ИИ-агенты в продакшене: tokenmaxxing и tool-overuse
Tokenmaxxing, tool-overuse и SkillGraph показывают, почему зрелые ИИ-агенты в продакшене требуют лимитов, трасс и осознанного порядка действий.

По состоянию на 23 апреля 2026 года разговор про ИИ-агентов в продакшене сместился от «дайте модели больше токенов» к более скучной, но полезной теме: как ограничивать лишние действия. В свежей сводке Latent Space/AINews это назвали tasteful tokenmaxxing: не запускать десятки параллельных попыток ради случайного успеха, а давать агенту больше глубины там, где это действительно улучшает результат.
Почти одновременно вышли два препринта на arXiv, которые хорошо объясняют инженерную сторону проблемы. The Tool-Overuse Illusion показывает, что LLM-агенты часто вызывают инструменты даже тогда, когда справились бы внутренним знанием. SkillGraph разбирает соседнюю боль: мало выбрать правильные API, их ещё нужно поставить в правильный порядок. Для продакшена это не академическая тонкость, а деньги, задержка и управляемость.
Почему tokenmaxxing стал спорным словом
В пересказе Latent Space/AINews tokenmaxxing звучит как реакция на растущий соблазн решать задачи грубой силой: больше контекста, больше проходов, больше параллельных запусков. Такой подход иногда помогает, особенно в исследовательских задачах и сложном коде. Но в рабочем контуре он быстро превращается в непрозрачную лотерею: агент тратит токены, плодит трассы и создаёт результаты, которые потом всё равно должен разбирать человек.
Здравый вариант выглядит иначе. Вместо сотен независимых попыток агенту дают несколько последовательных шагов: найти данные, проверить гипотезу, сверить результат, исправить ошибку. Это медленнее на бумаге, но лучше контролируется. У команды появляется трасса: почему агент выбрал инструмент, какие данные получил, где ошибся и что изменил после проверки.
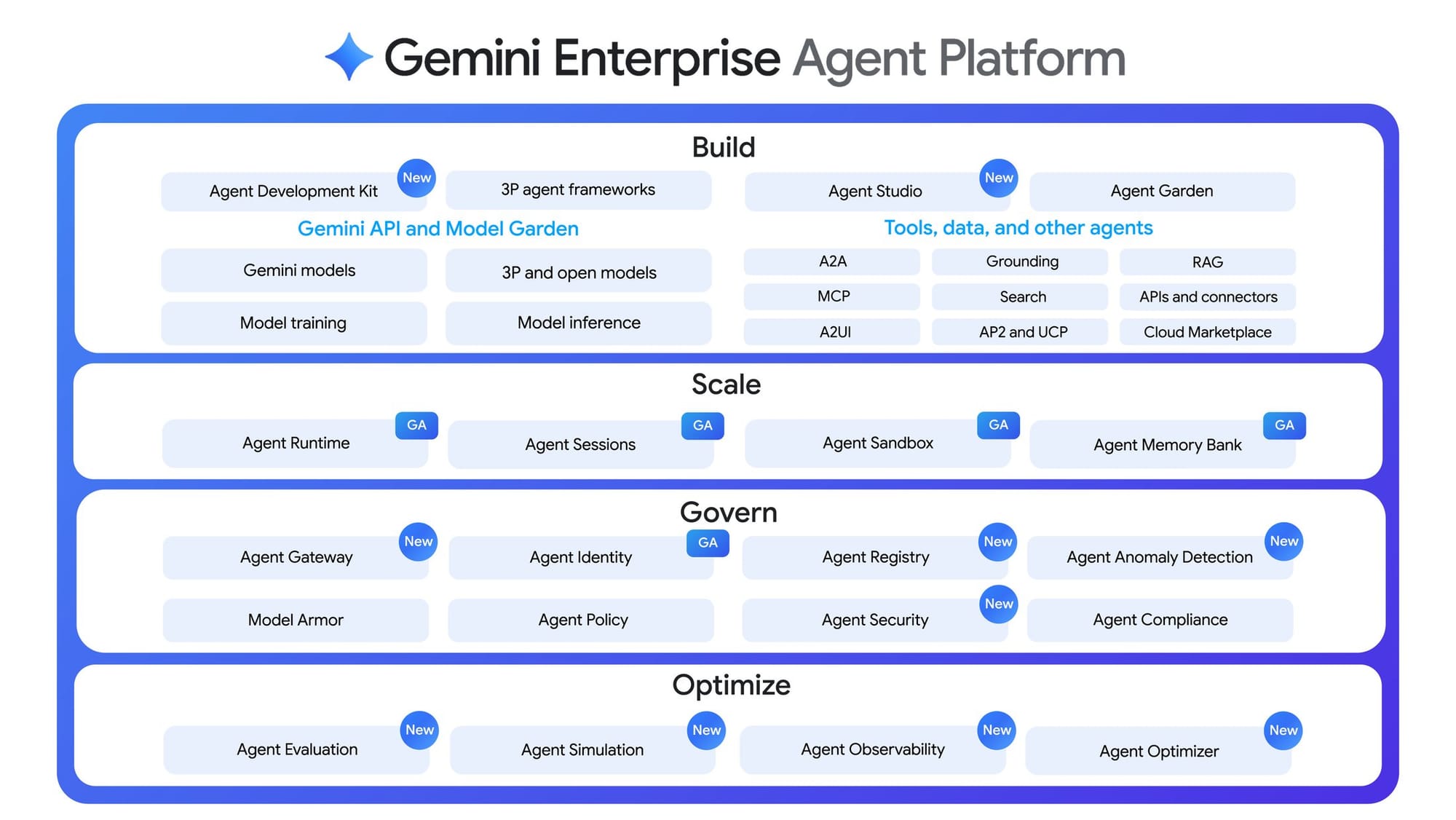
