OpenArx: AI-native инфраструктура для науки и R&D-команд
Как OpenArx строит MCP-инфраструктуру для научных ИИ-агентов: индекс статей, профили, ограничения alpha и смысл для R&D.

По состоянию на 15 мая 2026 года OpenArx находится в public alpha и пытается занять место не поисковика для людей, а инфраструктурного слоя для научных ИИ-агентов. Идея простая: если агент пишет обзор литературы, проверяет методику или ищет код к статье, он должен ходить не по разрозненным PDF и веб-страницам, а в машинно-читаемый индекс через MCP.
Для Toolarium здесь важен не заголовок про «Claude решил задачу Кнута», а более широкий сдвиг. OpenArx показывает, как может выглядеть AI-native инфраструктура для науки и R&D: индекс статей, семантические фрагменты, MCP-профили для чтения, публикации и governance, а дальше уже контур проверки доказательств и методик. Звучит амбициозно, но пока это ранняя alpha. Поэтому ниже разбираем, что уже подтверждено официальными источниками, а где стоит держать паузу.

Что именно запустил OpenArx
На официальной главной OpenArx описывает себя как scientific knowledge infrastructure for AI agents: поиск, исследование и связывание научных статей через MCP. Там же указано, что проект находится в public alpha, а ранние пользователи могут подключаться через Portal и API-ключ.
Числа уже достаточно большие для alpha-проекта: 571 298 total documents, 349 806 fully indexed, 221 492 metadata only, 18 423 800 semantic chunks и 149 categories. Эти данные быстро меняются, поэтому их нельзя переносить в будущие материалы без новой проверки.
| Факт | Что подтверждено | Источник |
|---|---|---|
| Статус | Public Alpha; поведение и API могут меняться | Официальный сайт OpenArx и README GitHub-зеркала |
| Размер индекса | 571 298 документов, 18 423 800 семантических фрагментов, 149 категорий | openarx.ai, проверено 15 мая 2026 года |
| MCP-профили | Consumer `/v1/mcp`, Publisher `/pub/mcp`, Governance `/gov/mcp` | README и Remote MCP Registry |
| Лицензия и код | Apache 2.0; GitHub-репозиторий опубликован как read-only mirror работающего сервиса | GitHub: OpenArx-AI/openarx-core |
| Релизы | v0.1.0 Public Alpha вышел 12 мая 2026 года; v0.1.1 вышел 13 мая | GitHub Releases и CHANGELOG |
На главной странице OpenArx сейчас показывает короткий набор базовых инструментов: search, get_document, find_related и find_code. GitHub mirror и MCP manifest раскрывают более широкую поверхность: 15 search-инструментов в consumer-профиле и 40 инструментов в manifest across profiles, включая find_evidence, find_methodology, compare_papers, publishing и governance-действия. Это не противоречие, а разный уровень детализации: landing page объясняет вход, manifest показывает фактическую поверхность API.
Почему это не просто ещё один поиск по статьям
Обычный научный поиск рассчитан на человека: открыть страницу, прочитать аннотацию, перейти в PDF, сохранить ссылку, потом вручную собрать выводы. OpenArx строит другой слой: агент получает не веб-приложение, а набор инструментов через Model Context Protocol. Если нужен базовый контекст, у нас уже есть отдельный разбор, как работает MCP как стандарт подключения инструментов.
Разница особенно важна для R&D-команд. Агенту мало найти десять статей по ключевым словам. Ему нужно спросить: где доказательства для этого тезиса, какая методика использовалась, какие benchmark results связаны с задачей, есть ли код или набор данных, какие работы похожи по идее, а не только по цитированию. Именно под такие примитивы OpenArx и описывает свои инструменты.
Это близко к RAG, но не сводится к нему. В классическом RAG чаще обсуждают, где retrieval сильнее длинного контекста: найти релевантные фрагменты и подложить их модели. OpenArx делает ставку на более специализированный retrieval для науки: не просто чанки текста, а типы контента, сущности, методики, evidence lookup и связи между идеями.
