AI-агенты OpenArx: AI-native инфраструктура для науки и R&D-команд Как OpenArx строит MCP-инфраструктуру для научных ИИ-агентов: индекс статей, профили, ограничения alpha и смысл для R&D.
RAG USER2-base догнала OpenAI в юридическом RAG-бенчмарке На корпусе судебной практики USER2-base не уступила OpenAI text-embedding-3-large. Разбираем, что это меняет для русскоязычного юридического RAG.
кейсы AI-ассистент для колл-центра за 6 месяцев: как 12 бэкендеров без ML-опыта вывели проект в пилот Российская компания построила голосового AI-ассистента «Суфлёр» силами 12 бэкендеров без ML-опыта. RAG вместо fine-tuning, Qwen 8B вместо облачного GPT, задержка 2 секунды.
LLM Как настроить локальную языковую модель: полное руководство по Ollama, LM Studio и не только Пошаговое руководство по настройке локальных языковых моделей: Ollama, LM Studio, Open WebUI. Выбор железа и моделей, квантизация, RAG, подключение через API — всё, чтобы запустить свой AI без облака.
RAG LangChain vs LlamaIndex: что выбрать для production RAG в 2026 году LangChain vs LlamaIndex для production RAG: где важнее orchestration, data layer, observability и когда выгоднее гибридный стек.
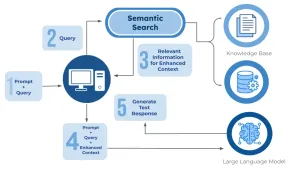
разработка Как встроить ИИ-поиск в приложение с эмбеддингами Практическое руководство: как добавить семантический поиск в приложение с помощью эмбеддингов и векторных баз данных.
LLM RAG: что это и когда он действительно нужен Техническая опорная страница по RAG внутри LLM-кластера: когда retrieval действительно нужен, где достаточно длинного контекста и куда идти за базами, метриками и прикладными сценариями.