Google Cloud 22 апреля 2026 года объявила Gemini Enterprise Agent Platform как эволюцию Vertex AI. В официальном описании платформа закрывает четыре задачи: build, scale, govern и optimize. Внутри есть Agent Runtime для долгих задач с состоянием, Agent Identity, Agent Registry, Agent Gateway, Agent Evaluation, Agent Simulation и Agent Observability. Сам факт такой упаковки важнее маркетинговых формулировок: поставщики уже продают не «чат с моделью», а контур управления агентами.
| Сигнал | Проверенный факт | Почему это важно |
|---|---|---|
| Tokenmaxxing | Latent Space/AINews 23 апреля описала спор о глубине против массовых параллельных запусков | Больше токенов полезны только там, где есть проверяемая стратегия |
| Tool-overuse | arXiv 2604.19749 показывает лишние вызовы инструментов у LLM-агентов | Каждый лишний вызов добавляет стоимость, задержку и поверхность ошибки |
| SkillGraph | arXiv 2604.19793 построен на 49 831 успешной траектории агентов | Порядок инструментов можно учить по трассам, а не угадывать по описаниям API |
| Корпоративные платформы | Google Cloud вывела Gemini Enterprise Agent Platform как новый путь развития Vertex AI | Продакшену нужны identity, registry, gateway, evals и observability, а не только модель |
Tool-overuse: агент зовёт инструмент без причины
Препринт The Tool-Overuse Illusion submitted on 3 Mar 2026 описывает два типа лишних действий. Redundant tool use возникает, когда задача решается без внешнего инструмента, но агент всё равно вызывает калькулятор, поиск, код или API. Irrelevant tool use хуже: инструмент не связан с задачей и может привести к ошибке.
Авторы связывают проблему с двумя механизмами. Первый — неверная оценка границы собственного знания: модель не понимает, где она действительно знает ответ, а где нужен внешний источник. Второй — reward-дизайн. Если обучение награждает только правильный финальный ответ, модель может научиться вызывать инструменты «на всякий случай», потому что цена действия не попадает в награду.
