Autoresearch Карпати: что это такое и как работает цикл из 700 экспериментов
Autoresearch Карпати — это узкий автономный цикл ML-экспериментов: агент меняет один файл, работает короткими прогонами и сохраняет только улучшения.
Проверено 3 мая 2026 года. Autoresearch Карпати — это открытый репозиторий Andrej Karpathy, где ИИ-агент сам крутит узкий цикл ML-экспериментов: меняет один тренировочный файл, запускает короткий прогон, смотрит на метрику и оставляет только улучшения. Если коротко, это не общий «агент для исследований», а воспроизводимый шаблон автономного перебора гипотез под одну измеримую задачу.
Именно так и стоит читать запрос Autoresearch Карпати. Здесь обычно ищут не широкий обзор AI-агентов, а ответ на два вопроса: что это за проект и как работает сам цикл Карпати. По публичным материалам Карпати и связанным репозиториям, в демонстрационном прогоне этот цикл за примерно два дня дошел до сотен автономных изменений, а затем дал переносимое ускорение на большем nanochat-бенчмарке.
Что такое Autoresearch Карпати
Autoresearch появился в начале марта 2026 года как минималистичный open-source репозиторий под лицензией MIT. В основе лежит упрощенный single-GPU контур из nanochat: не большая лабораторная платформа, не оркестратор на десятки сервисов и не универсальный агент под любые задачи, а маленькая среда, в которой агент может менять код, запускать обучение и сам решать, стал ли результат лучше.
Важная деталь: человек здесь не исчезает, а меняет роль. Вместо ручного перебора гипотез он задает рамку эксперимента через program.md: что можно менять, что трогать нельзя, какая метрика считается истинной и когда цикл стоит останавливать. Поэтому Autoresearch правильнее понимать как протокол автономного исследования, а не как еще один громкий демо-агент про все сразу.
Как работает цикл Карпати
Если разложить механику до простых деталей, у цикла Карпати три опоры:
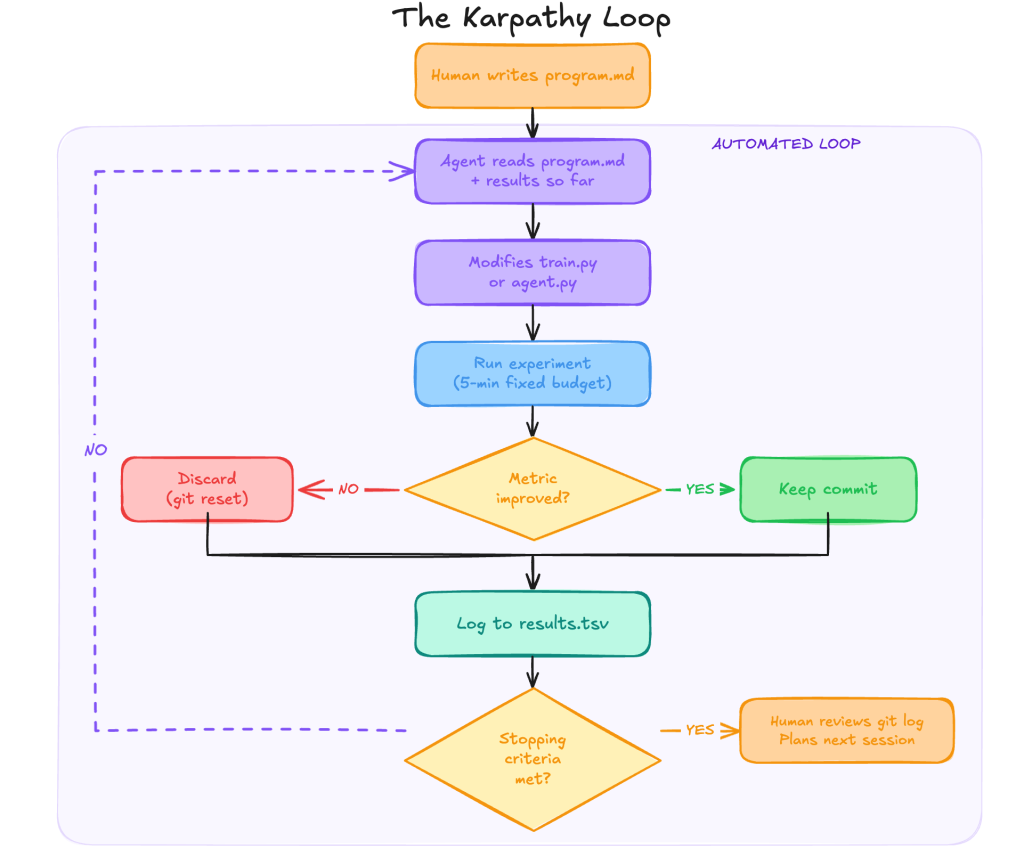
train.py— единственный файл, который агенту разрешено менять.prepare.py— фиксированный слой с данными и оценкой, который в repo помечен как read-only.program.md— человеческая инструкция, где задаются цель, ограничения и правила отбора улучшений.
