AI-кибермодели: Mythos, GPT-5.4-Cyber и новая гонка защиты
AISI проверил Claude Mythos Preview, OpenAI запускает GPT-5.4-Cyber, а безопасность всё больше зависит от бюджета токенов и проверенного доступа к моделям.

AI-кибермодели за одну неделю перестали быть внутренней темой лабораторий. 13 апреля 2026 года британский AI Security Institute опубликовал независимую оценку Claude Mythos Preview, а 14 апреля OpenAI расширила Trusted Access for Cyber и представила GPT-5.4-Cyber. По состоянию на 15 апреля 2026 года это уже не спор о том, какая модель лучше решает CTF. Это начало рынка, где доступ к самым сильным моделям для кибербезопасности выдают через проверку пользователя, а результат всё сильнее зависит от бюджета токенов.
Главная интрига не в том, что одна модель «научилась взламывать». Такой заголовок был бы слишком грубым. Передовые модели начали проходить длинные агентные сценарии, где нужно не только найти уязвимость, но и связать десятки действий в рабочую атаку. Для защитников это шанс ускорить аудит кода. Для атакующих — та же логика, только без этических ограничений.
Контекст по самому Mythos мы уже разбирали отдельно в статье «Claude Mythos и кибербезопасность: где реальный риск». Здесь фокус шире: почему cyber стал полигоном для новых моделей, зачем Anthropic и OpenAI делают доступ гейтированным и почему экономика инференса становится частью защитной стратегии.
Что считать AI-кибермоделью
AI-кибермодель — не обязательно отдельная «модель для взлома». Чаще это передовая модель с дообучением, обвязкой и политиками доступа, которые позволяют ей меньше отказываться от легитимных задач безопасности: анализа бинарников, поиска уязвимостей, проверки патчей, разбора баг-репортов и построения воспроизводимых PoC.
