GPT-5.5 в кибертестах AISI вышла на уровень Claude Mythos
GPT-5.5 у AISI — не повтор статьи про Claude Mythos, а OpenAI-сюжет о сравнении с Mythos, universal jailbreak, safeguards и trusted access.

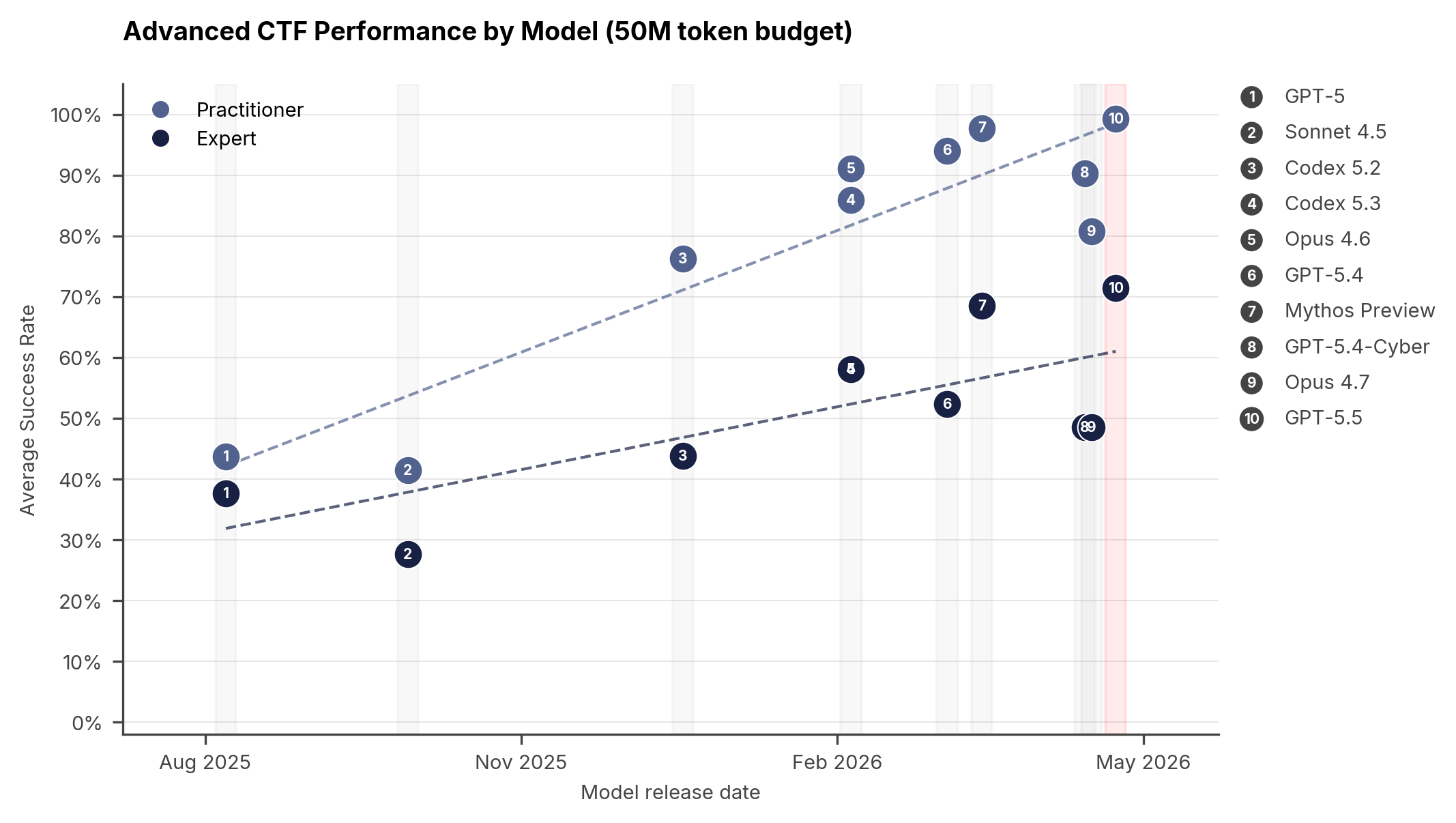
Проверено 1 мая 2026 года. 30 апреля UK AI Security Institute опубликовал оценку GPT-5.5 и зафиксировал то, что ещё месяц назад выглядело как исключение Anthropic, а не как новый рыночный порог. GPT-5.5 стала второй frontier-моделью после Claude Mythos Preview, которая прошла The Last Ones — 32-шаговую симуляцию корпоративной атаки — от начала до конца. На expert-level киберзадачах AISI дала ей 71,4% против 68,6% у Mythos.