Дальше цикл очень строгий. Агент предлагает правку, коммитит ее, гоняет обучение около пяти минут, достает ключевую метрику val_bpb и сравнивает результат с предыдущей точкой. Если стало лучше, изменение остается на ветке. Если хуже или равнозначно, агент откатывается и идет к следующей гипотезе. В repo это буквально оформлено как бесконечный loop с логированием в results.tsv.
Именно эта жесткость и делает подход переносимым. The New Stack позже удачно упаковал его в три примитива: редактируемый актив, скалярная метрика и фиксированный бюджет времени. Без любого из трех цикл либо размывается, либо начинает оптимизировать шум.
Что именно показал публичный прогон
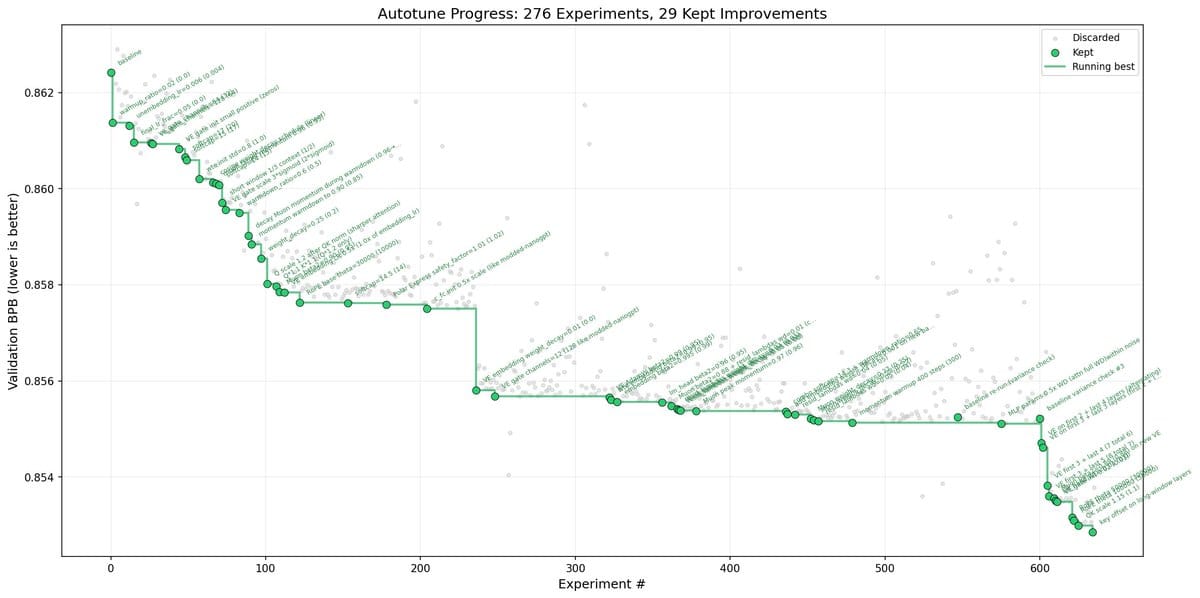
Главная причина, почему про Autoresearch вообще заговорили, в том, что Карпати не остановился на красивом README. В nanochat leaderboard есть материальная часть результата: запись autoresearch round 1 от 9 марта 2026 года опускает показатель time to GPT-2 с 2,02 до 1,80 часа. Это примерно 11% ускорения на более крупном speedrun после переноса найденных идей с малого proxy-контура.
