Открытые модели ИИ в кибербезопасности: урок Mythos
Aisle показала, что малые open-weight модели воспроизводят часть анализа Mythos на изолированном коде. Разбираем, где теперь moat в AI-cybersecurity.

Открытые модели ИИ в кибербезопасности больше нельзя считать «младшей лигой», которая только повторяет демо больших закрытых систем. 7 апреля 2026 года Anthropic запустила Project Glasswing и показала Claude Mythos Preview как модель для поиска и проверки уязвимостей. В тот же день Aisle опубликовала разбор с неудобным для рынка выводом: часть анализа, которым Anthropic объясняла силу Mythos, воспроизводится малыми open-weight моделями на изолированном коде.
По состоянию на 12 апреля 2026 года это не доказательство, что дешёвая модель сама найдёт zero-day в огромном репозитории и соберёт рабочий эксплойт. Но это сильный сигнал для защитников: конкурентное преимущество в AI-cybersecurity всё меньше похоже на гонку «у кого модель больше». Всё чаще оно лежит в пайплайне: как найти нужный участок кода, проверить находку, отсечь ложные срабатывания, подготовить патч и пройти ответственное раскрытие.
Это продолжение истории, которую мы уже разбирали в материале про Claude Mythos и реальный риск для кибербезопасности. Там главный вопрос был в том, насколько опасны закрытые модели для эксплуатации уязвимостей. Здесь вопрос другой: что меняется, если часть defensive analysis уже доступна открытым и недорогим моделям.
Что проверяла Aisle
Разбор Aisle написал Stanislav Fort, основатель и главный научный сотрудник компании. Текст не спорит с тем, что Mythos сильная модель. Он спорит с более узкой идеей: будто полезная кибербезопасностная способность обязательно требует закрытой frontier-модели.
Aisle взяла уязвимости, которые Anthropic использовала в публичном рассказе о Mythos, изолировала релевантный код и прогнала его через набор небольших и дешёвых моделей, включая open-weight варианты. В одном из тестов, FreeBSD NFS detection, все восемь моделей нашли проблему в изолированной функции. Отдельно Aisle подчёркивает ограничение: модели проверяли уже выбранный участок кода, а не искали баг автономно по всему репозиторию.

Важная деталь в этой работе не только «малые модели тоже видят баг». Aisle показывает рваную картину качества. Одна модель лучше справляется с прямым поиском переполнения, другая с математической цепочкой OpenBSD SACK, третья проваливает проверку исправленного кода и начинает видеть уязвимость там, где её уже нет. Для реального процесса безопасности это критично: модель, которая ловит всё подряд, но плохо отличает исправленный код от уязвимого, завалит сопровождающих шумом.
Почему Mythos всё ещё важен
Anthropic в техническом разборе Mythos описывает другой уровень задачи. Компания пишет, что модель не только находила уязвимости, но и строила рабочие эксплойты. Самая цитируемая цифра: в тесте Firefox 147 JavaScript shell Mythos Preview получил рабочий эксплойт 181 раз из 250 попыток, а ещё в 29 попытках добился контроля регистра. Для сравнения, Opus 4.6 в прежнем тесте справлялся только в единичных случаях.
