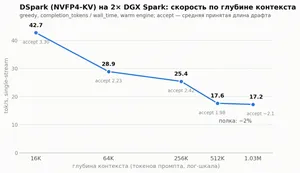
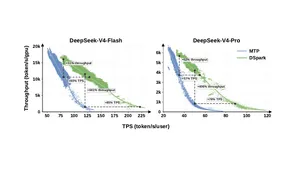
DeepSeek V4 меняет экономику frontier-моделей
DeepSeek V4 запускает 1M контекст, open weights и агрессивный split между cache miss и cache hit. Это не просто ещё один релиз модели, а попытка переписать экономику длинных агентных сессий.

DeepSeek V4 вышла 24 апреля 2026 года не как очередной раунд соревнования бенчмарков, а как атака на саму цену длинного контекста. DeepSeek одновременно добавила в API модели deepseek-v4-pro и deepseek-v4-flash, сохранила базовый URL, выдала обеим моделям контекст в 1 млн токенов и опубликовала open-weight релиз на Hugging Face. По состоянию на 24 апреля 2026 года это один из самых сильных сигналов года для рынка LLM: передовой класс всё чаще определяется не только качеством ответа, но и тем, сколько стоит держать модель в длинной агентной сессии.
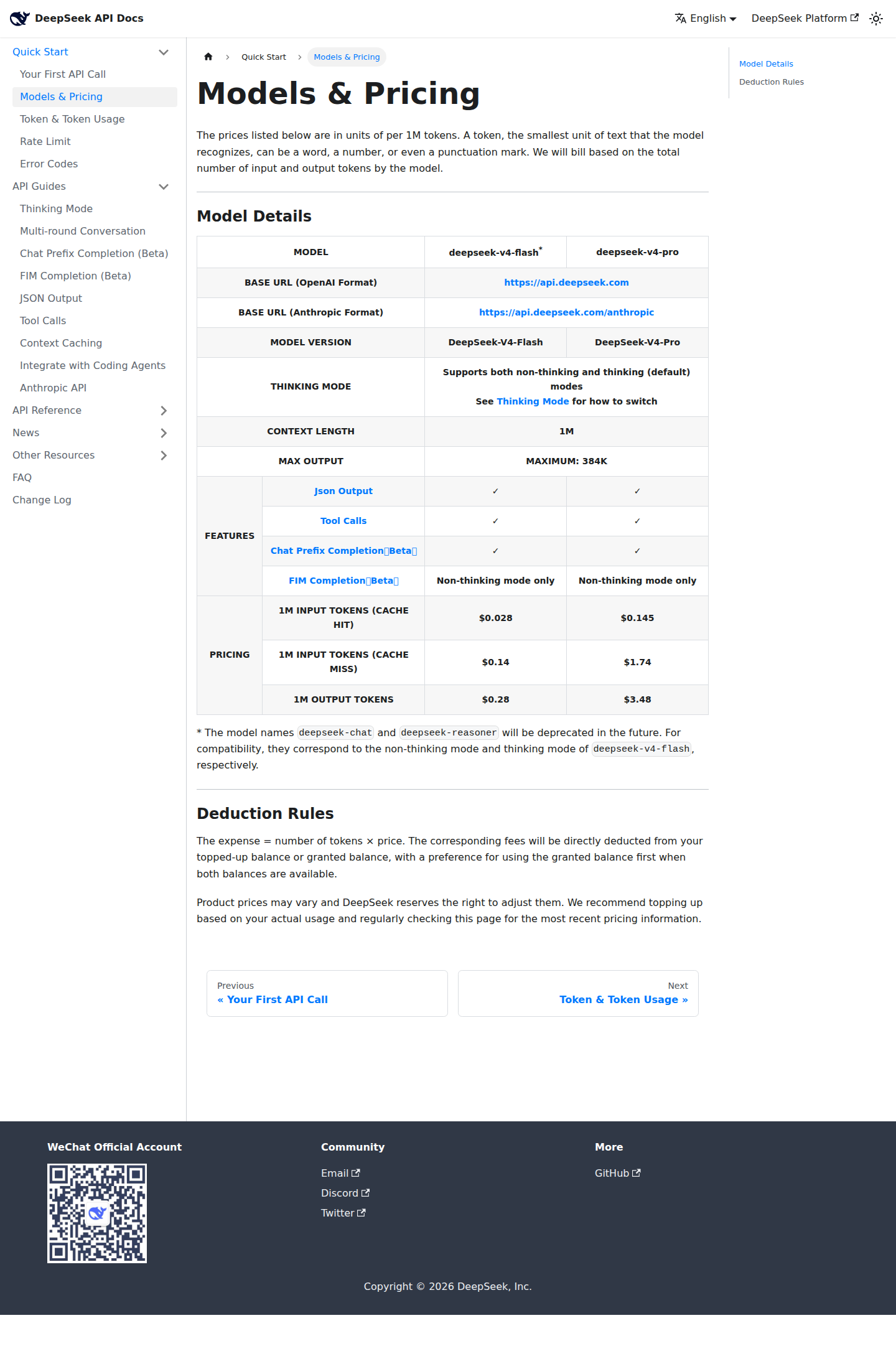
В официальном pricing DeepSeek указывает для deepseek-v4-pro $1,74 за 1 млн входных токенов при cache miss, $0,145 при cache hit и $3,48 за 1 млн выходных токенов. Для deepseek-v4-flash тариф ещё ниже: $0,14, $0,028 и $0,28 соответственно. На этом фоне OpenAI в анонсе GPT-5.5 обещает $5 за вход и $30 за выход при контексте 1 млн токенов, а Anthropic для Claude Opus 4.6 держит $5 за вход, $0,50 за cache hit и $25 за выход. Если коротко, DeepSeek V4 не просто вышла в сегмент миллионного контекста. Она пытается сделать его массовым.
