USER2-base догнала OpenAI в юридическом RAG-бенчмарке
На корпусе судебной практики USER2-base не уступила OpenAI text-embedding-3-large. Разбираем, что это меняет для русскоязычного юридического RAG.

По состоянию на 2 мая 2026 года главный вывод из свежего русскоязычного бенчмарка по юридическому RAG звучит не как очередная мантра про open source, а куда приземлённее. На корпусе судебной практики локальная deepvk/USER2-base не показала статистически значимого отставания от text-embedding-3-large от OpenAI. Для команд, которые строят поиск по договорам, искам и судебным актам на русском, это важный сдвиг: у локального стека появился не только идеологический, но и измеримый аргумент.
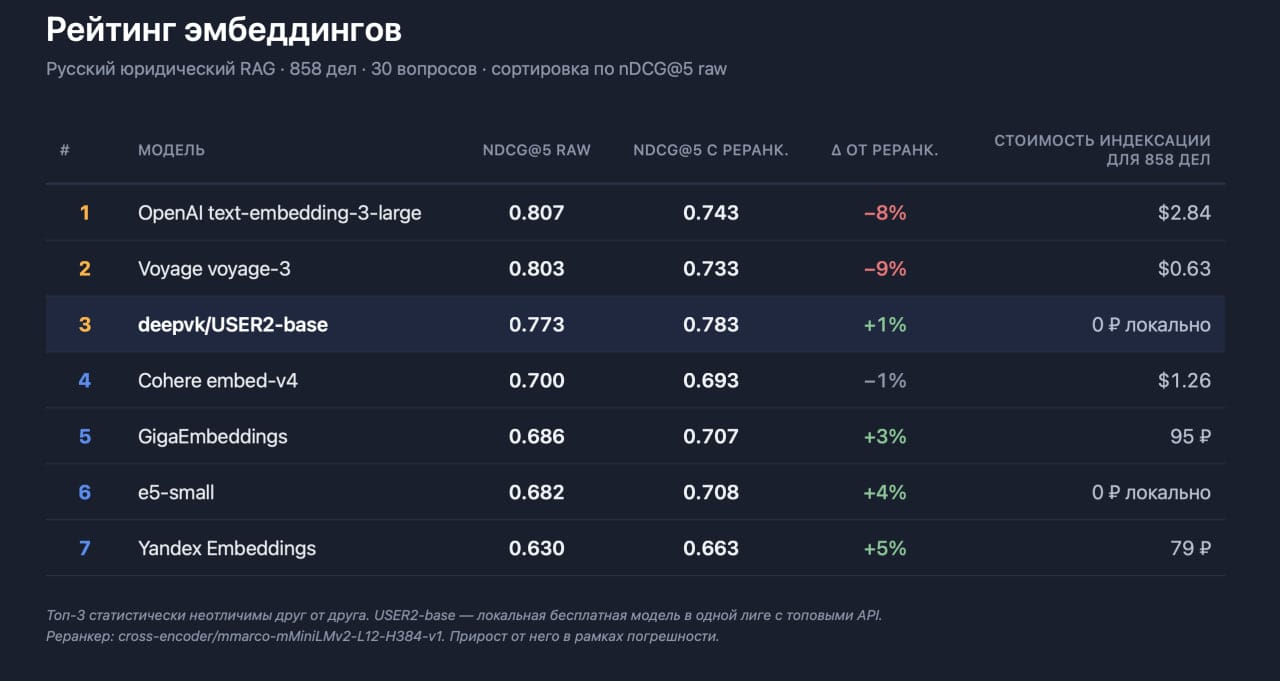
Источник новости не пресс-релиз вендора, а прикладной тест на Хабре. Автор сравнил семь эмбеддингов и четыре реранкера на корпусе из 858 актов Суда по интеллектуальным правам и 30 запросов. Лидерами на этой выборке стали OpenAI, Voyage и USER2-base, причём автор отдельно подчёркивает: внутри этой тройки различия попадают в доверительный интервал. Иначе говоря, речь не о победе по всем фронтам, а о том, что локальная русскоязычная модель вышла на уровень, где её уже нельзя списывать как дешёвый компромисс.
Это важно ещё и потому, что новость ложится ровно в российский контекст. Когда поисковый контур строится на внешнем API, команда зависит не только от качества модели, но и от оплаты, доступности сервиса и юридических рисков. Поэтому история с USER2-base интересна не как красивый график, а как более реалистичный вариант для продакшн-сценариев, где данные и инфраструктура должны оставаться в локальном контуре.
