DeepSeek: ценовая война API-моделей начинается с V4 Pro
DeepSeek закрепляет скидку 75% на V4 Pro как постоянный API-прайсинг. Разбираем, почему это давит на GPT-5.5, Claude Opus 4.7 и экономику AI-агентов.

Проверено 27 мая 2026 года. DeepSeek закрепляет скидку 75% на deepseek-v4-pro как новый постоянный API-прайсинг после 31 мая 2026 года. Это уже не обычная промоакция, а прямой удар по цене output-токенов: $0.87 за 1 млн выходных токенов против $30 у GPT-5.5 и $25 у Claude Opus 4.7.
Именно поэтому эта новость важна не как очередной пересказ цен DeepSeek V4. Речь про ценовую войну API-моделей: когда агентные системы, длинный контекст и tool-calling начинают сжигать миллионы токенов, стоимость ответа становится архитектурным ограничением. Качество модели всё ещё решает. Но теперь у дорогих frontier API появился конкурент, который давит не лозунгами, а строкой в счёте.
Фон по апрельскому релизу V4 и длинному контексту мы уже разбирали в материале о том, как DeepSeek V4 меняет экономику frontier-моделей. Здесь угол уже другой: что меняется после того, как временная скидка на V4 Pro превращается в официальный уровень цены.
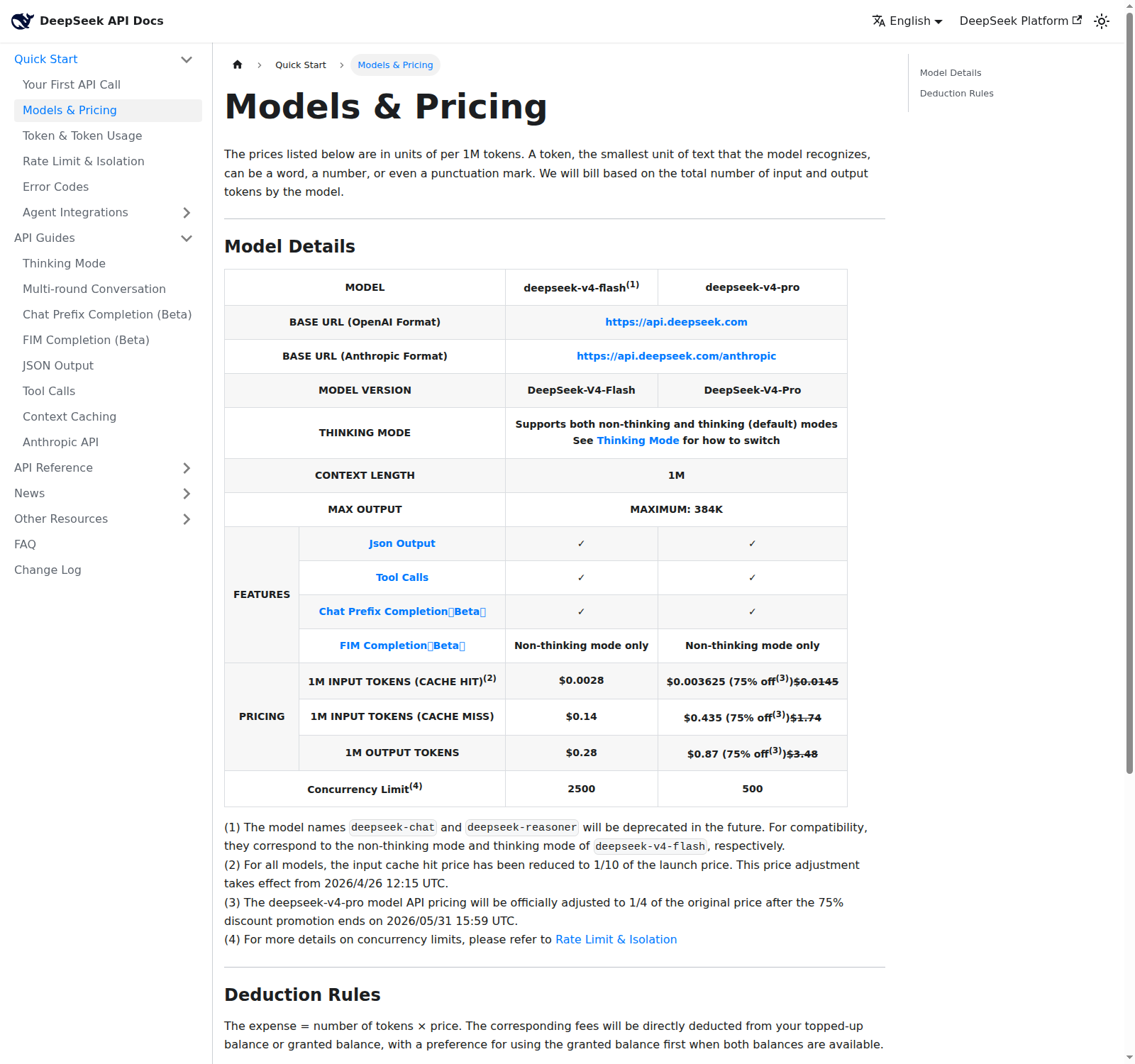
Что именно стало постоянным
На странице DeepSeek API Docs сейчас указано: deepseek-v4-pro стоит $0.003625 за 1 млн входных токенов при cache hit, $0.435 при cache miss и $0.87 за 1 млн выходных токенов. Рядом зачёркнуты старые уровни: $0.0145, $1.74 и $3.48. В примечании DeepSeek пишет, что после окончания промо 31 мая 2026 года в 15:59 UTC pricing V4 Pro будет официально скорректирован до четверти исходной цены.
V4 Flash дешевле и без этой акции: $0.0028 за cache hit, $0.14 за входной cache miss и $0.28 за output. В обеих моделях остаётся контекст 1 млн токенов, максимальный вывод 384 тыс. токенов, OpenAI-compatible endpoint, Anthropic-compatible endpoint, tool calls и JSON output. То есть DeepSeek снижает цену не на маленькую тестовую модель, а на рабочий API-контур V4.