У Anthropic это Claude Mythos Preview внутри Project Glasswing. Компания открыла доступ участникам программы 7 апреля 2026 года и описывает Mythos как gated research preview для партнёров, которые защищают критическое ПО. У OpenAI похожая логика появилась в Trusted Access for Cyber: пользователи проходят проверку, а самые высокие уровни доступа могут запросить GPT-5.4-Cyber.
| Сигнал | Что подтверждено источниками | Почему это важно |
|---|---|---|
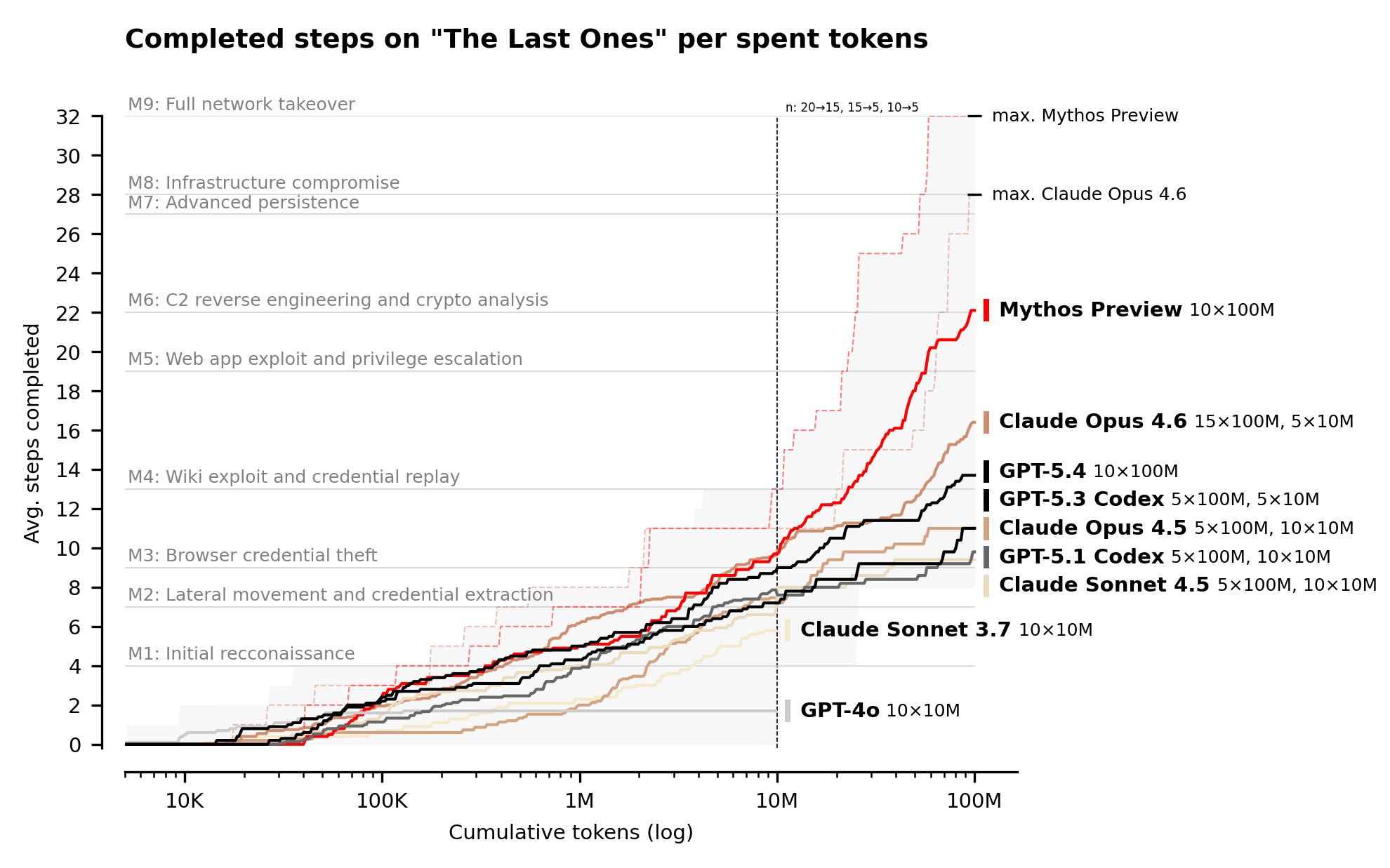
| AISI и Claude Mythos Preview | AISI пишет, что Mythos первым прошёл The Last Ones от начала до конца в 3 из 10 попыток; средний результат — 22 из 32 шагов. | Оценка пришла не от Anthropic, а от государственного института, и тестирует длинную цепочку действий, а не одиночную CTF-задачу. |
| Project Glasswing | Anthropic заявляет о закрытом исследовательском доступе, партнёрах и более чем 40 дополнительных организациях, а также о $100 млн кредитов на использование модели и $4 млн пожертвований организациям безопасности открытого кода. | Самые сильные cyber-возможности не отправляют в общий доступ: их дают защитникам с ограничениями и наблюдением. |
| GPT-5.4-Cyber | OpenAI пишет, что GPT-5.4-Cyber — вариант GPT-5.4 для защитных сценариев с меньшим числом отказов; доступ идёт через расширенные уровни TAC. | OpenAI отвечает не бесплатным публичным релизом, а системой доверенного доступа для проверенных специалистов и команд. |
AISI сместил разговор от CTF к длинным атакам
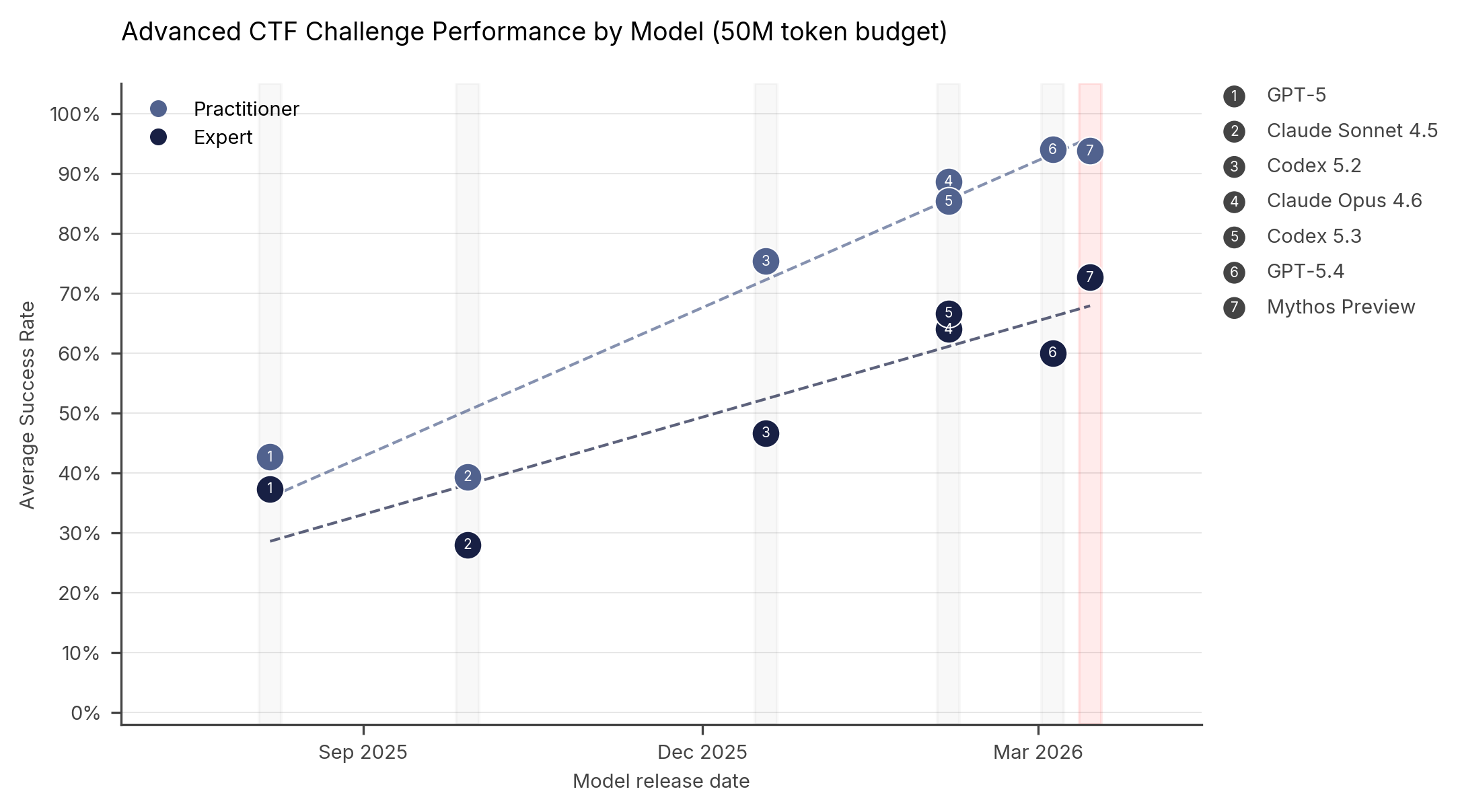
CTF-тесты по-прежнему важны: они дают повторяемые задачи и понятную метрику. В отчёте AISI Mythos Preview достигает 73% успеха на expert-level CTF, причём до апреля 2025 года такие задания не решала ни одна модель в этом наборе. Но главный сдвиг виден не там.