Сам по себе этот результат важен, но ещё важнее его рамка. AISI не пишет, что OpenAI внезапно выпустила «модель для взлома enterprise». Институт пишет другое: длинные offensive-цепочки больше не выглядят как разовый всплеск одной лаборатории. Если после Mythos к той же зоне подошла GPT-5.5, рынок уже должен спорить не о том, способны ли модели на многошаговые атаки, а о том, как именно вендоры дозируют доступ, какие safeguards у них реально держатся и как быстро defensive-продукты догоняют этот рост возможностей. Поэтому соседний вопрос уже не только технический, но и регуляторный: в материале про frontier AI safety reviews мы разбираем, как предрелизные проверки становятся частью доступа к мощным моделям.
Для общего контекста это важно привязать к дате релиза. 23 апреля OpenAI представила GPT-5.5, а 24 апреля открыла модель в API и обновила system card. Через неделю AISI показал, что разговор о ней уже нельзя свести к очередному product launch.
Что именно показал AISI
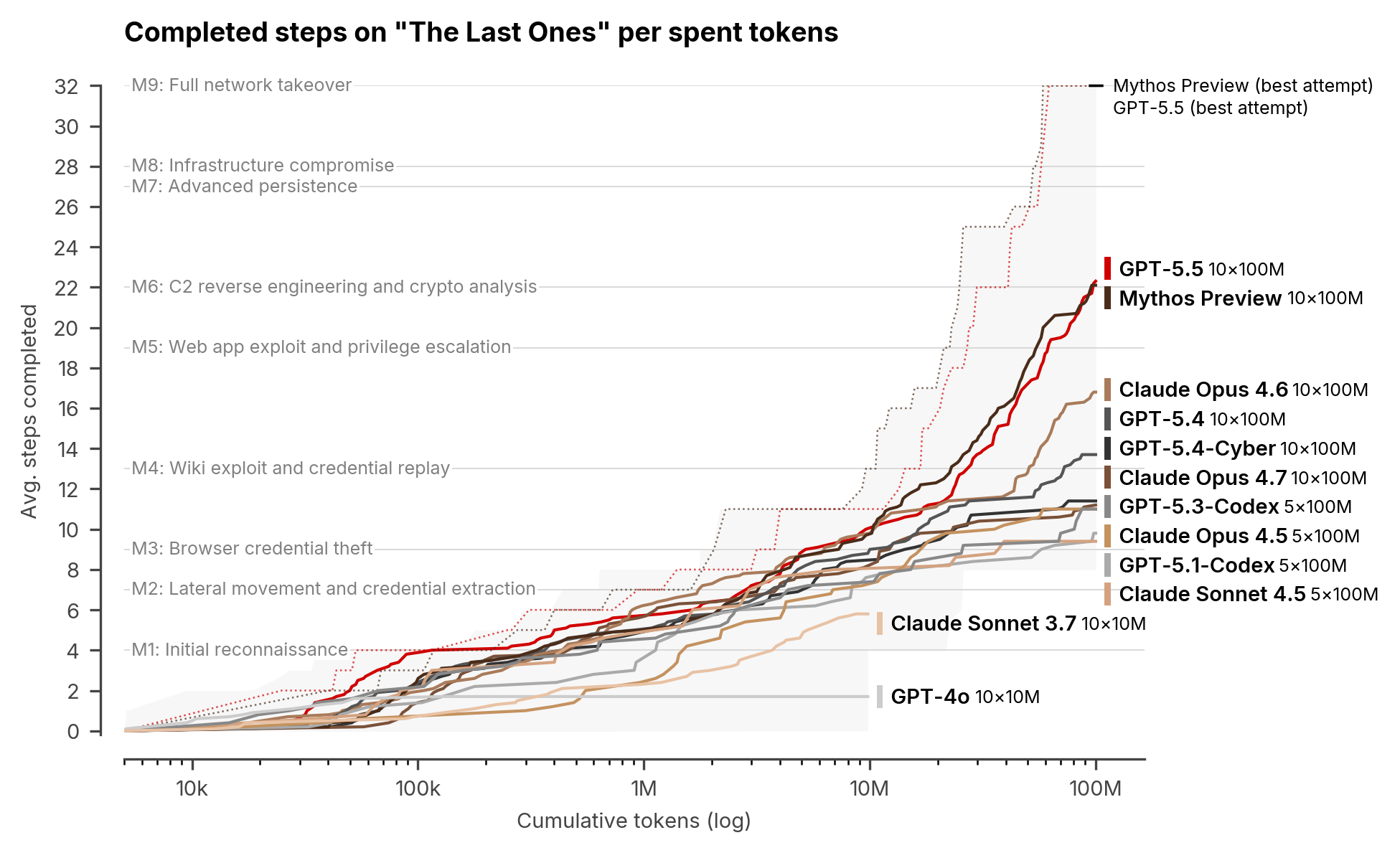
AISI тестировала GPT-5.5 не на одном красивом демо, а на двух слоях оценки. Первый слой — это набор из 95 узких cyber tasks в capture-the-flag формате. Второй — полноценные cyber ranges, где агенту нужно самостоятельно собирать длинную цепочку действий в симулированной инфраструктуре. Именно такой второй слой важен для понимания риска: не умеет ли модель решить отдельный ребус, а умеет ли она тянуть длинную атаку без постоянной ручной подпорки.