| Модель | Input cache hit, $ / 1M | Input cache miss, $ / 1M | Output, $ / 1M | Контекст |
|---|---|---|---|---|
| DeepSeek V4 Pro | 0.003625 | 0.435 | 0.87 | 1M |
| DeepSeek V4 Flash | 0.0028 | 0.14 | 0.28 | 1M |
| GPT-5.5 | 0.50 | 5.00 | 30.00 | 1.05M |
| Claude Opus 4.7 | 0.50 | 5.00 | 25.00 | 1M |
По стандартному входу V4 Pro дешевле GPT-5.5 примерно в 11.5 раза. По output разрыв больше: около 34.5 раза против GPT-5.5 и 28.7 раза против Claude Opus 4.7. На cache hit сравнение становится совсем резким, но здесь важно не увлечься красивой арифметикой: итоговая стоимость задачи зависит от кэша, длины ответа, повторяемости префиксов, режима рассуждения и того, сколько попыток нужно модели для приемлемого результата.
Почему output-токены стали главным полем боя
У чат-бота output обычно выглядит как небольшая часть запроса. У агента всё иначе. Он планирует, вызывает инструменты, читает результаты, переписывает план, снова вызывает инструменты и генерирует длинные промежуточные ответы. В таких сценариях output может расти быстрее, чем полезный результат.
Это и есть причина, почему $0.87 за 1 млн выходных токенов звучит громче, чем скидка на вход. Если команда строит агента для кода, аналитики, фоновых проверок или пакетной обработки документов, она платит не только за «вопрос к модели». Она платит за весь цикл работы. В статье про tool-use tax у LLM-агентов мы уже показывали, как tool-calling может сам становиться источником лишних расходов. DeepSeek бьёт как раз туда.
Отдельно работает cache economics. Большие системные инструкции, policy-файлы, куски репозитория и длинная история сессии часто повторяются. Если провайдер резко удешевляет cache hit, архитекторы начинают иначе раскладывать контекст: что держать в постоянном префиксе, что вытаскивать через RAG, что отдавать дешёвой модели, а что отправлять в дорогой frontier API только на финальную проверку.
