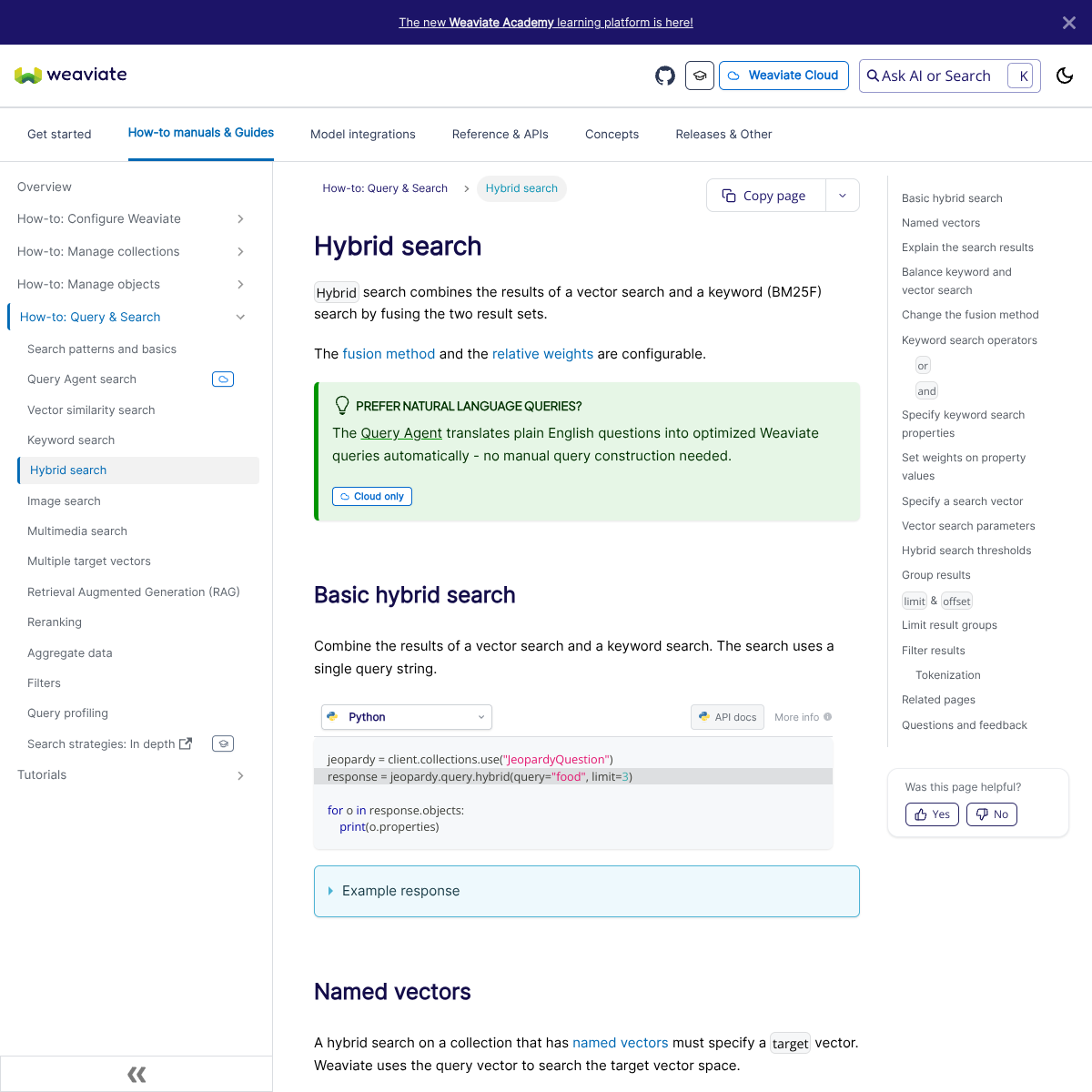
| Weaviate | Hybrid search совмещает vector search и BM25F, а документация отдельно описывает weights, fusion methods, thresholds и filters. | Когда нужен более высокий уровень готовых поисковых абстракций и понятный путь к hybrid search без собственной сборки поверх базы. |
| Pinecone | Search Overview разводит dense, sparse, full-text и hybrid search, а изоляция клиентов строится на namespaces в serverless-архитектуре. | Когда нужен управляемый retrieval-контур для SaaS с многопользовательской изоляцией и без своей операционной команды вокруг поиска. |
| pgvector | Поиск живёт внутри Postgres; есть exact search, HNSW, IVFFlat, iterative scans, JOINs, транзакции и привычная операционная модель. | Когда данные уже в Postgres и вы хотите добавить retrieval без ввода отдельной поисковой базы раньше времени. |
| Chroma | Есть where filters по метаданным и документам, а persistent client хранит данные локально на диске. | Когда нужен быстрый локальный старт, быстрый прототип или внутренний инструмент без тяжёлого инфраструктурного следа. |
Qdrant и Weaviate: когда нужен отдельный поисковый слой
Qdrant и Weaviate интересны тем, что у обоих retrieval описан не как побочная функция, а как центральный сценарий. У Qdrant на одной оси собраны search, filtering, hybrid queries, text search и relevance. У Weaviate hybrid search прямо комбинирует vector search и BM25F и даёт ручки вроде alpha, fusion method и гибридных threshold-ов.
