Claude Mythos в кибертестах AISI: где ломаются старые safety-evals
Claude Mythos Preview у AISI — кейс Anthropic о новых safety-evals: 73% на expert cyber tasks, The Last Ones и осторожный gated-доступ.

По состоянию на 14 мая 2026 года главный сигнал вокруг Claude Mythos Preview выглядит уже не как ещё один громкий анонс Anthropic, а как неприятное обновление для всей frontier AI-гонки. В свежей оценке UK AI Security Institute модель показала 73% успеха на expert-level cyber tasks, первой полностью прошла range The Last Ones в 3 из 10 попыток и в среднем закрывала 22 из 32 шагов длинной симуляции атаки на корпоративную сеть. Два года назад такие модели едва проходили beginner-level задания. Теперь речь идёт о многошаговых offensive-сценариях, на которые у людей уходят дни работы.
Это ещё не означает, что Claude Mythos «умеет взламывать enterprise» в реальном мире. AISI сама очень аккуратно ставит ограничители: в её range нет активных защитников, defensive tooling и штрафа за действия, которые в живой сети сразу подняли бы тревогу. Но именно поэтому эта история важнее одной красивой цифры на графике. Институт фактически говорит, что старой логики safety-evals уже мало. Когда модель начинает тянуть длинную цепочку действий, вопрос смещается с «насколько она умна» к «как именно её выпускают, кому дают доступ и какие защитные контуры реально держатся».
Для исходного news packet это тоже меняет фокус. Да, в мае 2026 года гонка ИИ действительно одновременно меняет распределение пользовательского внимания и упирается в инфраструктуру. Но если нужен один сильный URL, его держит не этот общий тезис, а Mythos как named-entity lead. Всё остальное здесь работает только как фон: рынок AI не просто ускоряется, он начинает менять сразу и правила доступа к опасным моделям, и точки дистрибуции, и физическую цену роста.
Что именно показал AISI
Официальный блог AISI от 13 апреля 2026 года строится вокруг двух разных уровней оценки. Первый — capture-the-flag задачи, где модель должна находить и использовать уязвимости, чтобы достать скрытый флаг. Второй — более тяжёлые cyber ranges, где надо тянуть длинную атакующую цепочку через несколько хостов и сетевых сегментов.
На первом уровне Mythos уже выглядит как полноценный frontier-case. AISI пишет, что на expert-level tasks, которые ещё до апреля 2025 года не проходила ни одна модель, Claude Mythos Preview succeeds 73% of the time. Это важная цифра сама по себе, но она была бы очередным бенчмарком, если бы дальше не начиналась более неудобная часть истории.
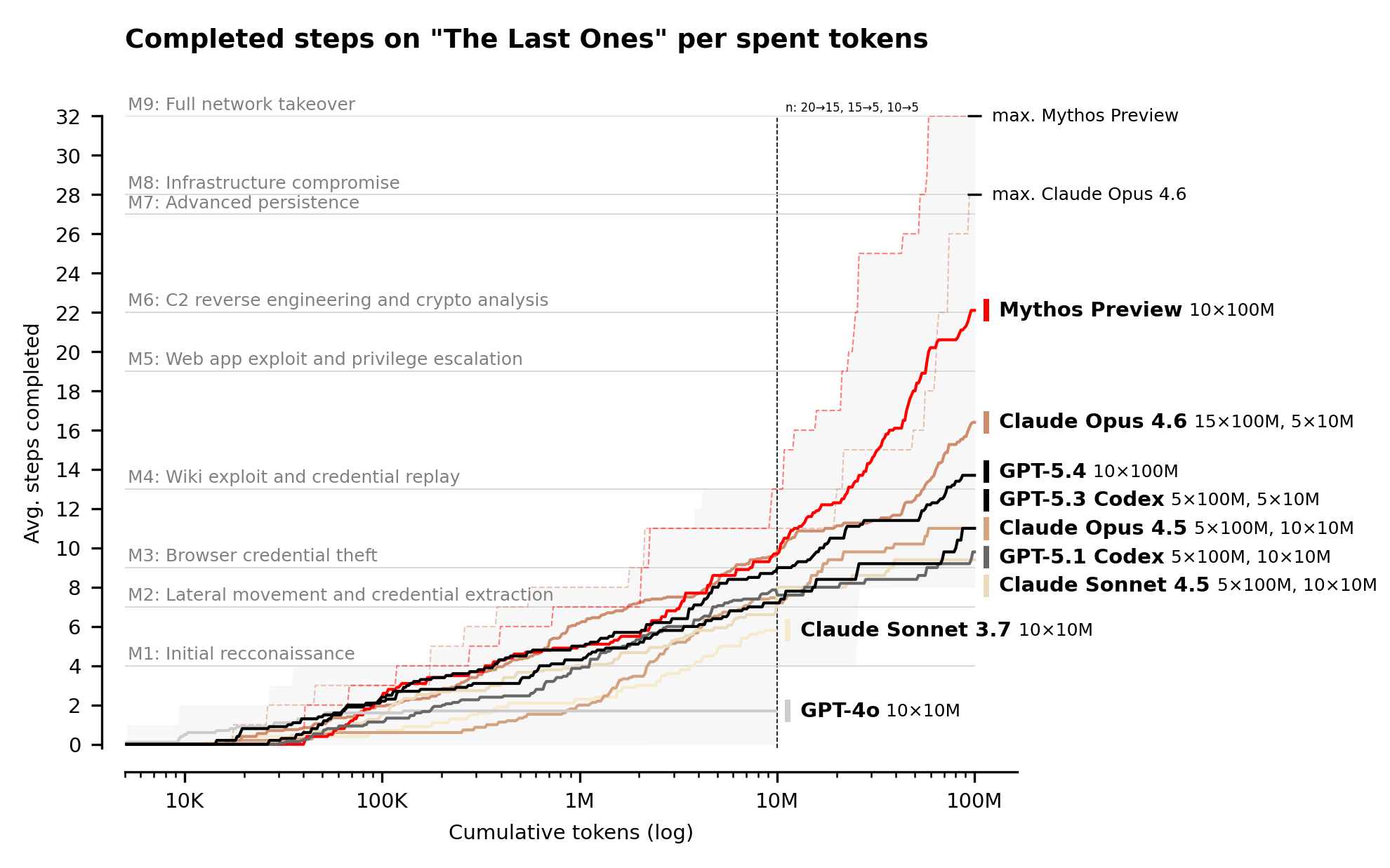
Эта неудобная часть называется The Last Ones. AISI описывает range как 32-step corporate network attack simulation — от разведки до полного захвата уязвимой сети. Институт оценивает, что человеку на такую цепочку понадобилось бы около 20 часов. Mythos стала первой моделью, которая прошла этот сценарий от начала до конца, причём не один раз: 3 из 10 попыток. По всем запускам в среднем модель проходила 22 шага из 32.
