DeepSeek против OpenAI: как китайская лаборатория изменила рынок ИИ
DeepSeek давит на OpenAI ценой API и открытыми весами V3/R1, но проигрывает в зрелости платформы и несёт отдельные риски для данных.

DeepSeek против OpenAI — уже не история про «китайский стартап, который внезапно всех удивил». К апрелю 2026 года это нормальная рыночная развилка: с одной стороны дорогая закрытая платформа OpenAI, с другой — DeepSeek с открытыми весами, дешёвым API и понятными рисками для данных.
По состоянию на 17 апреля 2026 года главный факт такой: в официальных документах DeepSeek API модели deepseek-chat и deepseek-reasoner указаны как DeepSeek-V3.2 с контекстом 128K. Цена для обеих: $0,28 за 1 млн входных токенов при cache miss, $0,028 при cache hit и $0,42 за 1 млн выходных токенов. Для сравнения, официальная страница OpenAI API pricing даёт для gpt-5.4 standard short-context $2,50 за вход и $15 за выход за 1 млн токенов.
Сравнивать эти числа напрямую можно только с оговоркой: цена API не равна качеству модели, доступности, безопасности, поддержке и удобству платформы. Но именно цена объясняет, почему DeepSeek стал проблемой для OpenAI. Он сбил ожидания рынка: сильная модель больше не обязательно должна продаваться как редкий и дорогой ресурс.
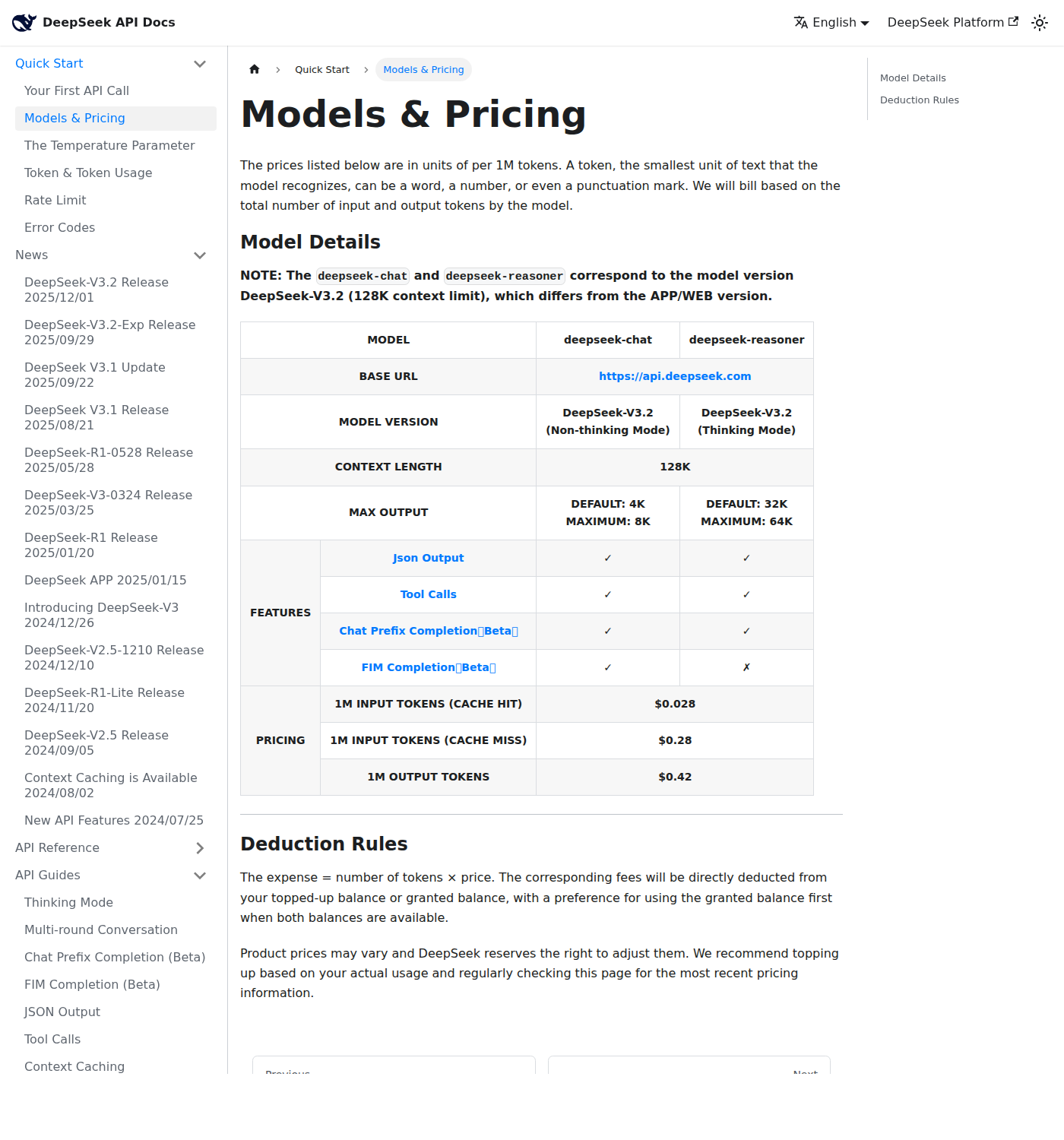
deepseek-chat и deepseek-reasoner, контекст 128K и цены за 1 млн токенов. Скриншот проверен 17 апреля 2026 года.Кто стоит за DeepSeek
DeepSeek основал Лян Вэньфэн, сооснователь китайского квантового хедж-фонда High-Flyer. AP пишет, что DeepSeek появился в 2023 году, а High-Flyer ещё до бума больших языковых моделей строил вычислительную инфраструктуру для машинного обучения в трейдинге.