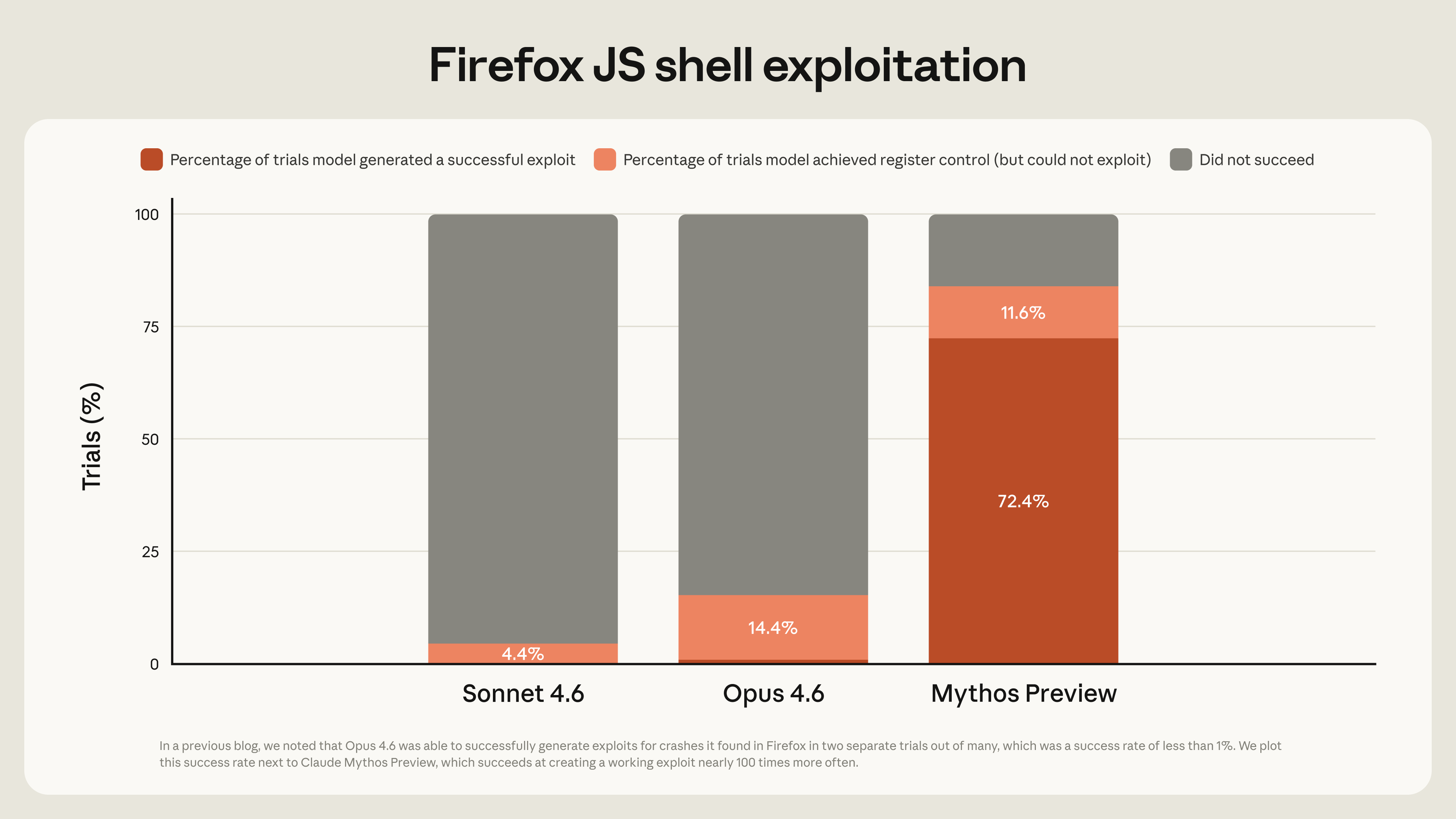
Эта оговорка важна. Firefox JS shell не равен полному взлому браузера с обходом всех песочниц операционной системы. Но задача всё равно сложнее, чем «найди подозрительную строку в готовом фрагменте». Exploit construction требует собрать цепочку действий, проверить гипотезы и довести находку до воспроизводимого результата.
Грубый вывод «open-weight модели уже закрывают весь Mythos» был бы неверным. Часть discovery и analysis выглядит доступной шире, чем ожидалось, а самая дорогая и опасная часть — автономная эксплуатация, цепочки эксплойтов, приоритизация и проверка — остаётся системной задачей. Anthropic поэтому не выводит Mythos в общий доступ и запускает Project Glasswing как закрытую партнёрскую программу для защитников критического ПО.