Что именно DeepSeek выпустила 24 апреля
В changelog DeepSeek API за 24 апреля 2026 года зафиксировано, что API теперь поддерживает V4-Pro и V4-Flash через OpenAI Chat Completions и через Anthropic-совместимый интерфейс. Старые имена deepseek-chat и deepseek-reasoner ещё работают, но компания прямо пишет, что снимет их через три месяца, 24 июля 2026 года. Это важная деталь: DeepSeek не тестирует V4 в отдельной песочнице, а сразу переводит линейку на новый режим работы.
Модельная карточка на Hugging Face уточняет расклад по железу и масштабу. DeepSeek-V4-Pro заявлена как MoE-модель на 1,6 трлн параметров с 49 млрд активных параметров. DeepSeek-V4-Flash заметно компактнее по общему размеру, 284 млрд параметров и 13 млрд активных, но тоже рассчитана на контекст в 1 млн токенов. Обе модели поддерживают thinking и non-thinking режимы, tool calls, JSON output и FIM в non-thinking режиме. Это не две разные продуктовые линии, а два ценовых слоя одной архитектурной стратегии.
Отдельно стоит заметить формат релиза. DeepSeek не ограничилась API и чатом. Компания выложила open weights для Pro и Flash на Hugging Face под лицензией MIT. Для разработчиков и инфраструктурных команд это критично: у модели появляется не только токеновый прайс в облаке, но и альтернатива в виде собственного контура, кастомного инференса и маршрутизации между облачным API и своим развёртыванием.