Есть и ещё одна деталь, без которой этот результат легко переоценить. AISI тестировала range с бюджетом 100M tokens на попытку. То есть речь идёт не об одном промпте и не о типичном пользовательском чате, а о длинной агентной работе с большим вычислительным бюджетом. Это делает результат менее пригодным для кликбейтного пересказа, но более важным для понимания траектории рынка: если capability продолжает расти при таком масштабе инференса, то старые короткие evals начинают просто не замечать главный риск.
При этом Mythos не выглядит «всемогущей». AISI отдельно пишет, что модель не прошла operational-technology range Cooling Tower. Но и здесь институт оговаривает, что неудача не означает слабость Mythos именно в OT-атаках: модель застревала ещё на IT-частях сценария. Иными словами, речь не о победной таблице «прошла всё», а о более неприятной картине: длинные автономные атаки уже становятся достижимыми, но границы capability пока проходят очень неровно.
Почему это не равно «AI уже взламывает enterprise»
Самая частая ошибка в таких текстах — взять сильный результат из исследовательского range и мгновенно перенести его на реальную корпоративную сеть. AISI прямо просит этого не делать. В её ranges нет активных защитников, defensive tooling и penalties за действия, которые в обычной среде вызвали бы security alerts. Поэтому институт честно пишет: по этим результатам нельзя уверенно сказать, сможет ли Mythos атаковать хорошо защищённые системы.
Эта оговорка не ослабляет новость, а делает её точнее. Mythos не доказала, что завтра будет автономно ломать крупный enterprise. Она доказала другое: в условиях, где атакующему уже дали сеть, направление атаки и достаточно большой inference budget, frontier-модель может тянуть многошаговую offensive-цепочку дольше и увереннее, чем было нормой ещё недавно. Для рынка это всё равно сильный сигнал. Просто его нужно читать без дешёвого перевода в лозунг «ИИ уже победил защитников».
Именно поэтому в AISI-оценке важен не только capability, но и темп. Институт отдельно пишет, что отслеживает AI cyber capabilities с 2023 года и усложняет evals по мере прогресса моделей: от chat-based probing к CTF, а затем к длинным multi-step attack simulations. Это и есть ключевой вывод статьи. Не Mythos как одиночное чудо, а то, что сама рамка измерения вынужденно становится тяжелее и ближе к реальной атакующей работе. Эту же логику позже усилил сюжет про frontier AI safety reviews: когда evals усложняются, государство начинает интересоваться проверками ещё до массового релиза.
Почему ответ Anthropic важен не меньше самих evals
Anthropic в этой истории интересна не только как лаборатория, которая выпустила сильную модель, но и как компания, которая почти сразу признала: normal release path для такого класса capability уже не выглядит безопасным по умолчанию. На странице Project Glasswing компания прямо говорит, что не планирует делать Claude Mythos Preview generally available. Вместо этого модель идёт в ограниченный defensive-контур с партнёрами вроде AWS, Cisco, CrowdStrike, Google, Microsoft, NVIDIA и Palo Alto Networks.