Это важная деталь. DeepSeek вырос не как типичный потребительский чат-бот, а как исследовательская лаборатория при команде, которая уже работала с большими вычислениями и оптимизацией. Отсюда и его главный нерв: не «сделать ещё один ChatGPT», а выжать максимум из ограниченных ресурсов.
В прежней версии этой статьи история DeepSeek распадалась на несколько повторяющихся блоков про модели. Теперь правильнее смотреть на хронологию как на цепочку рыночных ударов.
| Событие | Почему важно | Источник |
|---|---|---|
| 2023: запуск DeepSeek | Лаборатория выросла из круга High-Flyer и сразу получила доступ к инженерной культуре, связанной с вычислениями. | AP |
| Декабрь 2024: DeepSeek-V3 | MoE-модель на 671 млрд параметров, из которых активны 37 млрд на токен, показала, что открытые модели могут приблизиться к закрытым лидерам. | DeepSeek-V3 Technical Report |
| Январь 2025: DeepSeek-R1 | R1 перенёс гонку reasoning-моделей в открытый сегмент и дал рынку альтернативу закрытым рассуждающим моделям. | DeepSeek-R1 paper, GitHub |
| Апрель 2026: API V3.2 | DeepSeek продолжает давить ценой: официальный API указывает $0,28 за входные и $0,42 за выходные токены за 1 млн токенов. | DeepSeek API Docs |
Почему V3 стал рыночным сигналом
В техническом отчёте DeepSeek-V3 компания описывает модель как Mixture-of-Experts: всего 671 млрд параметров, но на каждый токен активируются 37 млрд. Это не просто красивая архитектурная деталь. Такой подход снижает вычислительную нагрузку на инференсе и помогает держать цену ниже, чем у многих закрытых моделей.
Там же DeepSeek пишет, что полное обучение V3 потребовало 2,788 млн H800 GPU hours. Эту цифру часто пересказывали как «модель за $5,6 млн», но так писать без оговорки нельзя. В отчёте речь идёт о вычислительной стоимости конкретного обучающего прогона, а не обо всём бюджете компании, зарплатах, подготовке данных, неудачных экспериментах и инфраструктуре.
Даже с этой оговоркой эффект сильный. Рынок увидел, что высокий результат можно получить не только через путь OpenAI, Google или Anthropic: всё больше GPU, всё больше закрытых данных, всё больше капитальных затрат. DeepSeek показал другой путь: архитектурная экономия, открытые веса, агрессивная цена API.
Что изменил DeepSeek-R1
R1 важен не потому, что «обогнал всех». Важнее другое: он сделал reasoning-модель предметом открытого изучения. В репозитории DeepSeek-R1 указаны DeepSeek-R1-Zero и DeepSeek-R1 с 671 млрд параметров, 37 млрд активных параметров и контекстом 128K. Там же перечислены дистиллированные версии на базе Qwen и Llama, которые проще запускать локально.
Для OpenAI это неприятный тип конкуренции. Закрытую модель можно сравнивать по бенчмаркам и пользовательскому опыту, но нельзя так же свободно разобрать обучение, веса и поведение. DeepSeek сделал свои результаты частью инженерного разговора: их можно проверять, запускать, дообучать, критиковать и встраивать в свои системы.
Технические детали R1 лучше вынести в отдельный материал про модели рассуждения, o3 и DeepSeek-R1. Здесь достаточно главного: DeepSeek превратил reasoning из премиального закрытого слоя в направление, где у разработчиков появилась открытая точка отсчёта.
Где DeepSeek действительно давит на OpenAI
Первый удар — цена. По официальным API-прайсам на 17 апреля 2026 года, входной токен DeepSeek при cache miss дешевле gpt-5.4 standard short-context примерно в 8,9 раза, выходной токен — примерно в 35,7 раза. Это не значит, что DeepSeek лучше OpenAI. Это значит, что часть задач, где важен объём токенов, становится экономически проще вынести на DeepSeek.