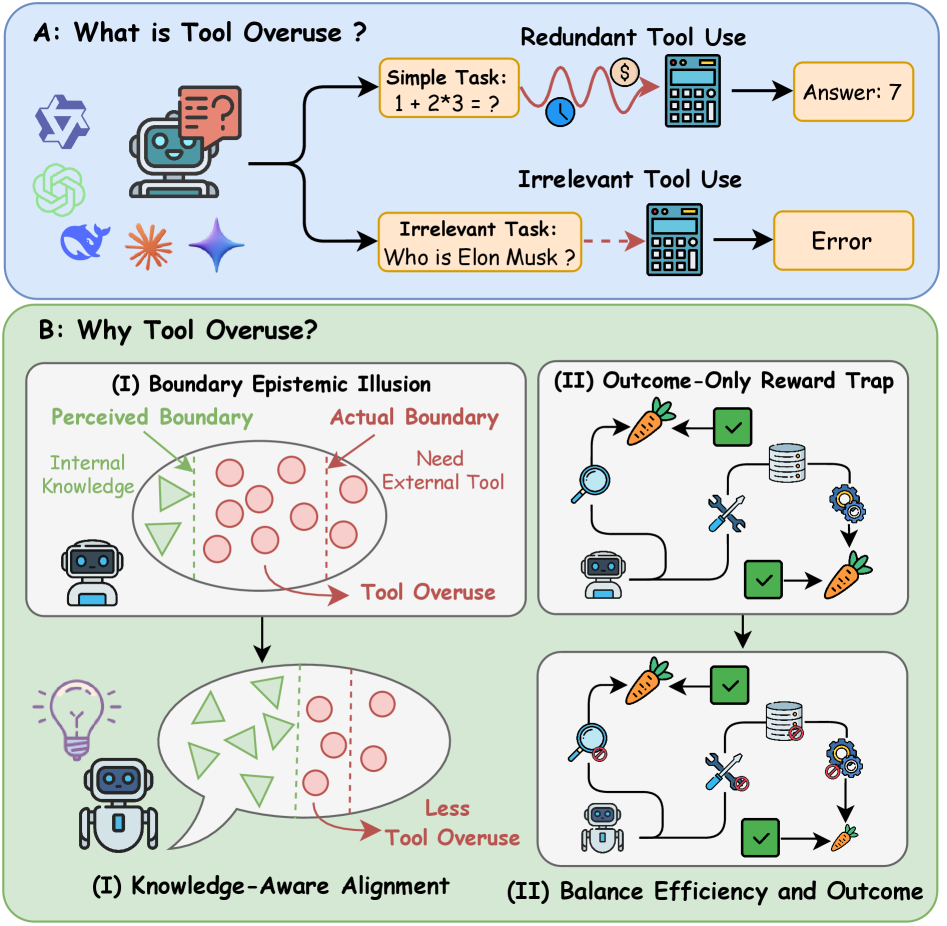
Цифры в статье показательные. Knowledge-aware boundary alignment на базе DPO сократил использование инструментов на 82,8% и при этом улучшил accuracy. Балансировка награды вместо outcome-only reward снизила ненужные вызовы на 66,7% для 7B-модели и на 60,7% для 32B-модели без потери accuracy. Один DPO-рецепт не станет универсальной страховкой. Но вывод полезен: стоимость действия должна быть частью цели, иначе агент оптимизирует красивый финал и игнорирует путь.
Для продуктовой команды это почти бухгалтерская мысль. Вызов инструмента нужно считать событием с ценой: токены, время, права доступа, риск утечки, вероятность устаревшего результата. Если агент не умеет выбрать вариант «не вызывать инструмент», он не готов к автономному контуру.
SkillGraph: правильный API ещё нужно вызвать вовремя
Второй препринт, SkillGraph: Graph Foundation Priors for LLM Agent Tool Sequence Recommendation, submitted on 7 Apr 2026, смотрит на другую часть пайплайна. Авторы пишут, что семантическая близость плохо решает порядок инструментов: описание API может быть похоже на задачу, но зависимость данных между вызовами не видна из текста.
SkillGraph строит направленный взвешенный граф переходов по 49 831 успешной траектории LLM-агентов. Дальше система разделяет два шага: сначала подбирает кандидатов через GS-Hybrid retrieval, затем переупорядочивает их learned pairwise reranker. На ToolBench авторы указывают 9 965 тестовых задач и около 16 000 инструментов; результат — Set-F1 0,271 и Kendall tau 0,096. На API-Bank Kendall tau вырос с -0,433 до +0,613.
Практический смысл простой. Агентный workflow похож на сборку данных: сначала получить id, потом запросить детали, потом проверить ограничение, потом выполнить действие. Если поменять два шага местами, модель может выбрать «правильные» инструменты и всё равно провалить задачу. Поэтому в продакшене нужны не только tool descriptions, но и память о рабочих последовательностях.