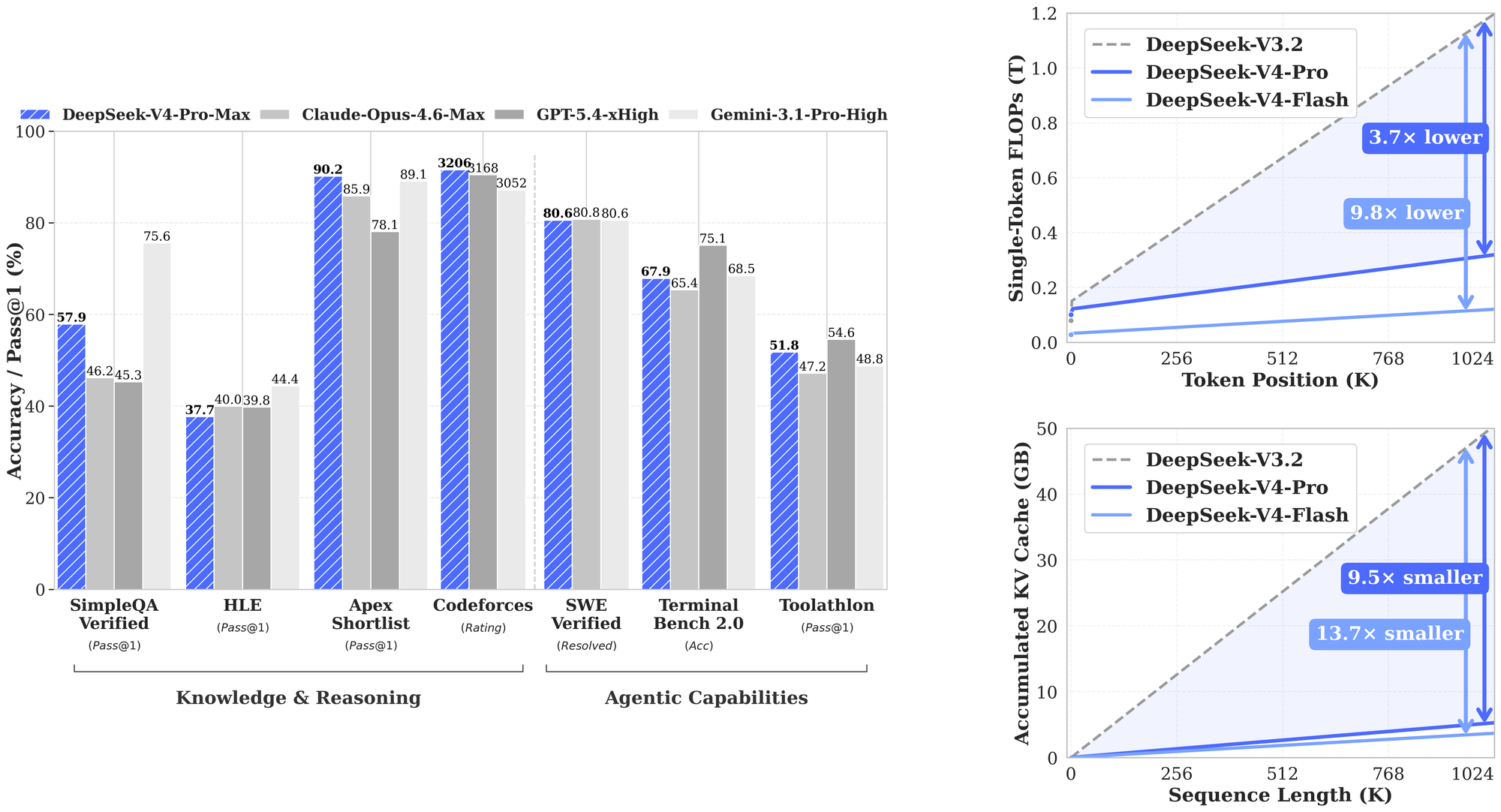
Почему экономика меняется на уровне архитектуры
Если смотреть только на прайс-лист, легко решить, что DeepSeek просто демпингует. Технический отчёт рисует другую картину. В нём компания пишет, что V4 использует гибрид внимания из Compressed Sparse Attention и Heavily Compressed Attention, добавляет Manifold-Constrained Hyper-Connections и оптимизатор Muon, а обе модели предварительно обучались более чем на 32 трлн токенов. Ключевой тезис не в красоте названий, а в цене операции внимания на длинной последовательности.
Самая важная цифра из отчёта такая: в сценарии контекста на 1 млн токенов DeepSeek-V4-Pro требует только 27% однотокенного inference FLOPs и 10% KV cache по сравнению с DeepSeek-V3.2. Для DeepSeek-V4-Flash цифры ещё агрессивнее: 10% FLOPs и 7% KV cache. Это уже объясняет, откуда берётся pricing. DeepSeek не только уменьшает цену в прайсе, но и заранее удешевляет саму физику длинного запроса.
В отчёте есть ещё одна деталь, которая особенно важна для агентных сценариев: DeepSeek описывает собственный on-disk KV cache и shared-prefix reuse для обслуживающего слоя. Иными словами, компания оптимизирует не только абстрактную модель, но и повторное использование больших общих префиксов, документов и системных инструкций. Для мира, где агенту надо раз за разом тащить в контекст кодовую базу, протоколы, policy-файлы и историю работы, это уже не академическая оптимизация, а основа итогового счёта.