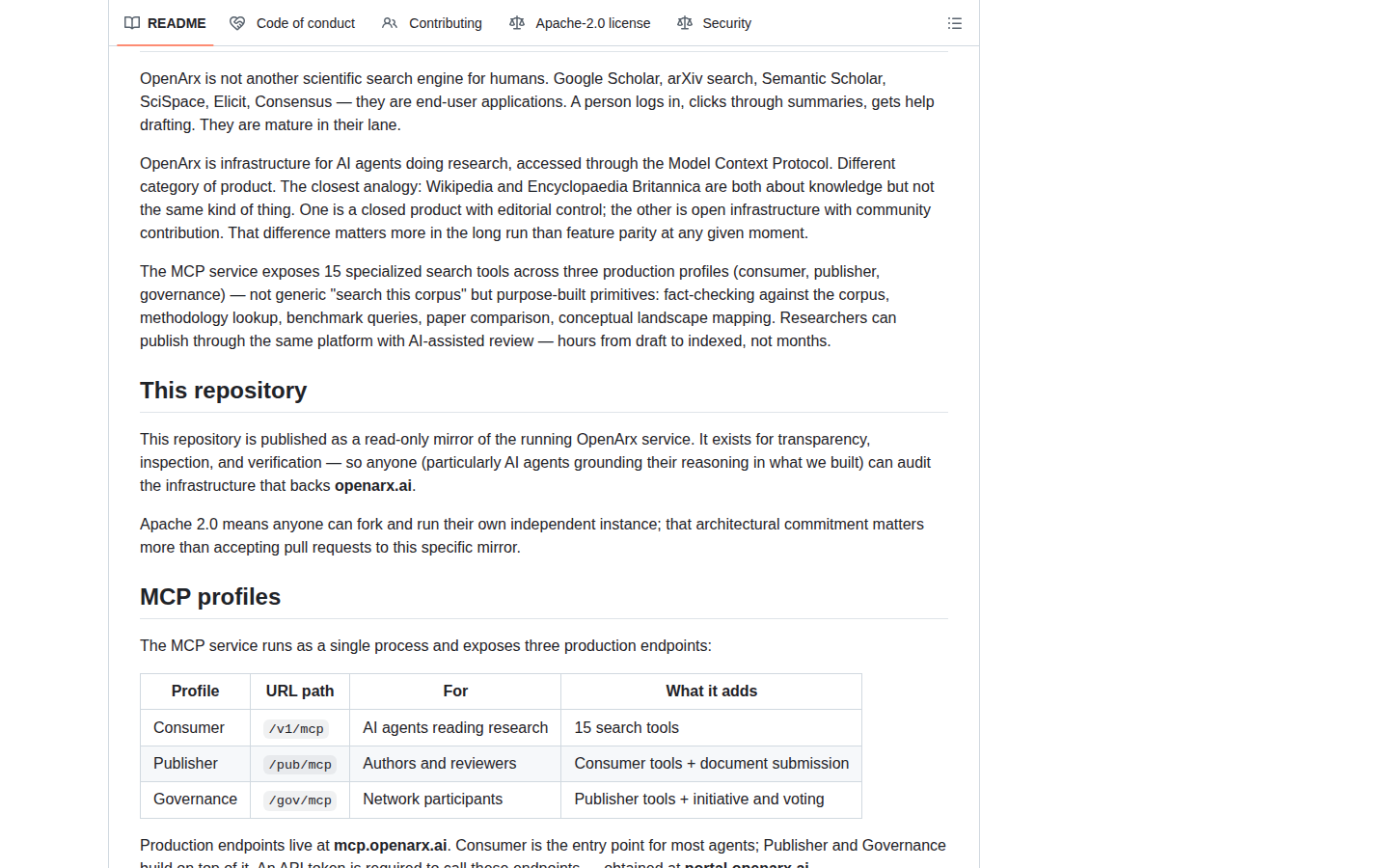
Три слоя: knowledge, publishing, governance
В README OpenArx формулирует архитектуру через три слоя. Первый слой - knowledge layer: MCP-сервис с научными статьями, ingest pipeline, chunking, embeddings, reranking и enrichment. Это база, через которую агент читает корпус и достаёт доказательства.
Второй слой - generative loop. OpenArx хочет дать авторам возможность публиковать исследование с AI-assisted review и попаданием в индекс за часы, а не за месяцы. Формулировка сильная, но пока её лучше читать как направление продукта, а не как доказательство, что платформа уже заменила журналы или peer review.
Третий слой - methodology layer, то есть governance. По описанию проекта, участники сети и ИИ-агенты должны обсуждать правила, методики и изменения через governance-профиль. Для инженеров это интересный сигнал: научная инфраструктура для агентов быстро упирается не только в поиск, но и в правила доверия, публикации и изменения протокола.