The Last Ones — 32-шаговая симуляция атаки на корпоративную сеть: от первичной разведки до полного захвата. AISI оценивает, что человеку-профессионалу нужно около 20 часов на прохождение такого сценария. Mythos Preview впервые закрыл всю цепочку end-to-end в 3 попытках из 10, а в среднем проходил 22 шага. Следующая модель, Claude Opus 4.6, в среднем проходила 16 шагов.
У этого результата есть важная граница. AISI прямо пишет, что их диапазоны легче реальных хорошо защищённых сред: в них нет активных защитников, защитного инструментария и штрафов за действия, которые подняли бы тревогу в настоящей сети. Поэтому корректный вывод звучит аккуратно: Mythos уже способен автономно атаковать небольшие, слабозащищённые и уязвимые корпоративные среды, если ему дали сетевой доступ и цель. Из этого нельзя делать вывод, что модель пробьёт зрелую SOC-команду.
Почему OpenAI делает ставку на проверенный доступ
OpenAI выбрала другой публичный акцент. Компания говорит, что расширяет Trusted Access for Cyber до тысяч проверенных индивидуальных защитников и сотен команд, которые отвечают за критическое ПО. В верхних уровнях программы можно запросить GPT-5.4-Cyber — версию GPT-5.4 с менее жёсткими отказами для легитимных задач безопасности.
По описанию OpenAI, GPT-5.4-Cyber снижает границу отказов для защитной работы и включает сценарии вроде реверс-инжиниринга бинарников: анализа скомпилированного ПО без исходников на вредоносное поведение, уязвимости и устойчивость. Это важно для команд, которые проверяют проприетарные агенты, закрытые бинарники, драйверы, плагины и внутренние инструменты.
