GTA-2 benchmark AI-агентов: где у агентов ломается работа
GTA-2 показывает неприятный разрыв: AI-агенты выбирают инструменты лучше, чем доводят рабочий сценарий до финального результата.
По состоянию на 21 апреля 2026 года разговор про AI-агентов всё чаще звучит так, будто осталось только выбрать модель, дать ей терминал, браузер и пару API. GTA-2, новый бенчмарк для general tool agents, предлагает неприятную проверку реальностью. В режиме GTA-Workflow лучший результат на официальном leaderboard - 14,39% Root SR. То есть даже лидер доводит до конца примерно одну из семи задач.
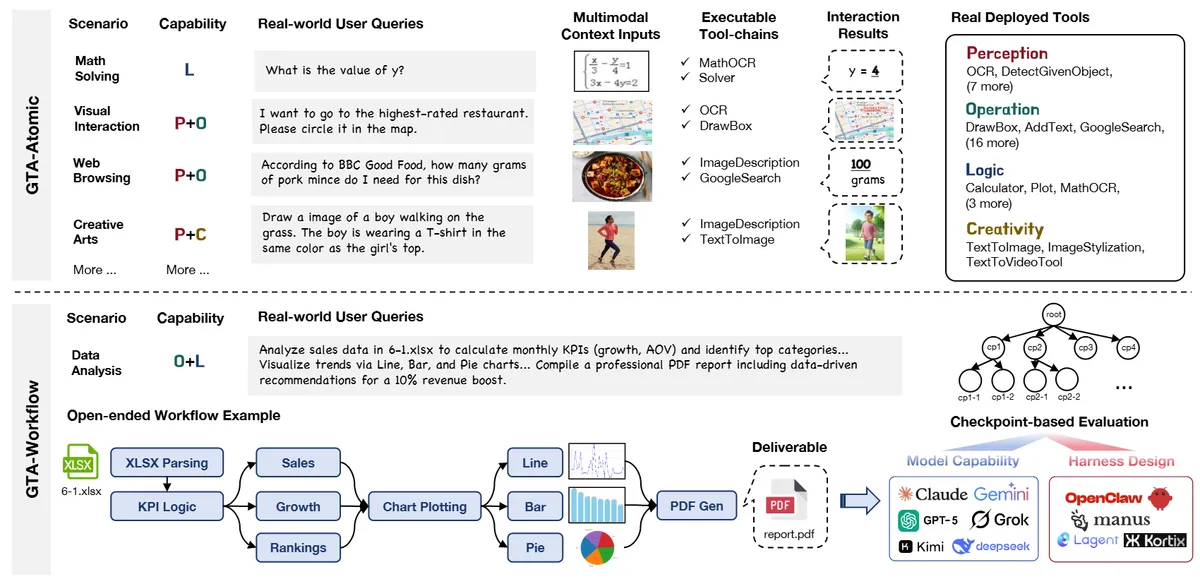
Это важно не потому, что авторы придумали ещё одну таблицу. Напротив: GTA-2 интересен тем, что он пытается уйти от игрушечных тестов на один вызов инструмента. В нём есть два слоя: GTA-Atomic для коротких задач и GTA-Workflow для длинных сценариев с финальным артефактом, реальными инструментами и мультимодальным контекстом. И именно на втором слое видно, где заканчивается маркетинг про «агенты уже работают».
Факты и цифры ниже проверены 21 апреля 2026 года по arXiv-версии GTA-2, опубликованной 17 апреля 2026 года, и официальному репозиторию open-compass/GTA, где 20 апреля появились paper, dataset и актуальный leaderboard. У этого бенчмарка результаты и состав моделей могут обновляться, поэтому перед закупкой или сравнением стеков сверяйте текущий репозиторий.
GTA-2 измеряет не один вызов инструмента, а рабочий процесс
Авторы называют GTA-2 иерархическим бенчмарком. Нижний слой, GTA-Atomic, наследует исходный GTA и проверяет короткие closed-ended задачи на точность работы с инструментами. Верхний слой, GTA-Workflow, переключается на длинные open-ended сценарии, где агент должен не просто выбрать инструмент, а собрать конечный артефакт: отчёт, файл, документ, таблицу или другой результат.