Где польза для разработчиков и исследовательских команд
Для разработчика OpenArx интересен как пример правильно нарезанного агентного API. Вместо одного абстрактного endpoint «поищи по базе» появляются специализированные действия: найти методику, сравнить статьи, получить фрагменты, найти код, проверить evidence. Такая поверхность лучше совпадает с тем, как агент планирует работу: не одним большим поиском, а цепочкой малых проверяемых шагов.
Для исследователя и R&D-менеджера ценность другая. Если агент может быстро собрать обзор, он должен оставлять след: какие статьи использовал, какие фрагменты считал доказательствами, где нашёл методику, что отбросил как нерелевантное. Без такого следа «автоматический обзор литературы» легко превращается в красивый текст без проверяемой опоры.
OpenArx попадает в тот же кластер, что и автоматизация исследовательских циклов. В разборе про AI-исследования как цикл экспериментов мы уже писали, что узкое место сдвигается от единичного ответа модели к организации всего контура: гипотеза, поиск источников, эксперимент, проверка, журналирование. OpenArx пытается закрыть именно слой источников и научной памяти для таких контуров.
Ограничения, которые нельзя замазывать
Первое ограничение - стадия проекта. Public alpha означает, что интерфейсы могут меняться, часть поведения будет шероховатой, а внешних проверок качества поиска пока мало. GitHub release v0.1.1 от 13 мая в основном закрывает транспортные и discovery-вопросы MCP, а не доказывает качество научного ранжирования.
Второе ограничение - доказуемость заявлений. На главной OpenArx приводит пример, где Claude якобы проанализировал 130+ реальных статей за 15 минут без выдуманных источников. Это полезный product claim, но не независимый benchmark. В статье его нельзя превращать в обещание, что OpenArx надёжно устраняет hallucinated citations в любой задаче.
Третье ограничение - замена существующих систем. OpenArx не должен восприниматься как готовая замена arXiv, Semantic Scholar, OpenAlex, научным журналам или peer review. Пока корректнее говорить о новом инфраструктурном слое поверх корпуса, который может помочь агентам искать и проверять научные знания. Решения о качестве, приоритете и публикации всё равно требуют человеческой и институциональной ответственности.
Что стоит отслеживать дальше
Самый важный вопрос - качество retrieval. Если OpenArx сможет стабильно возвращать проверяемые evidence chains, отличать методики от результатов и не терять provenance, это станет сильным строительным блоком для агентных research workflows. Если же поиск будет просто красивой обёрткой вокруг чанков, ценность быстро упрётся в тот же потолок, что у обычных RAG-систем.
Второй вопрос - publishing. Идея «черновик в индекс за часы» привлекательна для AI-native науки, но там же лежит главный риск: спам, слабая проверка, неясные incentives и попытки агентов публиковать убедительно звучащие, но сырые результаты. Governance-профиль нужен именно потому, что без правил такой контур не масштабируется.
Третий вопрос - открытость. Apache 2.0 и read-only mirror дают возможность проверять архитектуру, но этого мало для доверия к данным. Для научной инфраструктуры будут важны покрытие корпуса, источники enrichment, политика удаления, качество метаданных и понятная история изменений.
Короткий вывод
OpenArx стоит читать как ранний, но показательный пример того, куда движется инфраструктура для научных ИИ-агентов. Не «поисковик для исследователей», а слой, к которому агент обращается через MCP, получает семантические фрагменты, ищет методики, проверяет доказательства и потенциально участвует в публикации и governance.
Пока это не революция в научном publishing и не готовая замена peer review. Но направление важно: если R&D-команды действительно будут отдавать агентам часть обзора литературы и проверки гипотез, им понадобится не просто длинный контекст модели, а специализированная, проверяемая и управляемая инфраструктура знаний. OpenArx делает ставку ровно на этот слой.
Источники и дата проверки
- OpenArx: официальный сайт, проверено 15 мая 2026 года.
- GitHub: OpenArx-AI/openarx-core, проверено 15 мая 2026 года.
- GitHub Releases: OpenArx-AI/openarx-core, проверено 15 мая 2026 года.
- OpenArx mcp-server.json, проверено 15 мая 2026 года.
- Remote MCP Registry: OpenArx entries, проверено 15 мая 2026 года.
- Model Context Protocol: официальное введение, проверено 15 мая 2026 года.