Что именно показал юридический RAG-бенчмарк
В оригинальном тесте автор взял узкий, но очень показательный домен: судебную практику по интеллектуальным правам. Это не абстрактный набор текстов "про юриспруденцию вообще", а корпус, где терминология, типы споров и нормы права повторяются достаточно регулярно. Для retrieval-задач это важно: модель должна не просто понимать русский язык, а поднимать в топ именно те документы, где совпадают объект права, тип спора и применимая норма.
Методика тоже заслуживает внимания. В тесте было 30 запросов разной сложности, от типовых до узких. Для каждой из семи моделей эмбеддингов брали топ-20 документов, объединяли результаты с дедупликацией и получали пул из 2751 пар вопрос-документ. Разметка шла до реранкинга, а не после него, чтобы не занизить качество сырой выдачи. Основной метрикой стал nDCG@5, то есть качество именно верхушки выдачи, которую пользователь реально видит первой. Автор отдельно уточняет, что API-модели тестировались в марте 2026 года, и цены с временем индексации относятся к той дате.
| Параметр | Что известно из источника | Почему это важно |
|---|---|---|
| Корпус | 858 актов Суда по интеллектуальным правам + часть 4 ГК РФ | Выводы относятся к узкому русскоязычному юридическому домену, а не ко всем документам подряд. |
| Запросы | 30 вопросов разной сложности | Этого хватает для сильного сигнала, но мало для универсального рейтинга без оговорок. |
| Метрика | nDCG@5 |
Проверяется не просто наличие релевантного документа, а качество топ-5 выдачи. |
| Ключевой результат | OpenAI, Voyage и USER2-base образуют топ-группу без статистически значимого отрыва | Именно это даёт повод говорить о локальной альтернативе, а не просто о "неплохой русской модели". |
| Практическая связка | USER2-base + jina-reranker-v3 даёт 0.797 по nDCG@5; OpenAI raw — 0.809 |
Разрыв на этой выборке автор считает находящимся в пределах погрешности. |
Самая сильная часть этой истории в том, что вывод здесь не строится на туманном "ощущении качества". Автор честно пишет про доверительные интервалы, маленькую выборку и ограничения разметки через NotebookLM. И именно на этом фоне видно, почему новость заслуживает внимания: даже при осторожной трактовке результатов USER2-base уже находится не в запасной лиге, а в верхней группе рядом с коммерческими API-моделями.
Если нужен базовый разбор самого retrieval-контура, у нас есть отдельный материал о том, как устроен RAG и где он нужен в продакшне. Здесь же фокус уже не на архитектуре пайплайна, а на том, какая embedding-модель даёт более сильный старт в узком домене.
Почему USER2-base стала важнее именно сейчас
У deepvk/USER2-base есть три свойства, которые делают её заметной не только на графике. Во-первых, это русскоязычная модель с длинным контекстом до 8192 токенов. Во-вторых, она локальная: нет API-зависимости на каждом запросе и нет отдельного внешнего контура для индексации. В-третьих, у неё понятная инженерная упаковка: модель лежит на Hugging Face, построена на RuModernBERT-base и доступна под лицензией Apache-2.0.
На этом фоне OpenAI остаётся сильным, но уже не безальтернативным вариантом. По официальной странице OpenAI, text-embedding-3-large сейчас стоит $0.13 за 1 млн токенов и позиционируется как самая сильная embedding-модель компании. Это не делает её дорогой в абсолюте, особенно для небольших индексов. Но логика расходов у облачного retrieval всё равно другая: вы платите за индексацию, за пересчёт новых документов, за эмбеддинги входящих запросов, а вдобавок живёте в контуре доступности внешнего поставщика.
Для российских команд это не абстрактный довод из серии "данные лучше держать у себя". Если проект завязан на судебные документы, внутренние базы, переписку по спорам или договорный контур, локальная модель часто нужна не ради моды на open source, а ради банальной управляемости. Именно поэтому бенчмарк на Хабре выглядит важным маркером. Он показывает, что локальный базовый вариант для русскоязычного юридического RAG теперь можно выбирать не на веру, а по конкретному тесту.