Разница не косметическая. В официальном README авторы прямо пишут, что GTA-Workflow собран из реальных задач с human-in-the-loop пайплайном. Источники задач - не только внутренние заготовки, но и запросы из агентных продуктов вроде Manus, Kortix, Flowith, Minimax Agent, CrewAI, а также реальные пользовательские потребности с Reddit и Stack Exchange. Для бенчмарка такого типа это важнее громкого бренда модели: синтетический запрос можно натренировать, а длинный рабочий сценарий приходится действительно исполнять.
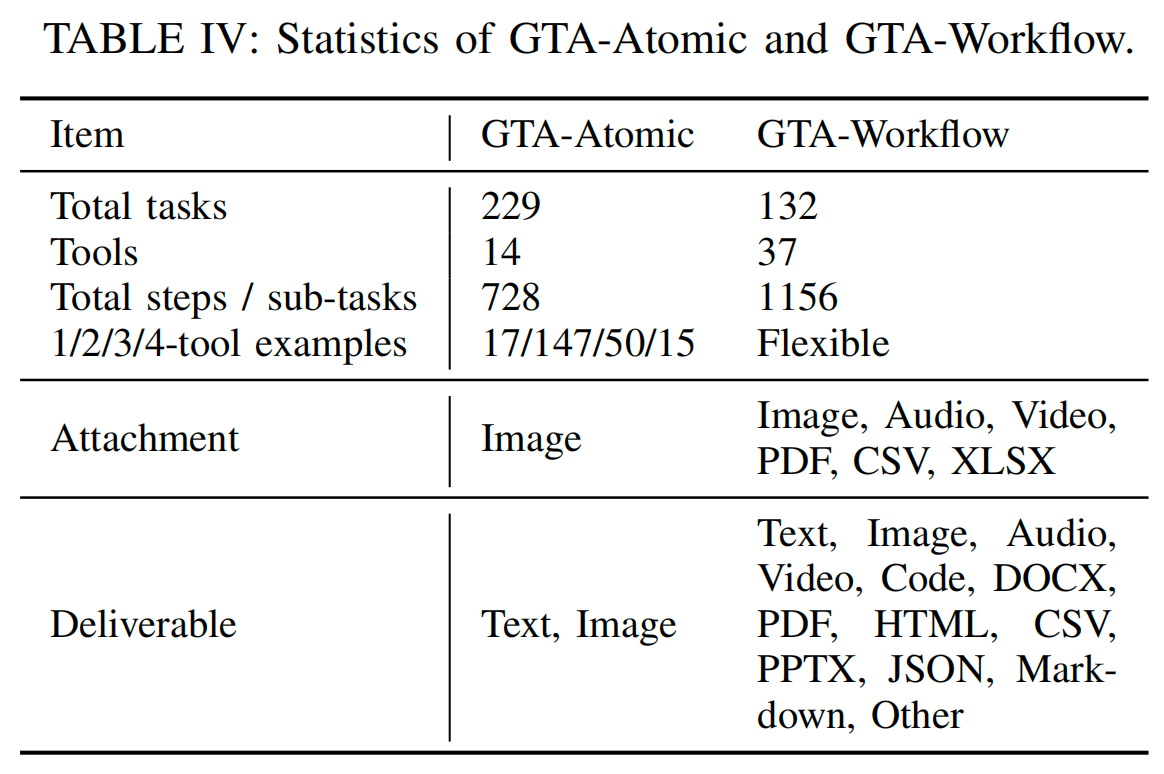
| Параметр | GTA-Atomic | GTA-Workflow |
|---|---|---|
| Число задач | 229 | 132 |
| Число инструментов | 14 | 37 |
| Общий объём шагов / подзадач | 728 шагов | 1156 подзадач |
| Вложения | Изображения | Изображения, аудио, видео, PDF, CSV, XLSX |
| Типы итогового результата | Текст, изображение | Текст, изображение, аудио, видео, код, DOCX, PDF, HTML, CSV, PPTX, JSON, Markdown и другие |
Отдельно полезно посмотреть на разрез категорий. В GTA-Workflow больше всего задач по data analysis и education & instruction, затем идут planning & decision, creative design, marketing strategy и retrieval & QA. Иными словами, бенчмарк тестирует не «чистый reasoning», а типичную офисную и продуктовую работу, где агент должен собрать итоговый результат из нескольких шагов.