Здесь нужна трезвая формулировка. GPT-5.4-Cyber не объявлен как модель для всех пользователей ChatGPT. OpenAI пишет об ограниченном поэтапном развёртывании для проверенных поставщиков безопасности, организаций и исследователей. В материале про OpenAI и ограниченный доступ к модели для кибербезопасности мы разбирали именно эту логику: чем опаснее модель в двойном назначении, тем важнее не только сама модель, но и кто получает к ней доступ.
Инференс-бюджет становится частью защиты
Самый неприятный вывод дал не пресс-релиз, а форма графика AISI. На The Last Ones модели продолжали делать больше шагов при росте token budget до 100 млн токенов. AISI прямо отмечает, что результаты, вероятно, продолжили бы улучшаться и за пределами этого бюджета.
Дрю Бройниг в разборе Cybersecurity Looks Like Proof of Work Now формулирует это как экономику proof-of-work: чтобы укрепить систему, защитнику нужно потратить больше токенов на поиск эксплойтов, чем атакующий готов потратить на их поиск. Он также оценивает 100 млн токенов на попытку Mythos примерно в $12 500, а десять попыток — в $125 000. Эта сумма — расчёт автора на основе доступной цены Mythos и бюджета теста, а не официальный прайс AISI.
Если такая динамика сохранится, безопасность станет менее похожа на разовый аудит и больше похожа на постоянную вычислительную гонку. Дешёвый код можно сгенерировать быстро. Доказать, что он выдержит атаки, будет стоить дороже: нужны прогоны, воспроизведения, triage, патчи и повторные проверки.
Для открытого кода это парадоксально хорошая новость. Чем больше организаций зависит от одной библиотеки, тем рациональнее всем вместе оплачивать её машинный аудит и усиление защиты. Мы уже писали об этом в материале «Открытые модели ИИ в кибербезопасности: урок Mythos»: проблема не только в том, кто умеет находить уязвимости, а в том, кто сможет оплатить и организовать проверку большого числа зависимостей.
Что меняется для команд безопасности
Первый практический вывод: одного запрета на «опасные запросы» уже мало. У OpenAI и Anthropic видна общая схема: обычные модели остаются с ограничениями, а режимы с меньшим числом отказов дают только проверенным пользователям и командам. Для компаний это означает, что внутренние ИИ-инструменты тоже должны учитывать контекст пользователя, цель запроса, журнал действий и уровень доступа к среде.
Второй вывод — ускорение цикла патчей. Anthropic в своём техническом разборе Mythos пишет, что N-day exploit chains уже можно строить автономно, начиная с CVE identifier и commit hash. Если раньше квалифицированному исследователю требовались дни или недели на одну уязвимость, теперь окно между раскрытием и эксплуатацией может сжиматься. Автообновления, срочные обновления зависимостей и воспроизводимые сборки становятся не удобством, а защитной механикой.
Третий вывод касается AI-агентов. Если агент умеет искать уязвимости и исполнять код, его нельзя запускать рядом с секретами и широкой сетью. Нужны песочницы, сетевые политики, отдельное хранилище секретов и журналирование. Иначе модель, которая должна помогать защитникам, превращается в новый путь к утечке ключей.
Наконец, компаниям придётся считать бюджет усиления защиты так же явно, как бюджет разработки. В старой схеме безопасность часто приходила в конце проекта. В новой схеме разработка, ревью и машинная проверка на уязвимости будут идти отдельными фазами: сначала код появляется, потом его приводят в порядок, затем его атакуют до тех пор, пока не кончится заданный бюджет или не перестанут находиться серьёзные дефекты.
Итог
AI-кибермодели не отменяют работу специалистов по безопасности. Они меняют масштаб и темп. AISI показал, что Mythos уже проходит часть длинного корпоративного сценария атаки лучше прежних моделей. Anthropic отвечает закрытым доступом через Project Glasswing. OpenAI расширяет TAC и вводит GPT-5.4-Cyber для проверенных защитников.
Для разработчиков и CISO главный вывод простой: cyber становится задачей, где выигрывает не тот, кто один раз заказал аудит, а тот, кто быстрее и регулярнее гоняет модели по своему коду, исправляет находки и сокращает время доставки патчей. В этой гонке токены становятся таким же ресурсом безопасности, как люди, логи и инфраструктура.


