DeepSeek в расходах компаний США: что показал Ramp
Ramp увидел прямые платежи американских компаний DeepSeek. Разбираем, почему дешёвая LLM теперь конкурирует с enterprise-безопасностью.

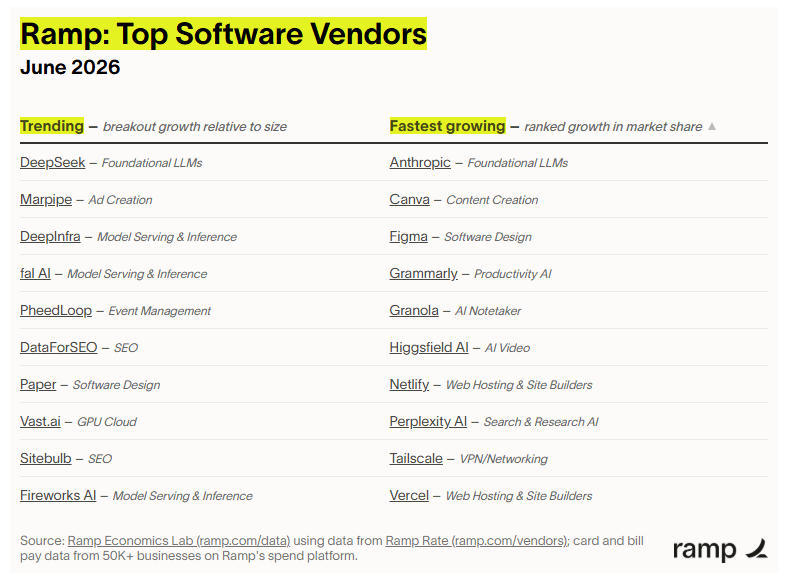
Проверено 7 июня 2026 года. Данные Ramp про DeepSeek не доказывают массовый исход американских компаний из OpenAI и Anthropic. Они показывают более тонкий сдвиг: DeepSeek появился в реальных расходах компаний США и возглавил колонку Trending в июньском списке Top Software Vendors on Ramp. Для рынка LLM это важный сигнал. Китайская модель перестаёт быть только темой бенчмарков и обсуждений на GitHub, а попадает в закупки, платежи и политику работы с данными.
Ramp опирается на данные Ramp Rate: карточные платежи и оплату счетов более чем 50 тысяч компаний на платформе. В июньской таблице 2026 года DeepSeek стоит первым в категории Trending, то есть показывает breakout growth относительно своего размера. В соседней колонке Fastest growing первое место заняла Anthropic. Такое соседство хорошо описывает текущий рынок: одни компании платят за зрелый enterprise-стек, другие ищут более дешёвый inference для задач, где frontier-модель не всегда нужна.
Главная деталь в отчёте Ramp не сама позиция DeepSeek, а формулировка про прямые платежи. По словам Ramp, в предыдущие месяцы американские компании чаще платили провайдерам вроде Fireworks AI, fal AI и DeepInfra, которые дают доступ к открытым моделям и hosted inference. Теперь Ramp видит direct payments to DeepSeek. Это означает другой уровень риска: деньги идут не только посреднику или инфраструктурной платформе, а самому китайскому AI-вендору.
Что именно показал Ramp
Метрика Ramp не равна доле рынка. Это не рейтинг выручки всех AI-компаний и не доказательство, что DeepSeek уже стал стандартом для бизнеса. Ramp смотрит на платежное поведение своей клиентской базы: какие поставщики появляются в расходах компаний, где растёт число новых покупателей и какие категории начинают пробиваться в закупки.
Поэтому вывод должен быть аккуратным: часть американских компаний начала платить DeepSeek напрямую или через связанные AI-платформы. Для редакции это сильнее обычного «интерес к DeepSeek растёт». Интерес можно измерять поисковыми запросами, скачиваниями модели или обсуждениями в соцсетях. Платёж в корпоративной системе означает, что кто-то уже провёл карту, оплатил счёт, получил внутреннее одобрение или хотя бы обошёл его.
Ramp отдельно пишет, что после всплеска интереса в январе использование DeepSeek в бизнесе снизилось: доля компаний, использующих сервис, упала примерно с 0,3% до 0,1%. Но в июне сервис всё равно вышел в Trending. Это выглядит как нишевое, но живое внедрение: не «все перешли на DeepSeek», а «у части команд экономия оказалась достаточно убедительной, чтобы занести DeepSeek в расходы».
Почему это не то же самое, что open weights
Вокруг DeepSeek легко смешиваются три разных сценария. Первый: команда скачивает открытые веса и поднимает модель у себя. Второй: команда использует inference-провайдера, который хостит разные модели и берёт на себя инфраструктуру. Третий: компания платит DeepSeek как hosted-сервису. Для бюджета все три варианта могут выглядеть как «дешевле OpenAI», но для юристов и службы безопасности это разные миры.