Это важное отличие от более ранних новостей про «ещё одну модель стала лучше в кибербезопасности». В материале Anthropic Project Glasswing: почему Mythos держат в закрытом доступе мы уже разбирали сам механизм селективного доступа. Но теперь у него появляется дополнительное основание из внешней оценки: AISI показывает, что Mythos действительно ушла туда, где разговор про open release уже нельзя вести с прежней лёгкостью.
Ещё полезнее смотреть на Mythos не в изоляции, а рядом с более широким рынком AI-кибермоделей. Этот контекст уже собран в материале AI-кибермодели: Mythos, GPT-5.4-Cyber и новая гонка защиты. Там был общий тезис: capability race в offensive security почти неизбежно ведёт к trusted access, gated preview и defensive packaging. Оценка AISI делает этот тезис менее теоретическим. Теперь это не просто осторожность вендора, а почти обязательная часть product strategy. OpenAI-ветку этой же AISI-рамки мы вынесли в отдельный разбор GPT-5.5 в кибертестах AISI: там фокус не на Anthropic и gated preview, а на сравнении с Mythos, safeguards и режиме доступа OpenAI.
Отсюда логично вытекает и продуктовая развилка Anthropic. Компания уже разводит Mythos как чувствительный capability tier и более прикладной defensive product-контур, который мы разбирали в материале Claude Security: как Anthropic отделяет продукт для защитников от Mythos. Для читателя это важно потому, что рынок всё меньше похож на старую схему «одна модель для всех, а ограничения потом». Теперь модель, доступ и defensive use case становятся разными слоями одного запуска.
Почему эта история шире одной модели
Если всё же вернуть в кадр исходный пакет, становится видно, почему Mythos удобно читать как часть более общего сдвига. По данным официальной страницы Similarweb с топом мировых сайтов за март 2026 года, chatgpt.com получила около 5.5B визитов, а gemini.google.com — около 2.8B, причём у Gemini на этой же странице указан рост 261.44% год к году. Это не про безопасность напрямую, но про тот же рынок: distribution race больше не выглядит монополией одного интерфейса.
С другой стороны, растёт и физическая цена AI-гонки. Tom’s Hardware со ссылкой на U.S. Data Center Moratorium Tracker пишет, что в США уже 50 active bans на новые data centers в разных юрисдикциях, а общее число moratorium cases дошло до 78. Для нашей Mythos-статьи это не отдельный сюжет и не место для полного разворота. Но как supporting context он полезен: capability растёт не в вакууме. Одновременно растут и борьба за пользовательское внимание, и политическое сопротивление инфраструктуре, которая эту capability кормит.
Именно поэтому Mythos-first угол оказывается сильнее исходного «сборного пакета». Он держится на одном чистом news-intent, но при этом позволяет показать более широкий смысл: AI-гонка больше не сводится к релизам моделей. Она одновременно меняет eval science, режимы доступа, точки дистрибуции и пределы инфраструктурного роста.
Вывод
Claude Mythos в кибертестах AISI важна не тем, что Anthropic получила ещё один повод для громкого пресс-релиза. Важнее другое: институт показывает, что старые safety-evals перестают быть достаточной рамкой, когда модель начинает тянуть длинные offensive-цепочки. Отсюда и новый центр тяжести в разговоре о frontier AI. Меньше споров о том, «какая модель сильнее на одном бенчмарке», и больше споров о том, как такие capability вообще выпускать в мир.
Для Anthropic ответ уже виден: Mythos остаётся в gated preview, а defensive deployment идёт через Project Glasswing. Для рынка вывод шире и жёстче. Как только frontier-модель показывает такой уровень на cyber ranges, доступ, trusted use и ограничения перестают быть второстепенным приложением к продукту. Они становятся частью самого продукта.
Читайте также
- Anthropic Project Glasswing: почему Mythos держат в закрытом доступе
- AI-кибермодели: Mythos, GPT-5.4-Cyber и новая гонка защиты
- Claude Security: как Anthropic отделяет продукт для защитников от Mythos
Источники и дата проверки
Факты, даты и цифры в этом материале проверены 14 мая 2026 года. Для быстро меняющихся данных о web-трафике и инфраструктурных ограничениях дата проверки критична.
- UK AI Security Institute: Our evaluation of Claude Mythos Preview’s cyber capabilities
- Anthropic red team: Assessing Claude Mythos Preview’s cybersecurity capabilities
- Anthropic: Project Glasswing
- Similarweb: Top 100 Most Visited Websites Worldwide
- Tom’s Hardware: AI data center bans are rapidly multiplying across the US