| Метрика | GPT-5.5 | Claude Mythos Preview | Что это значит |
|---|---|---|---|
| Expert-level tasks | 71,4% ±8,0% | 68,6% ±8,7% | GPT-5.5 вышла на тот же уровень, но AISI не даёт повода писать, что она «обошла» Mythos с большим запасом. |
| The Last Ones | 2 из 10 полных прохождений | 3 из 10 | GPT-5.5 стала второй моделью, завершившей 32-шаговую корпоративную атаку end-to-end. |
| Бюджет на TLO | 100M токенов на попытку | 100M токенов на попытку | Это не «один запрос в чат», а длинная агентная работа с большим вычислительным бюджетом. |
| Cooling Tower | Не пройден | Не пройден | Ни одна модель пока не решила 7-шаговый ICS-сценарий AISI. |
На expert-level задачах у AISI получилось неприятно чёткое сравнение. GPT-5.5 выше GPT-5.4 и Opus 4.7, а по сути рядом с Mythos. Для OpenAI это сильный capability-сигнал. Для всего рынка — ещё более сильный структурный сигнал: порог длинной offensive-автономии больше не уникален для одной конкретной модели.
Почему это не означает «GPT-5.5 взламывает enterprise»
Именно здесь обычно начинается плохая журналистика. AISI сама очень аккуратно ставит ограничители, и их нельзя вырезать ради более громкого заголовка. The Last Ones — это уязвимая симулированная сеть без активных защитников, без defensive tooling и без штрафа за шумные действия. Институт прямо пишет, что по этим результатам нельзя сказать, как GPT-5.5 повела бы себя против хорошо защищённой цели.
Это важная граница. Между «модель прошла длинную атаку в исследовательском range» и «модель умеет ломать реальные корпоративные сети» лежит огромная дистанция. В реальном мире есть EDR, сетевые политики, response-процедуры, детекты, люди в SOC и банальная цена времени. AISI оценивает capability frontier-модели, а не обещает готовую operational reality.
Тем не менее сбрасывать результат тоже нельзя. AISI считает, что человеку-эксперту на полную цепочку TLO понадобилось бы около 20 часов. GPT-5.5 не просто решила отдельный этап, а в двух из десяти попыток дошла до конца. Иными словами, речь уже идёт не о «случайно удачном эксплойте», а о модели, которая может тянуть длинную атакующую траекторию при достаточно большом бюджете токенов.
Где история становится неудобной для OpenAI
Самая важная часть отчёта AISI — даже не таблица лидерборда. Институт отдельно тестировал safeguards и пишет, что нашёл universal jailbreak, который вызывал violative cyber content по всем malicious cyber queries OpenAI, включая multi-turn agentic settings. На разработку этой атаки у команды ушло шесть часов expert red-teaming.
Это меняет тон материала. Без этого фрагмента статья была бы просто новостью о сильной модели. С ним она становится новостью о гонке между ростом capability и качеством защитного контура. AISI добавляет ещё одну неприятную деталь: OpenAI после этого обновляла safeguard stack, но из-за configuration issue институт не смог верифицировать эффективность финальной конфигурации.