Ключевая идея оценки - recursive checkpoint-based evaluation. Авторы раскладывают цель на проверяемые подцели и разделяют fine-grained и coarse-grained успех. По подписи к таблице GTA-Workflow, Leaf SR отражает более детальную, промежуточную успешность, а Root SR - общий успех по задаче целиком. Практически это означает простую вещь: агент может неплохо проходить отдельные checkpoints и всё равно не довозить финальный результат.
Лидерборд показывает разрыв между tool use и финальным результатом
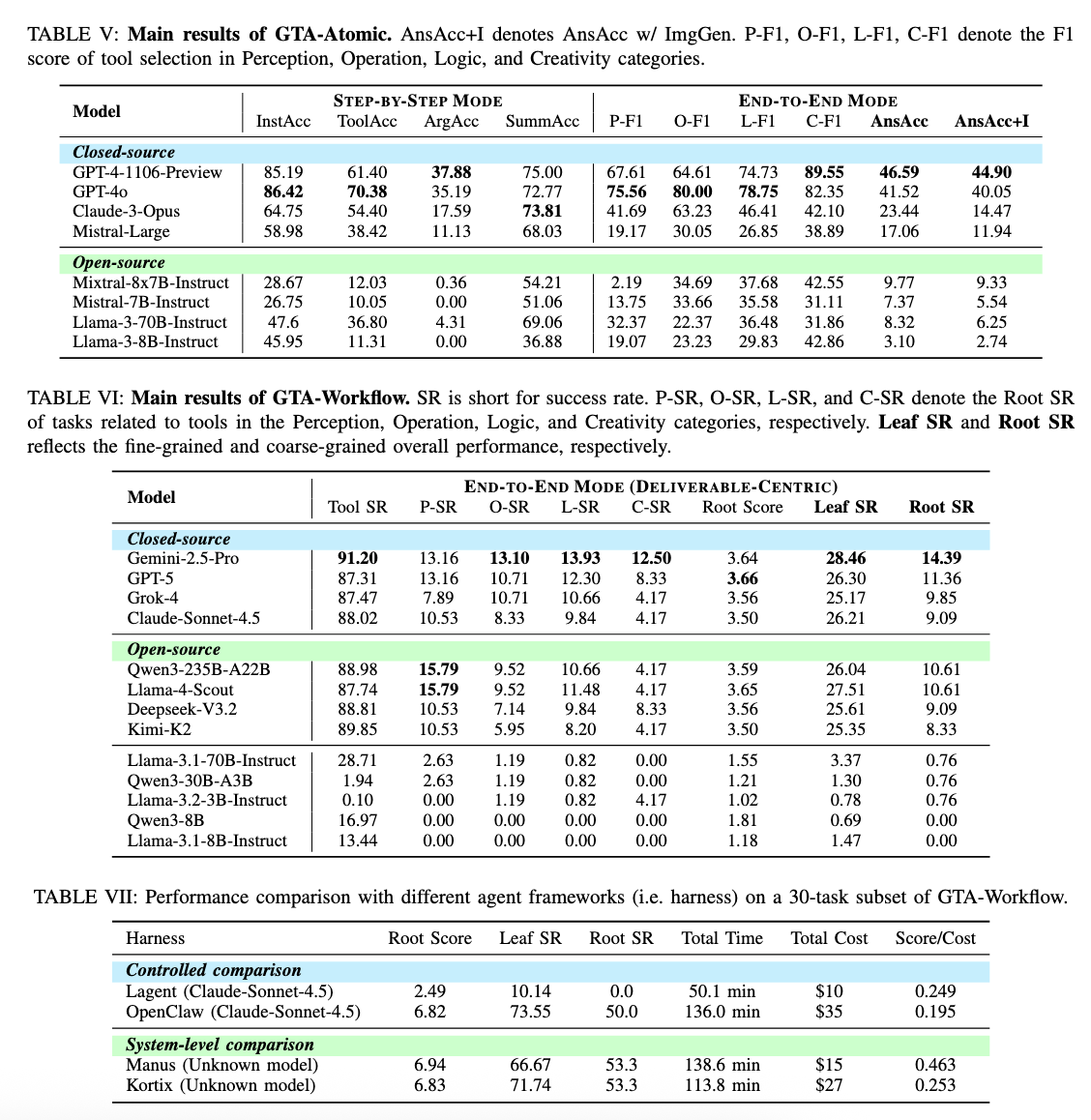
Самая полезная часть GTA-2 - не абстрактный тезис про capability cliff, а цифры. На части GTA-Workflow модели выбирают инструменты заметно лучше, чем заканчивают работу. У лидеров Tool SR около 87-91%, но Root SR остаётся в диапазоне 9-14%. То есть агент часто начинает правильно, но рассыпается на длинной дистанции.
| Модель | Tool SR | Leaf SR | Root SR |
|---|---|---|---|
| Gemini 2.5 Pro | 91,20% | 28,46% | 14,39% |
| GPT-5 | 87,31% | 26,30% | 11,36% |
| Qwen3-235B-A22B | 88,98% | 26,04% | 10,61% |
| Llama-4-Scout | 87,74% | 27,51% | 10,61% |
| Claude Sonnet 4.5 | 88,02% | 26,21% | 9,09% |
У этого разрыва есть важное редакционное следствие. Если смотреть только на инструментальные метрики или на красивые демо, легко решить, что агентный стек уже почти готов к реальной работе. GTA-2 показывает более жёсткую картину: между «умеет пользоваться инструментом» и «доводит задачу до финального артефакта» лежит огромная дистанция. Именно поэтому высокий лидерборд без разбора методики всё ещё опасен. Мы уже писали об этом в материале «Бенчмарки ИИ-агентов ломаются: почему 100% не значит способность», но GTA-2 добавляет другой слой: здесь метрика не сломана, просто сама способность к длинной работе пока заметно слабее обещаний рынка.