Где теперь преимущество
Aisle предлагает полезно разложить AI-cybersecurity на отдельные стадии. Сканирование большого репозитория, выбор подозрительных файлов, анализ конкретной функции, проверка exploitability, генерация патча и ответственное раскрытие уязвимости — это разные задачи. Они по-разному зависят от размера модели, стоимости токенов, скорости инференса, качества контекста и опыта людей, которые строят обвязку.
| Сигнал | Что он показывает | Ограничение |
|---|---|---|
| Aisle: 8 из 8 моделей нашли FreeBSD NFS bug | Detection на подготовленном участке кода уже не выглядит эксклюзивом frontier-модели. | Модели работали с изолированной функцией, полный репозиторий без подсказок им не давали. |
| Anthropic: 181/250 успешных Firefox JS shell эксплойтов у Mythos | Exploit construction всё ещё может быть зоной, где сильная закрытая модель резко впереди. | Тест проходил в harness без полной браузерной и системной песочницы. |
| Aisle: patched FreeBSD дал много false positive | Triage и specificity не менее важны, чем чувствительность модели. | Повторный тест был маленьким: по три запуска на unpatched и patched код. |
Отсюда меняется само понимание moat. Устойчивое преимущество получает не тот, кто просто купил доступ к самой сильной модели. Его получает команда, которая умеет превращать модельный ответ в проверенный результат: запускать код в песочнице, использовать AddressSanitizer и фаззинг как оракулы, хранить полные логи, отсеивать повторы, оценивать серьёзность и говорить с мейнтейнерами так, чтобы патч реально приняли.
Что это меняет для открытых моделей
В обычном сравнении открытых и проприетарных моделей open-weight подход часто защищают приватностью, ценой и возможностью локального запуска. В кибербезопасности появляется ещё один аргумент: покрытие. Если недорогая модель достаточно хорошо проверяет конкретный класс ошибок, её можно запускать шире и чаще, а дорогую модель оставлять для сложных случаев.
Но «шире и чаще» работает только при дисциплине. Массовый запуск слабее контролируемых моделей без triage быстро превращается в поток ложных отчётов. Aisle прямо пишет об этом на примере patched FreeBSD: несколько моделей уверенно находили проблему даже после добавленного bounds check. Для open-source проектов с дефицитом мейнтейнеров такой шум опасен сам по себе. Он отнимает время у людей, которые должны чинить настоящие баги.
Поэтому открытые модели ИИ в кибербезопасности лучше воспринимать как дешёвый сенсор внутри нормального процесса. Сенсор может подсветить подозрительный участок, предложить гипотезу, собрать первичный отчёт. Дальше нужны проверка, воспроизведение, severity scoring и человеческая ответственность за disclosure.
Что делать командам безопасности
Первое действие — разделить pipeline на стадии и измерять каждую отдельно. Не надо спрашивать одну модель: «найди все уязвимости в проекте». Полезнее отдельно проверить, как она выбирает файлы для аудита, как анализирует короткий фрагмент, сколько даёт ложных срабатываний на исправленном коде, умеет ли воспроизвести crash и насколько аккуратно предлагает патч.
Второе действие — запускать модели в контролируемой среде. Для анализа C/C++ нужны контейнеры, санитайзеры, ограниченная сеть, воспроизводимые сборки и журнал команд. Для агентных сценариев это уже не желательная «гигиена», а базовое условие. Если модель может читать секреты, ходить в интернет и запускать команды без аудита, проблема появляется раньше любого Mythos.
Третье действие — заранее договориться о маршруте находки. Кто подтверждает баг, кто пишет патч, кто общается с мейнтейнером, как отслеживается срок раскрытия, что попадает в публичный отчёт. Anthropic в своём разборе отдельно подчёркивает coordinated vulnerability disclosure и пишет, что более 99% найденных уязвимостей на момент публикации ещё нельзя раскрывать. В кибербезопасности ценность красивого демо быстро заканчивается; засчитывается исправленный баг.
Итог
История Mythos после разбора Aisle стала менее драматичной, но более полезной. Закрытая frontier-модель действительно показывает новый уровень exploit construction. Одновременно малые open-weight модели уже воспроизводят часть анализа на подготовленном коде. Эти две вещи не противоречат друг другу.
Вывод для защитников простой: начинать можно сейчас, но начинать надо с системы. Открытые модели дадут охват и экономику, сильные закрытые модели помогут на сложных участках, а результат всё равно решат контекст, песочницы, triage, патчи и доверие мейнтейнеров. В кибербезопасности выигрывает процесс, который умеет превращать вывод модели в исправленный код.