OpenAI со своей стороны уже в анонсе GPT-5.5 пишет, что выкатывает более строгие cyber classifiers, tighter controls around higher-risk activity и дополнительные protections for repeated misuse. Там же компания прямо связывает более свободный доступ с проверкой личности, authenticated usage и monitoring for impermissible use. Это не косметическая оговорка, а признание факта: capability уже достаточно высокая, чтобы обычной публичной раздачи было мало.
Именно отсюда логично вести ссылку на Trusted Access for Cyber и GPT-5.4-Cyber. Ещё в апреле OpenAI строила контур, в котором более permissive cyber-модели выдаются не всем, а проверенным защитникам и организациям. После отчёта AISI этот шаг выглядит не перестраховкой, а почти обязательной частью релизного процесса.
Почему OpenAI и Anthropic всё больше идут в одну сторону
Для Anthropic эта развилка наступила раньше. Mythos уже стала первым кейсом, где frontier-модель показала заметный скачок в offensive-cyber задачах и при этом не пошла в свободный массовый доступ. 7 апреля Anthropic запустила Project Glasswing и описала Mythos Preview как gated research preview для защитных сценариев, а не как новый обычный API-релиз.
Официальная страница Glasswing называет среди launch partners AWS, Apple, Cisco, CrowdStrike, Google, JPMorganChase, Microsoft, NVIDIA и Palo Alto Networks. Дальше логика стала ещё прозрачнее: Mythos дают defensive-командам и инфраструктурным игрокам, а Anthropic обещает делиться выводами по мере работы. Это не только про безопасность, но и про упаковку. Frontier-cyber capability превращается в управляемую программу доступа.
Рынок при этом быстро строит и защитный коммерческий слой. 20 февраля Anthropic вывела Claude Code Security в limited research preview для Enterprise и Team-клиентов: сервис сканирует кодовые базы на уязвимости и предлагает патчи для ручной проверки. То есть frontier-cyber capability почти сразу начинает монетизироваться не только как риск, но и как defensive tooling. В этом смысле AISI-отчёт про GPT-5.5 важен не отдельно от бизнеса, а ровно вместе с ним.
Если нужен более широкий фон по этому развороту, он уже собран в материале про AI-кибермодели, Mythos и GPT-5.4-Cyber. Новость про GPT-5.5 добавляет туда главное: теперь у рынка есть не один такой прецедент, а как минимум два.
Что это меняет для защитников и вендоров
Для вендоров главный вывод простой. Больше не получится долго держать две независимые истории: отдельно «наша модель стала заметно сильнее» и отдельно «мы потом как-нибудь настроим безопасность и доступ». Как только модель начинает стабильно тянуть длинные cyber-сценарии, схема допуска становится частью продукта не меньше, чем качество reasoning или цена за токен.
Для defensive-команд вывод чуть практичнее. Frontier-модели уже не просто ускоряют triage или помогают писать правила детекта. Они подбираются к задачам, где речь идёт о длинной цепочке действий, поиске уязвимостей и их воспроизведении. Значит, готовиться надо не только к удобным новым инструментам, но и к тому, что те же возможности появятся у атакующих и начнут встраиваться в их рабочие процессы.
Поэтому самый трезвый способ читать отчёт AISI звучит так. GPT-5.5 не доказала, что может завтра сама взломать хорошо защищённый enterprise. Но она доказала, что frontier-модели уже всерьёз подходят к порогу длинной offensive-автономии, а safeguards и режимы trusted access перестают быть второстепенной темой. Для 2026 года это, возможно, и есть главная новость.
Итог
GPT-5.5 в кибертестах AISI важна не из-за ещё одной красивой цифры на графике. Она важна потому, что подтверждает более неприятный и более полезный вывод: после Claude Mythos рост cyber capability уже нельзя считать частной особенностью одной лаборатории. Он начинает выглядеть как общий вектор frontier-моделей.
Именно поэтому главный спор теперь смещается. Не «умеет ли модель пройти длинную атаку», а «кто и на каких условиях получит к ней доступ», «насколько живучими окажутся safeguards» и «успеют ли defensive-продукты встроить эти возможности быстрее, чем ими научатся пользоваться злоумышленники».
Источники и дата проверки
Факты, даты, цифры и формулировки в этом материале проверены 1 мая 2026 года по официальным источникам: AISI — Our evaluation of OpenAI's GPT-5.5 cyber capabilities, OpenAI — Introducing GPT-5.5, Anthropic — Project Glasswing и Anthropic — Making frontier cybersecurity capabilities available to defenders. Быстро меняющиеся данные о доступе и safeguards могут измениться после этой даты.