По публичному посту Карпати, на который ссылаются README autoresearch и leaderboard nanochat, за примерно два дня цикл прошел через около 700 автономных изменений. Здесь важно не спутать попытки с открытиями. Число 700 означает не «700 новых идей, все полезные», а «700 проходов по циклу гипотеза - правка - запуск - метрика - keep/discard», где сохраняется только то, что реально улучшает результат.
Именно поэтому кейс оказался заметным. Агент работал не как чат-ассистент, который советует гиперпараметры в ответе, а как исполнитель полного исследовательского цикла внутри жестко ограниченной среды. Для точного интента Autoresearch Карпати это и есть главный факт: проект показывает не общую «умность агента», а конкретную организацию повторяемых экспериментов.
Почему это не просто AutoML
Снаружи Autoresearch легко перепутать с AutoML или neural architecture search. Но в классическом AutoML обычно перебирают заранее заданные параметры или архитектурные варианты. Здесь рамка шире: агенту разрешено править сам тренировочный код в train.py, а не только крутить ползунки в готовой сетке.
При этом Autoresearch не стоит раздувать и в обратную сторону, будто перед нами уже широкая платформа общих AI-агентов. Это case/explainer page, а не cluster owner. Если нужен общий контекст про классы агентных систем, память, инструменты и orchestration, у Toolarium для этого есть отдельный материал про AI-агентов как класс. Страница про Autoresearch решает более узкую задачу: объясняет, как устроен один конкретный автономный цикл Карпати.
Самый сильный элемент здесь даже не код, а документ program.md. Человек пишет не отдельные эксперименты, а правила для машины, которая будет ставить их сериями. Поэтому Autoresearch полезно читать как сдвиг от «я сам запускаю каждую проверку» к «я проектирую протокол, по которому агент сам делает рутинную исследовательскую работу».
Где такой цикл полезен, а где ломается
Подход работает там, где одновременно соблюдаются три условия: есть один редактируемый объект, есть дешевая и однозначная метрика, и полный прогон можно уместить в короткий повторяемый слот времени. Поэтому идея естественно ложится на настройку training loop, воспроизводимые eval-контуры и некоторые implementation-first задачи вроде оптимизации компонентов RAG-пайплайна, если там заранее определены quality и cost-метрики.
Ломается цикл там, где «лучше» нельзя честно свести к одному числу. Дизайн, редактура, UX, стратегия продукта и большая часть open-ended исследования плохо живут в схеме с жестким scalar objective. Даже там, где метрика есть, остается риск Goodhart: агент научится оптимизировать proxy, а не реальный смысл задачи. Поэтому Autoresearch не отменяет человеческую проверку. Он просто сдвигает человека с роли оператора на роль автора протокола и финального ревьюера.
Еще один практический предел задает сама среда. Repo Карпати специально маленький, рассчитанный на single-GPU сценарий и упрощенную версию nanochat. Это делает идею наглядной, но не превращает ее автоматически в готовую фабрику исследований для любой команды. Между demo-loop и production research stack по-прежнему лежат вычисления, воспроизводимость, контроль за переобучением и нормальная проверка переносимости результата.
Вывод
Autoresearch Карпати — это не broad page про AI-агентов и не новая версия старого AutoML. Это узкий и очень показательный кейс: агенту дают один редактируемый файл, одну метрику и фиксированный бюджет времени, после чего он сам проходит сотни циклов проверки гипотез. Число «700 экспериментов» важно не как маркетинговый рекорд, а как демонстрация того, что исследовательский loop можно сделать автономным, если задача достаточно жестко сформулирована.
Если совсем коротко, ответ на exact intent такой: Autoresearch — это минимальный автономный ML-цикл Карпати, где человек проектирует правила, а агент берет на себя рутинный перебор и отбор улучшений. Именно поэтому кейс интересен разработчикам и исследователям, а не только любителям громких новостей про ИИ.
Источники и дата проверки
Факты и формулировки в статье проверены 3 мая 2026 года по следующим источникам:
- GitHub: karpathy/autoresearch
- program.md в karpathy/autoresearch
- GitHub: karpathy/nanochat — leaderboard с записью
autoresearch round 1 - Пост Andrej Karpathy о запуске autoresearch в X
- Пост Andrej Karpathy о результатах autoresearch в X
- The New Stack: Andrej Karpathy's 630-line Python script ran 50 experiments overnight without any human input