Self-hosted модель оставляет больше контроля у компании, но требует GPU, инженеров, обновлений, мониторинга и собственных evals. Inference-платформа снимает инфраструктурную боль, зато добавляет ещё одного обработчика данных. Прямой hosted DeepSeek проще всего включить, но он сильнее всего поднимает вопрос, какие данные уходят поставщику и где они хранятся.
Именно здесь новый материал отличается от нашего разбора про ценовую войну API-моделей DeepSeek. Там главный вопрос был в экономике токенов и давлении на OpenAI/Anthropic. Здесь вопрос шире: что происходит, когда дешёвая модель попадает в корпоративные закупки и начинает конкурировать не только качеством ответа, но и допуском к рабочим данным.
| Вариант использования | Где экономия | Риск данных | Что проверять перед оплатой |
|---|---|---|---|
| Прямой hosted DeepSeek | Быстрый доступ к дешёвой модели без собственной инфраструктуры. | Промпты, файлы и история чатов могут обрабатываться DeepSeek как поставщиком сервиса. | Data residency, обучение на данных, retention, DPA, запрет чувствительных классов данных. |
| Self-hosted open weights | Нет внешнего API-счёта за каждый запрос, можно оптимизировать под свои нагрузки. | Риск ниже при правильной изоляции, но появляются инфраструктурные и security-ошибки внутри компании. | Лицензию, обновления модели, логи, доступ к GPU, качество evals и работу с секретами. |
| Inference-платформы Fireworks, fal, DeepInfra | Быстрое подключение разных моделей и гибкая маршрутизация запросов. | Данные проходят через дополнительного провайдера, а иногда и через цепочку поставщиков. | SLA, регион обработки, логи, субпроцессоров, правила маршрутизации и отключение обучения на запросах. |
| Enterprise API OpenAI, Anthropic, Google | Экономия меньше, зато обычно понятнее договоры, админ-контроль и корпоративная поддержка. | Vendor lock-in, высокая стоимость и зависимость от правил закрытой платформы. | Договор, режимы без хранения запросов, роли доступа, аудит, лимиты и стоимость реальных сценариев. |
Почему компании всё равно смотрят на DeepSeek
Ответ короткий: счёт за LLM стал заметным. Когда пилот превращается в продукт, команда быстро начинает считать не только качество ответа, но и стоимость миллиона запросов, задержку, лимиты, нагрузку на поддержку и цену ошибки. В задачах вроде классификации, извлечения сущностей, черновых резюме или внутреннего поиска не всегда нужен самый дорогой frontier API.
DeepSeek хорошо попадает в эту боль. Даже если компания не готова отдавать ему клиентские данные, она может тестировать модель на синтетических наборах, внутренних низкорисковых задачах или через провайдера, который уже есть в списке одобренных поставщиков. Это объясняет, почему рядом с DeepSeek в таблице Ramp видны DeepInfra, fal AI и Fireworks AI: рынок ищет не одну «лучшую модель», а способ дешевле маршрутизировать разные задачи.
Для технических команд это нормальная инженерная логика. Один запрос можно отправить в дорогую reasoning-модель, другой в малую специализированную модель, третий в self-hosted inference. Мы подробно разбирали такую развилку в материале про открытые модели и закрытые API в 2026 году. Новые данные Ramp показывают, что эта развилка уже становится закупочной практикой.
Где начинается риск безопасности
DeepSeek не скрывает, что собирает пользовательский ввод. В privacy policy, обновлённой 10 февраля 2026 года, компания перечисляет text input, voice input, prompts, uploaded files, photos, feedback и chat history как данные, которые могут собираться при использовании сервиса. В том же документе указано, что персональные данные напрямую собираются, обрабатываются и хранятся в Китайской Народной Республике.
Для обычного пользователя это неприятная, но знакомая история про политику конфиденциальности. Для компании это другой уровень. В промптах легко оказываются внутренние документы, финансовые числа, клиентские тикеты, фрагменты кода, коммерческие условия и персональные данные. Даже если сотрудник хотел «быстро сократить текст», он может отправить наружу то, что не должно покидать корпоративный контур.

9to5Mac в своём разборе правильно выносит этот конфликт в заголовок: низкая стоимость выглядит привлекательно, но вопрос «что может пойти не так» нельзя откладывать на этап после внедрения. Если компания платит DeepSeek напрямую, ей нужно заранее решить, какие данные туда можно отправлять, кто это контролирует, как ведутся логи и что делать с уже отправленными запросами.