Второй удар — открытые веса. DeepSeek-V3 и R1 можно обсуждать как инженерные артефакты, а не только как сервис. Это важно для компаний, которые хотят локальный запуск, аудит поведения, собственные дообучения или независимые тесты. Больше контекста по этому выбору есть в материале про открытые и проприетарные LLM.
Третий удар — психологический. До DeepSeek многие разговоры о frontier-моделях сводились к масштабу инвестиций: кто построит больше дата-центров, купит больше ускорителей и соберёт больше данных. После V3 и R1 вопрос стал точнее: где качество возникает из масштаба, а где из инженерной эффективности.
Где OpenAI остаётся сильнее
OpenAI конкурирует не только моделью. У компании есть ChatGPT, API, инструменты для разработчиков, корпоративные продукты, мультимодальные модели, Codex, экосистема интеграций и привычка рынка покупать готовую платформу. DeepSeek силён как модельная и API-альтернатива, но как продуктовая платформа он пока уже.
Для бизнеса это часто решает больше, чем цена токена. Если компании нужны поддержка, управляемый доступ сотрудников, интеграции, безопасность, договоры, журналирование и predictable roadmap, OpenAI выглядит понятнее. Если задача — дешёвый инференс, локальные эксперименты, open-weight стек или исследовательская работа, DeepSeek становится сильным кандидатом.
| Критерий | DeepSeek | OpenAI |
|---|---|---|
| API-цена, 1 млн токенов | $0,28 вход при cache miss, $0,42 выход для V3.2 API | gpt-5.4 standard short-context: $2,50 вход, $15 выход |
| Открытость | V3 и R1 доступны как open-weight модели с отдельной model license | Флагманские модели закрыты |
| Продуктовый слой | Чат, API, открытые веса, локальные и сторонние запуски | ChatGPT, API, корпоративный стек, инструменты для разработки и интеграции |
| Главный риск | Данные, юрисдикция, зрелость платформы, качество на чувствительных задачах | Цена, закрытость, зависимость от поставщика |
Что это значит для русскоязычного пользователя
Для обычного пользователя DeepSeek часто интересен как доступная альтернатива ChatGPT. Но этот интент лучше закрывает отдельный гайд DeepSeek на русском: как зайти, какую модель выбрать, как писать запросы, что делать с API и локальным запуском.
В этой статье важнее другое. Русскоязычным разработчикам и продуктовым командам DeepSeek даёт вариант для задач с большим расходом токенов: черновой анализ документов, классификация, извлечение данных, прототипы агентов, локальные тесты reasoning-подходов. Там, где нужны персональные данные, коммерческая тайна или регуляторная чистота, облачный DeepSeek надо включать только после отдельной оценки рисков.
Приватность и геополитика
DeepSeek нельзя оценивать только по цене и бенчмаркам. В политике конфиденциальности компания указывает, что собирает пользовательский ввод, загруженные файлы, обратную связь и историю чата, а также хранит собранную информацию на серверах в Китайской Народной Республике. В EEA/UK-разделе политика отдельно предупреждает, что персональные данные могут обрабатываться и храниться на серверах в КНР.
Отсюда простое правило: не отправляйте в облачный DeepSeek персональные данные, закрытый код, коммерческие документы, финансовую отчётность и клиентские данные, если у вас нет юридического и безопасностного основания так делать. Для чувствительных сценариев разумнее смотреть на локальный запуск открытых весов или поставщиков с подходящей юрисдикцией и договорной базой.
Политический блок тоже лучше держать в рамках фактов. DeepSeek — китайская компания. Это влияет на восприятие, регулирование и доверие корпоративных клиентов. Но из этого не следует автоматический вывод, что модель плохая или непригодная. Следует другой вывод: её нужно внедрять как внешний рискованный сервис, а не как нейтральную замену OpenAI.
Итог
DeepSeek изменил рынок не громким лозунгом, а инженерной и ценовой комбинацией. V3 показал, что сильная open-weight модель может быть дешёвой в инференсе. R1 сделал reasoning-модели открытой темой для разработчиков. API-прайсинг поставил давление на экономику закрытых платформ.
OpenAI при этом не проиграла. У неё остаётся более зрелый продуктовый слой, сильная корпоративная упаковка и шире набор инструментов. Но монополия на «самое серьёзное ИИ» закончилась. Теперь выбор выглядит практичнее: OpenAI для платформы и управляемого enterprise-стека, DeepSeek для дешёвого инференса, открытых экспериментов и задач, где контроль над весами важнее удобства готового продукта.
Источники
- DeepSeek API Docs: Models & Pricing, проверено 17 апреля 2026 года.
- OpenAI API Pricing, проверено 17 апреля 2026 года.
- DeepSeek-V3 Technical Report, arXiv.
- DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning, arXiv.
- deepseek-ai/DeepSeek-R1, GitHub.
- DeepSeek Privacy Policy, обновление от 14 февраля 2025 года.
- AP: Who is Liang Wenfeng, DeepSeek's founder?