Что это меняет в продакшене
Зрелые ИИ-агенты в продакшене должны измеряться не количеством токенов и не числом tool calls. Полезнее смотреть на трассу целиком: сколько стоила задача, какие инструменты вызваны, сколько раз агент повторил один и тот же шаг, где сработали проверки, какой процент действий дошёл до полезного результата.
Это хорошо стыкуется с тем, что мы уже разбирали в материале про боевой контур для AI-агентов. Агенту мало иметь доступ к браузеру, терминалу или базе. Нужны изоляция, журнал действий, права, rollback и понятное место для человеческого подтверждения. Без этого tokenmaxxing превращается в дорогой шум.
- Вводите бюджет задачи: лимит токенов, лимит вызовов инструментов, лимит времени и понятный fallback.
- Делайте no-tool валидным выбором. Агент должен объяснять, почему внешний источник не нужен.
- Считайте стоимость трассы, а не только финальную accuracy.
- Учите маршрутизацию на успешных последовательностях, если у вас уже есть логи production-агентов.
- Разделяйте безопасные read-only инструменты и инструменты с побочными эффектами: платежи, деплой, письма, изменения в CRM.
- Добавляйте evals на избыточность: сколько вызовов можно убрать без падения качества.
В статье про стоимость и лимиты ИИ-агентов для разработки мы уже видели, что цена быстро становится продуктовым ограничением. Tool-overuse добавляет к этому техническую причину: агент может быть дорогим не из-за сложной задачи, а из-за плохой политики выбора инструментов.
Как не перепутать рост с шумом
Есть неприятная ловушка: рост числа вызовов выглядит как «агент стал активнее». В логах больше событий, в демо больше движения, в отчёте больше графиков. Но активность не равна прогрессу. Если агент делает три поиска вместо одного, переписывает код без нужды или вызывает API без входных данных, команда получает видимость работы, а не результат.
Поэтому бенчмарки агентных систем тоже нужно читать осторожно. Мы писали, почему метрики агентных систем легко вводят в заблуждение: высокий результат на одном контуре не доказывает устойчивость в другом. SkillGraph усиливает этот тезис. Модель, инструментальная обвязка, набор API и порядок вызовов вместе образуют систему; оценивать только модель уже недостаточно.
Для русскоязычных команд главный вывод прагматичный. Если вы внедряете агента в разработку, поддержку, аналитику или внутренние операции, начните не с максимального контекста, а с протокола контроля. Какие действия агент может делать сам? Где нужна проверка? Сколько стоит одна задача? Какие tool calls считаются подозрительными? Какая трасса признаётся хорошей?
Вывод
Tokenmaxxing полезен как повод для разговора, но плох как стратегия сам по себе. ИИ-агенты в продакшене взрослеют тогда, когда команда управляет глубиной рассуждения, стоимостью действий и порядком инструментов. Свежие исследования показывают, что лишние tool calls можно заметно сократить без потери качества, а успешные траектории можно использовать как основу для маршрутизации.
Следующий этап агентных систем будет меньше похож на чат и больше на инженерный контур: трассы, бюджеты, права, evals, симуляции и observability. Это менее зрелищно, чем запуск сотни параллельных агентов, зато ближе к тому, что можно доверить реальной работе.
Читайте также
- Cloudflare Agent Cloud OpenAI: зачем агентам боевой контур
- Цены на ИИ-агенты для программирования: лимиты 2026
- Бенчмарки ИИ-агентов ломаются: почему 100% не значит способность
Источники и проверка фактов
- Latent Space/AINews: Tasteful Tokenmaxxing, опубликовано 23 апреля 2026 года, проверено 23 апреля 2026 года.
- arXiv: The Tool-Overuse Illusion, submitted on 3 Mar 2026, проверено 23 апреля 2026 года.
- arXiv: SkillGraph, submitted on 7 Apr 2026, проверено 23 апреля 2026 года.
- Google Cloud: Introducing Gemini Enterprise Agent Platform, опубликовано 22 апреля 2026 года, проверено 23 апреля 2026 года.