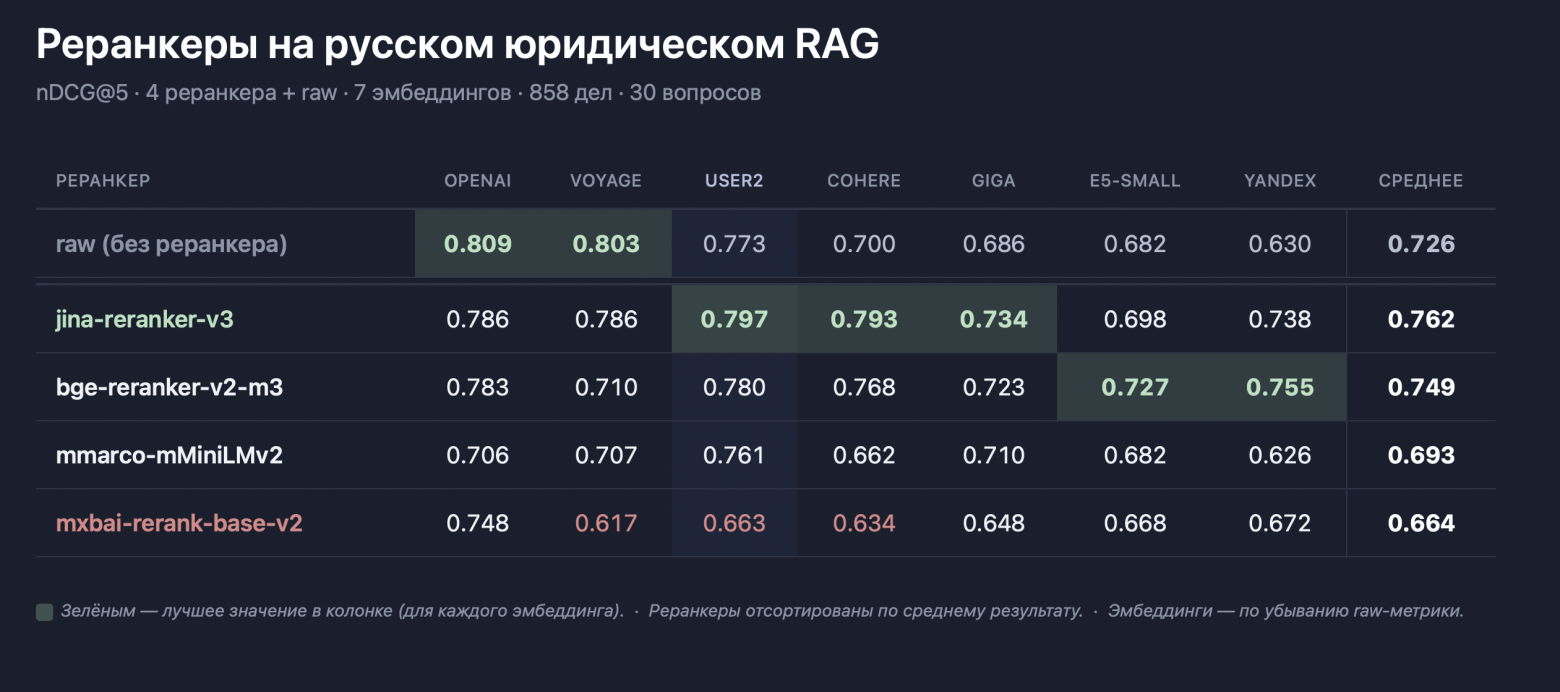
Отдельный нюанс касается реранкера. В тесте рабочими вариантами автор назвал jina-reranker-v3 и bge-reranker-v2-m3. У самой jina-reranker-v3 тоже есть понятный профиль: это многоязычный listwise reranker примерно на 0.6B параметров с контекстом до 131K токенов. Но здесь есть и важная оговорка. Если смотреть на эту связку как на путь в продакшн, надо учитывать не только качество, но и контур использования: модель на Hugging Face опубликована под лицензией CC BY-NC 4.0, а в API Jina после стартовых 10 млн бесплатных токенов начинается обычный платный режим. Иначе говоря, локальная альтернатива OpenAI здесь реальна, но не сводится к лозунгу "вообще без внешних ограничений".
При этом важно не переоценить сам вклад реранкера. В исходном тесте прирост на сильных эмбеддингах был в пределах погрешности, а заметный выигрыш он давал в первую очередь на более слабых моделях.