Сколько теперь стоит миллион токенов
Ниже свёл цены из официальных источников по состоянию на 24 апреля 2026 года. В таблице важны не только абсолютные тарифы, но и то, какой механизм снижения счёта предлагает каждый вендор: у DeepSeek это жёсткий разрыв между cache miss и cache hit, у Anthropic тоже есть отдельная экономика кэша, а OpenAI в анонсе GPT-5.5 делает акцент на Batch и Flex как скидке на асинхронную работу.
| Модель | Контекст | Вход, $ / 1M | Выход, $ / 1M | Что снижает счёт |
|---|---|---|---|---|
| DeepSeek V4 Flash | 1M | 0.14 | 0.28 | Cache hit: 0.028 |
| DeepSeek V4 Pro | 1M | 1.74 | 3.48 | Cache hit: 0.145 |
| Claude Opus 4.6 | 1M | 5 | 25 | Cache hit: 0.50 |
| GPT-5.5 | 1M | 5 | 30 | Batch/Flex: 50% стандартной ставки |
Главный вывод таблицы простой. DeepSeek V4 Pro при стандартном входе почти в 2,9 раза дешевле Claude Opus 4.6 и GPT-5.5. По cache hit разрыв с Opus 4.6 составляет примерно 3,4 раза. По выходным токенам разница ещё жёстче: около 7,2 раза против Opus 4.6 и около 8,6 раза против GPT-5.5. Для V4-Flash разрыв ещё агрессивнее, но это уже не прямой лобовой обмен ударами с самым дорогим передовым сегментом, а скорее дешёвый слой для маршрутизации, фильтрации, чернового анализа и части агентных задач, где «достаточно хорошо» важнее максимального качества.
У GPT-5.5 в этой таблице есть важная оговорка: OpenAI в анонсе раскрыла стандартные цены и скидки Batch/Flex, но не вынесла отдельную ставку cached input в том виде, в каком это делает Anthropic или сама DeepSeek. Поэтому сравнение по повторному префиксу сегодня точнее всего выглядит именно между DeepSeek и Claude.
Если нужен отдельный разбор самой пары релизов и спора между open weights и закрытым API, посмотрите сравнение DeepSeek V4 и GPT-5.5: там мы разбираем уже не только цену токена, но и саму модель доступа к frontier-возможностям.
Где V4 действительно ломает юнит-экономику
Эффект сильнее всего чувствуется не на обычном чат-запросе, а на длинном повторяющемся префиксе. Если у вас один и тот же агент снова и снова тянет большой системный промпт, policy-файл, инструкции по безопасности, репозиторий и историю сессии, счёт определяется не только «сколько модель думает», но и «сколько раз вы платите за один и тот же контекст». Именно поэтому в SEO brief был выбран угол про cache economics, а не общий спор об открытых и закрытых моделях.
Для таких сценариев DeepSeek V4 выглядит не как ещё одна модель, а как попытка переписать базовую арифметику. Один и тот же миллион входных токенов у Pro стоит $1,74 при первом прогоне и $0,145 при cache hit. У Claude Opus 4.6 тот же повторный миллион стоит $0,50. У GPT-5.5 OpenAI на странице релиза не раскрывает отдельную ставку cached input, вместо этого предлагая скидки через Batch и Flex. Это разная философия. DeepSeek продаёт мысль «дорогой префикс должен резко дешеветь при повторении». OpenAI продаёт мысль «асинхронный режим должен стоить меньше». Anthropic занимает промежуточную позицию и явно показывает обе экономики: и standard, и cache hit.
Именно здесь V4 упирается в реальный рынок агентных нагрузок. В нашей статье про цены на ИИ-агенты для программирования уже было видно, что старая логика подписки ломается под длинными рабочими сессиями. Чем больше агент живёт в контексте, тем важнее становится не абстрактная «умность», а стоимость поддержания этой памяти. DeepSeek V4 прямо бьёт в эту точку.