Практический вывод здесь скучный, но полезный. Если поиск — не вспомогательная игрушка, а отдельная продуктовая возможность, такие системы обычно дают больше контроля, чем «просто положить векторы в знакомую БД». Особенно когда речь идёт о внутренней базе знаний, корпоративном поиске или RAG с фильтрами по ролям, документам и типам данных. В научном корпусе похожая логика проявляется в OpenArx как AI-native инфраструктуре для R&D, где retrieval должен сохранять связь с источниками, методиками и проверяемыми фрагментами.
Pinecone: когда важнее управляемая многопользовательская изоляция
Pinecone лучше читать через две страницы сразу: Search Overview и документацию по multitenancy. В первой он разводит dense, sparse, full-text и hybrid search. Во второй прямо пишет, что namespaces в serverless-архитектуре дают изоляцию tenant data, отсутствие шумных соседей и более дешёвые запросы, потому что каждая операция бьёт только по одному namespace.
Для SaaS это сильный аргумент: поисковый слой не хочется превращать в источник случайных ошибок между клиентскими контурами. Но у Pinecone есть и архитектурная оговорка. Search Overview отдельно называет eventual consistency. Для части команд это нормальная цена за управляемый контур. Для других, где новые документы должны появляться в ответах почти мгновенно, это уже ограничение, которое надо принимать осознанно.
pgvector: самый прагматичный старт, если вы уже в Postgres
Самая недооценённая мысль в обсуждениях vector DB звучит так: если ваши данные и так живут в Postgres, новая база нужна не всегда. pgvector даёт exact и approximate nearest neighbor search, несколько метрик расстояния, HNSW и IVFFlat, а вместе с ними остаются JOINs, транзакции, PITR и привычная операционная модель Postgres.
Но за эту прагматику есть плата. Retrieval внутри Postgres проще начать, чем масштабировать бездумно. Если вы упираетесь в тяжёлую гибридную логику, сильную многопользовательскую изоляцию, сложный reranking или выделенную поисковую команду, отдельный поисковый сервис начинает окупаться быстрее.
Chroma: когда важен локальный старт
Chroma удобен тем, что не заставляет сразу выбирать большой стек. В документации есть where filters по метаданным и содержимому документов, а persistent client для Python хранит данные на диске. Это делает его понятным вариантом для лаборатории, desktop-инструмента или быстрого внутреннего прототипа.
Здесь важна правильная оговорка. Chroma не «плохой», он просто отвечает на другой тип старта. Если вам нужно быстро доказать retrieval-логику локально, он уместен. Если вы обсуждаете поиск как долгую продуктовую основу со сложной изоляцией и требованиями к сопровождению, это уже другой разговор.
Как выбирать по типу операционной модели
| Ситуация | Лучший старт | Почему |
|---|---|---|
| Все данные уже в Postgres, команда сильна в SQL | pgvector | Самый короткий путь до первого рабочего поиска без отдельной поисковой инфраструктуры. |
| Нужен управляемый контур поиска для SaaS с изоляцией клиентов | Pinecone | Namespaces и serverless-модель прямо заточены под многопользовательский контур. |
| Нужны гибридный поиск, фильтры и поисковый слой как отдельная продуктовая функция | Qdrant или Weaviate | Обе системы дают поисковый слой как основной сценарий, а не как побочную надстройку. |
| Нужен быстрый локальный прототип | Chroma | Минимальный порог запуска и достаточно функций, чтобы проверить идею без тяжёлого операционного следа. |
Есть и типичные триггеры миграции. Из pgvector команды обычно уходят, когда retrieval становится отдельным продуктовым слоем, а не функцией рядом с данными. Из Chroma — когда локальный прототип превращается в многопользовательский сервис. Из Pinecone — когда eventual consistency и стоимость управляемого контура перестают укладываться в требования продукта. А выбор между Qdrant и Weaviate чаще упирается не в маркетинг, а в то, сколько готовых поисковых абстракций вам нужно прямо сейчас.
Главный вывод
Самая частая причина слабого RAG — не «не та модель» и не «не та база», а то, что поисковый слой выбрали по моде. Векторная база должна совпадать с типом вашей нагрузки: где лежат данные, как вы фильтруете доступ, насколько вам нужен гибридный поиск и кто будет это сопровождать через полгода.
Если смотреть с этой стороны, ответ обычно становится скучным, но полезным. Не всегда нужен Pinecone. Не всегда нужен отдельный Qdrant-кластер. И точно не всегда надо тащить векторный поиск в отдельный сервис в день, когда вы только доказали, что RAG вообще приносит пользу. Для следующего слоя над поиском посмотрите и наш разбор LangChain vs LlamaIndex для production RAG: там уже вопрос не про базу, а про orchestration.
Источники и дата проверки
Факты по hybrid search, изоляции клиентов, filters, persistent client и индексам сверены 11 мая 2026 года по официальной документации Qdrant, Weaviate, Pinecone, pgvector и Chroma.
- Qdrant Search — similarity search, filtering, hybrid queries, text search, relevance и паттерны низкой задержки.
- Weaviate Hybrid Search — BM25F + vector search, fusion method, weights, thresholds и filters.
- Pinecone Search Overview — dense, sparse, full-text и hybrid search, а также eventual consistency.
- Pinecone Implement Multitenancy — namespaces, tenant isolation и serverless-архитектура.
- pgvector README — HNSW, IVFFlat, filtering, iterative index scans и поведение approximate indexes.
- Chroma Where Filters — фильтры по метаданным и документам.
- Chroma Python Client — persistent client с хранением данных на диске.