Ещё одна неприятная деталь видна уже в abstract paper: авторы прямо пишут, что передовые модели и на атомарных задачах остаются ниже 50%. То есть проблема начинается не только на длинных сценариях. Даже короткая end-to-end работа с инструментами остаётся далёкой от надёжного уровня. На части GTA-Workflow это накапливается: каждый следующий шаг добавляет новый шанс ошибиться в планировании, вызвать не тот инструмент, потерять контекст, неверно собрать промежуточные данные или испортить финальный формат результата.
Исполнительные оболочки помогают, но не отменяют слабость базовой модели
Самый интересный кусок GTA-2 для продуктовых команд - не соревнование моделей, а сравнение harnesses. Авторы отдельно считают подмножество из 30 задач GTA-Workflow и показывают, насколько сильно оболочка вокруг модели меняет итог.
| Harness | Leaf SR | Root SR | Время | Стоимость |
|---|---|---|---|---|
| Lagent (Claude Sonnet 4.5) | 10,14% | 0,0% | 50,1 мин | $10 |
| OpenClaw (Claude Sonnet 4.5) | 73,55% | 50,0% | 136,0 мин | $35 |
| Manus (модель не раскрыта) | 66,67% | 53,3% | 138,6 мин | $15 |
| Kortix (модель не раскрыта) | 71,74% | 53,3% | 113,8 мин | $27 |
Здесь важно не переинтерпретировать цифры. Это не доказательство, что Manus внезапно «решил проблему агентов». Во-первых, сравнение идёт на подмножестве из 30 задач. Во-вторых, для Manus и Kortix авторы не раскрывают модель в этой таблице. Но главный вывод всё равно жёсткий: один и тот же базовый модельный уровень может вести себя радикально по-разному в зависимости от исполнительной оболочки. На том же Claude Sonnet 4.5 Lagent даёт Root SR 0,0%, а OpenClaw - 50,0%.