Есть и второй слой экономики. Open weights под MIT не означают «дешёвый локальный запуск на ноутбуке». У V4 Pro всё ещё 1,6 трлн параметров и 49 млрд активных. Это серьёзная инфраструктурная игрушка, а не домашняя модель. Но наличие весов само по себе меняет переговорную позицию покупателя. Теперь у команды есть выбор: остаться в облачном API, строить собственный кластер, использовать V4 как внутренний слой длинного контекста или просто давить прайс у закрытых вендоров наличием рабочей альтернативы. Материал про открытые модели и закрытые API как раз про этот разворот, но V4 делает его гораздо менее теоретическим.
Что закрытые frontier API всё ещё делают лучше
Эта статья была бы слабой, если бы сводилась к крику «DeepSeek убила OpenAI». Этого в фактах нет. Более того, в собственном техническом отчёте DeepSeek прямо признаёт, что по reasoning-бенчмаркам V4 Pro Max немного уступает GPT-5.4 и Gemini 3.1 Pro и в среднем отстаёт от лучших закрытых моделей на несколько месяцев. То есть V4 меняет экономику быстрее, чем окончательно меняет иерархию качества.
Закрытые API по-прежнему сильны там, где важен не только токеновый прайс: управляемый сервис, зрелая экосистема инструментов, комплаенс, корпоративные интеграции, SLA и предсказуемый облачный контур. OpenAI и Anthropic продают не только модель, но и весь контур вокруг неё. DeepSeek пока делает куда более жёсткую ставку на то, что цена длинного контекста и open weights сами по себе перетянут часть рынка.
Это хорошо видно и в позиционировании бренда. У нас уже выходил материал о том, как DeepSeek изменила рынок ИИ, но V4 добавляет к той истории новую фазу. Раньше аргумент DeepSeek звучал как «китайская лаборатория может приблизиться к передовому качеству дешевле». Теперь аргумент звучит жёстче: «даже если закрытые модели пока сильнее в управляемом сервисном контуре, стоимость длинного агентного мышления больше не обязана быть такой высокой».
Что это значит для рынка в ближайшие месяцы
Первое последствие уже очевидно: у дорогих frontier API будет сложнее объяснять премию за длинный контекст только словами про качество. Когда DeepSeek V4 Pro предлагает 1 млн токенов и открытые веса по цене сильно ниже Opus 4.6 и GPT-5.5, рынок неизбежно начинает разбирать счёт по деталям: сколько стоит первый прогон, сколько стоит повторение, как работает кэш, сколько платим за output, что можно вынести в свой контур.
Второе последствие менее очевидно, но, возможно, важнее. DeepSeek V4 делает open-weight сегмент не просто «альтернативой под исследователей», а инструментом ценового давления на весь облачный рынок. Даже если большая компания не собирается поднимать V4 у себя, она получает новый ориентир для переговоров и архитектурных экспериментов. Это меняет рынок быстрее, чем ещё одна красивая таблица лидеров.
Третье последствие касается продуктового дизайна агентов. Когда модель дешевле держать на длинном контексте, разработчики могут позволить себе больше постоянной памяти, длинные policy-префиксы, более подробные истории вызовов инструментов и большие общие рабочие пространства. Иначе говоря, V4 влияет не только на чек, но и на то, какие агентные продукты вообще имеет смысл проектировать.
Итог
По состоянию на 24 апреля 2026 года DeepSeek V4 выглядит не как символическая победа open-weight лагеря, а как вполне конкретный пересчёт юнит-экономики. Компания соединяет 1M контекст, open weights, агрессивный split между cache miss и cache hit и архитектуру, которая реально сжимает стоимость внимания на длинной последовательности. Для рынка это важнее, чем очередной спор о том, кто занял первое место в одной таблице.
Закрытые frontier API никуда не исчезают. Но после V4 им придётся продавать не просто «лучшую модель», а лучшую совокупность качества, сервиса и инфраструктуры. А DeepSeek, похоже, решила бить именно туда, где этот пакет сложнее всего защищать: в стоимость длинной рабочей памяти.
Источники и дата проверки
Факты, цены, даты и технические характеристики проверены 24 апреля 2026 года по официальным источникам: DeepSeek API Docs, DeepSeek change log, модельной карточке и техническому отчёту DeepSeek V4 на Hugging Face, а также по официальным страницам OpenAI GPT-5.5 и Anthropic pricing для сопоставления цен закрытых frontier API.