Где здесь легко ошибиться
Первое искушение — превратить частный benchmark в лозунг "OpenAI проиграла open source". Этого как раз делать нельзя. В тесте один корпус, один юридический домен и всего 30 вопросов. Автор отдельно пишет, что на такой выборке большинство попарных сравнений между моделями статистически трудно различить. Сильный редакционный вывод здесь скромнее и честнее: для узкого русскоязычного legal RAG локальная USER2-base уже выглядит как полноценный кандидат первого эшелона.
Второе искушение — забыть про лексический baseline. В benchmark нет BM25 или Elasticsearch-сравнения, а для узких доменов с повторяющейся терминологией это не формальность. Иногда дешёвая или даже локальная лексическая выдача оказывается сильнее, чем кажется на старте. Поэтому командам не стоит читать этот материал как команду "сразу ставим эмбеддинги и реранкер". Его стоит читать как сигнал, что локальная embedding-модель теперь заслуживает места в нормальном сравнении, а не в декоративном чекбоксе.
Третья ловушка — смешивать оценку экономики из теста с официальным прайсингом вендоров. В статье на Хабре фигурирует оценка индексации корпуса через OpenAI на уровне $2.84. Это полезная ориентирующая цифра для конкретного эксперимента автора, но не универсальный тариф для любого юридического RAG. Правильнее держать рядом оба слоя: бенчмарк показывает стоимость на его данных, а официальная страница OpenAI фиксирует текущую цену самой embedding-модели за 1 млн токенов.
И наконец, не стоит путать локальный стек с бесплатным стеком. Да, USER2-base можно запустить без оплаты внешнего API. Но локальный контур всё равно стоит ресурсов: железо, память, обслуживание, latency-тесты и поддержка пайплайна. Если вы выбираете между открытыми и закрытыми моделями шире, полезно отдельно посмотреть наш материал о том, как выбирать между open-weight моделями и API в 2026 году.
Что делать команде, которая строит legal RAG на русском
Практический вывод из этого benchmark не сводится к одной модели. Он сводится к порядку проверки.
- Сначала соберите свой маленький, но честный набор запросов и ответов. Если у вас нет своих 20-30 запросов и релевантных документов, спор про модели будет чисто теоретическим.
- Потом сравните хотя бы три базовых варианта: локальный lexical search,
USER2-baseи один коммерческий embedding API вродеtext-embedding-3-large. - Реранкер добавляйте после этого, а не до. В исходном benchmark он не сделал магии на сильных эмбеддингах, зато хорошо подтягивал слабые.
- Смотрите не только на качество, но и на эксплуатацию: где крутится индекс, как обновляются документы, кто отвечает за доступность и что будет при росте объёма данных.
Если вам нужен промежуточный мост между общей теорией и этим частным кейсом, пригодится наш материал о том, как встроить ИИ-поиск в приложение с эмбеддингами. Он полезен именно для того места, где новость про бенчмарк превращается в инженерную задачу: как выбирать верхний пул кандидатов, как строить этап поиска и где потом мерить качество, а не впечатления.
Иными словами, USER2-base интересна не потому, что "русская модель наконец победила американскую". Она интересна потому, что у русскоязычных команд появился более сильный локальный baseline для retrieval-задач в узком домене. Это менее громкий заголовок, зато он куда полезнее в продакшне.
Итог
Benchmark на Хабре не закрыл спор про лучшие эмбеддинги для всех случаев. Он сделал более полезную вещь: показал, что в юридическом RAG на русском локальную USER2-base уже можно ставить в один ряд с text-embedding-3-large и сравнивать всерьёз, а не "для галочки". На корпусе из 858 судебных актов и 30 запросов эта модель дошла до уровня, где разница с OpenAI оказалась статистически неочевидной.
Для рынка это не повод объявлять конец коммерческих embedding API. Это повод поднять планку. Если локальная русскоязычная модель уже догоняет OpenAI в узком legal-контуре, следующий разумный шаг для команд — перестать выбирать retrieval-стек по привычке и начать выбирать его по своим тестам, ограничениям и экономике.
Источники и дата проверки
Факты, параметры моделей и ограничения benchmark проверены 2 мая 2026 года. Для материала использованы: статья на Хабре «Бенчмарк 7 эмбеддингов и 4 реранкеров на корпусе судебной практики», модельная страница OpenAI text-embedding-3-large, README модели deepvk/USER2-base на Hugging Face, модельная страница jina-reranker-v3 и официальный FAQ Jina по Reranker API.