Для Toolarium это важный мост к инфраструктурной теме. В статье Cloudflare Agent Cloud OpenAI: зачем агентам боевой контур мы уже разбирали, что вокруг модели быстро растёт отдельный слой среды исполнения, состояний, маршрутизации и восстановления. GTA-2 даёт этому количественное подтверждение: хорошая исполнительная оболочка не делает слабую модель сильной, но может резко поднять шанс довести рабочий сценарий до конца.
Почему capability cliff - это продуктовая проблема, а не только академический термин
Capability cliff в GTA-2 выглядит особенно полезным термином, потому что он описывает знакомый продуктовый сбой. Агент уверенно проходит первые шаги, правильно выбирает инструменты, неплохо выглядит в промежуточных логах, а затем проваливает финальную сборку результата. Для команды это худший тип ошибки: демонстрация кажется убедительной, а полезный выход не получается.
Отсюда и главный риск завышенных ожиданий. Если смотреть только на Tool SR или на хорошие промежуточные логи, можно недооценить стоимость последней мили. А именно она чаще всего важна бизнесу: дошёл ли агент до PDF-отчёта, корректного CSV, рабочего документа, чистого куска кода, письма без фактических дыр или презентации, которую не стыдно открыть на встрече.
Это хорошо рифмуется с нашими наблюдениями по длинным инженерным сценариям. В кейсе про libGDX и накопление ошибок ИИ-агентами проблема была не в одном неудачном действии, а в том, что автономная система быстро наращивает серию мелких промахов, которые человек замечает уже слишком поздно. GTA-2 показывает тот же механизм в форме бенчмарка.
Как читать GTA-2 без самообмана
Из GTA-2 стоит вынести не одно число, а набор вопросов к своему стеку:
- Смотрите ли вы на Root SR, а не только на метрики уровня инструмента и красивые логи?
- Сравниваете ли отдельно базовую модель и исполнительную оболочку, или смешиваете их в одну «умность агента»?
- Есть ли у вас собственный workflow-бенчмарк с финальным артефактом, а не только тест на отдельный вызов инструмента?
- Понимаете ли вы цену успешного прогона: время, число итераций, стоимость и долю ручного вмешательства?
Если кратко, GTA-2 не доказывает, что AI-агенты бесполезны. Он показывает более неприятную и полезную вещь: рынок пока намного лучше продаёт образ «цифрового сотрудника», чем реально доводит длинные задачи до конца. Лучшие системы уже умеют пройти часть дистанции. Но переход от промежуточных шагов к надёжному финальному результату остаётся узким местом и для моделей, и для harnesses.
Главный вывод
GTA-2, вероятно, станет одной из тех работ, на которые будут ссылаться каждый раз, когда очередной vendor пообещает «универсального агента для работы». И правильно. В апреле 2026 года бенчмарк показывает очень трезвую картину: у frontier-моделей высокая вероятность неплохо начать рабочий сценарий, заметно меньшая вероятность пройти checkpoints и совсем скромный шанс довести задачу до финального результата. Лучший Root SR на полном leaderboard - 14,39%. Даже сильные harnesses на подмножестве задач не превращают это в solved problem.
Для разработчиков и менеджеров вывод простой. Агентов стоит оценивать не по тому, насколько эффектно они начинают, а по тому, насколько часто они заканчивают. И если вы строите свой stack, основной инженерный вопрос теперь звучит не «какая модель самая умная», а «какая связка модели, среды исполнения и checkpoint-оценки реально довозит работу до конца».