Где дешёвые токены не равны дешёвой задаче
Скидка DeepSeek не означает, что любая миграция сразу экономит 30 раз. Это слабая трактовка. У реальной задачи есть latency, качество tool use, стабильность JSON, безопасность данных, совместимость с SDK, ограничение concurrency и цена повторных прогонов после ошибок.
Есть и вопрос качества. The Decoder справедливо отмечает, что DeepSeek V4 всё ещё уступает GPT-5.5 и Opus 4.7 в сырой производительности на верхнем сегменте. Это совпадает с более широкой картиной: DeepSeek умеет давить цену, но не снимает с команды обязанность прогнать свои evals. Особенно если речь про код, финансовые документы, безопасность или автономные агенты с правом менять состояние системы.
Поэтому практичный вывод такой: V4 Pro и Flash надо рассматривать не как полную замену GPT-5.5 или Claude, а как новый ценовой слой. Flash может брать дешёвую фильтрацию, классификацию, черновой анализ и часть длинного контекста. V4 Pro — более тяжёлые reasoning и coding-задачи, где цена output уже критична. Закрытая модель остаётся там, где нужен максимальный запас качества, зрелый сервисный контур или корпоративные гарантии.
Что это меняет для OpenAI и Anthropic
OpenAI и Anthropic продают не только модель. Они продают платформу: инструменты, API, безопасность, поддержку, enterprise-контур, интеграции и предсказуемость. Это всё стоит денег. Но после такого шага DeepSeek им сложнее защищать высокий output-прайс одним аргументом «модель умнее».
Особенно болезненно это для сценариев, где качество «достаточно хорошее», а объём огромный: массовые проверки, агентные черновики, предварительное чтение репозиториев, обработка логов, тестовые прогоны, дешёвые ветки маршрутизации. В этих местах покупатель видит не абстрактный benchmark, а счёт за месяц.
Сравнение с GPT-5.5 здесь нужно держать аккуратно. У нас есть отдельный материал про DeepSeek V4 vs GPT-5.5, и новый текст не должен превращаться в повторный versus. Главное сейчас другое: DeepSeek перевела разговор из «кто умнее» в «сколько стоит держать агента работающим достаточно долго».
Что проверить перед миграцией
Разработчику перед переходом на DeepSeek API стоит проверить пять вещей на своей нагрузке, а не на чужой таблице цен.
- Качество на собственных evals: код, reasoning, tool calls, JSON output, длинные инструкции.
- Расход output-токенов на задачу, а не только цену за 1 млн токенов.
- Долю cache hit: без повторяемого префикса часть экономии просто не проявится.
- Latency и concurrency limit: у V4 Pro на официальной странице указан лимит 500, у Flash — 2500.
- Политику данных и юридические ограничения, особенно для корпоративных документов и пользовательских данных.
Если эти проверки проходят, цена DeepSeek становится сильным аргументом. Если нет, таблица с дешёвыми токенами останется красивой, но бесполезной.
Итог
По состоянию на 27 мая 2026 года DeepSeek делает самый интересный ход не в бенчмарках, а в прайсе. Компания фактически говорит рынку: V4 Pro не просто временно дешевле, эта цена станет новой нормой после 31 мая. Для API-моделей это неприятный сигнал.
Закрытые frontier API остаются сильнее как полный продуктовый контур. Но там, где агентные системы потребляют много output и много повторяемого контекста, DeepSeek теперь ставит вопрос жёстко: за что именно вы платите премию в 20-30 раз, и всегда ли она оправдана?
Источники и дата проверки
Факты, цены и даты проверены 27 мая 2026 года. Основные источники: официальная страница DeepSeek API Docs: Models & Pricing, релиз DeepSeek V4 Preview Release, модельная страница GPT-5.5 Model в OpenAI API Docs, официальная страница Claude API Pricing и новостной материал The Decoder от 23 мая 2026 года.