Что это меняет для OpenAI, Anthropic и Google
Данные Ramp не говорят, что OpenAI, Anthropic и Google проиграли. Скорее они показывают, что высокая цена frontier-моделей становится предметом переговоров. Если пользователь видит сопоставимый результат на дешёвой модели для простой задачи, корпоративному поставщику приходится объяснять, за что он берёт премию: качество на сложных задачах, безопасность, админ-панель, соответствие требованиям, поддержку, интеграции и стабильность.
Anthropic в той же таблице Ramp возглавила колонку Fastest growing. Это важная оговорка против простой истории «дешёвые китайские модели вытесняют дорогие американские». Рынок движется в обе стороны. Часть компаний готова платить за Claude или Gemini ради доверия, договоров, качества кодовых задач и корпоративных функций. Другая часть режет стоимость там, где риск ниже и модель достаточно хороша.
Для закупки AI это означает смену вопроса. Команда больше не выбирает один «корпоративный ChatGPT для всех». Она строит стек: где нужен закрытый enterprise API, где допустим self-hosted open weights, где можно взять managed inference, а где нужны запреты. В практическом смысле это продолжает тему, которую мы разбирали в гайде про LLM в бизнесе и выбор стека.
Как компаниям не превратить экономию в инцидент
Первое действие не техническое, а организационное: запретить серую оплату AI-инструментов личными картами и вынести LLM-поставщиков в обычный закупочный процесс. Если DeepSeek, DeepInfra или Fireworks появляются в расходах, это должно быть видно не через месяц в отчёте, а в момент запроса на оплату.
Второй шаг — классификация данных. Для публичных текстов, синтетических наборов и низкорисковых задач можно разрешить больше экспериментов. Для клиентских данных, кода закрытых продуктов, персональных данных, финансовых документов и стратегических планов нужен отдельный режим: одобренные поставщики, DPA, журналирование, ограничение регионов и запрет ручной вставки в потребительские интерфейсы.
Третий шаг — smart routing с правилами, а не хаотичный выбор модели каждым сотрудником. Запросы можно маршрутизировать по типу данных, критичности задачи, цене и требуемому качеству. Тогда DeepSeek или другая дешёвая модель не становятся запретным плодом и не превращаются в бесконтрольный канал утечки. Они занимают понятное место в архитектуре.
Вывод
DeepSeek в данных Ramp важен не как сенсация про «захват рынка США». Это ранний сигнал, что цена LLM стала достаточно болезненной, чтобы компании начали искать альтернативы прямо в расходах. Прямые платежи DeepSeek показывают: экономия уже конкурирует с привычной осторожностью enterprise-закупок.
Но дешёвая модель не отменяет базовые вопросы. Где обрабатываются данные? Используются ли промпты для обучения? Кто видит логи? Какие классы информации нельзя отправлять? Есть ли договор, который выдержит проверку security и legal? Без этих ответов экономия на inference легко превращается в риск, который стоит дороже токенов.
По состоянию на 7 июня 2026 года правильная формулировка такая: DeepSeek не вытеснил американских AI-вендоров, но уже заставил компании считать LLM не как модный эксперимент, а как строку бюджета. Следующий этап рынка — не одна модель для всех, а управляемая смесь frontier API, open weights, hosted inference и правил безопасности.
FAQ
Что такое DeepSeek Ramp?
Так в этой статье мы называем инфоповод: DeepSeek появился в июньских данных Ramp о расходах компаний и занял первое место в категории Trending среди software vendors.
Это значит, что американские компании массово перешли на DeepSeek?
Нет. Ramp показывает рост в своей клиентской базе, а не весь рынок США. Это сигнал о появлении прямых корпоративных платежей DeepSeek, но не доказательство массового перехода.
Чем опасен hosted DeepSeek для бизнеса?
Главный риск связан с данными. Если сотрудники отправляют в hosted-сервис промпты, файлы, код или внутренние документы, компания должна понимать, где эти данные обрабатываются, сколько хранятся и могут ли использоваться для обучения или улучшения сервиса.
Можно ли безопасно использовать DeepSeek в компании?
Да, если сценарий ограничен, данные классифицированы, поставщик прошёл проверку, а маршрутизация запросов контролируется. Самый безопасный вариант для чувствительных данных обычно ближе к self-hosted или корпоративным контурам, но всё зависит от задачи и требований компании.
Читайте также
- DeepSeek: ценовая война API-моделей начинается с V4 Pro
- Открытые модели vs закрытые API: как выбирать в 2026 году
- LLM в бизнесе в 2026: 4 сценария с быстрым запуском и как выбрать стек
Источники и проверка фактов
Факты, даты, изображения и формулировки проверены 7 июня 2026 года. Быстро меняющиеся данные по тарифам, политике обработки данных и корпоративным условиям нужно перепроверять перед публикацией.
- Ramp: Top SaaS Vendors on Ramp (June 2026), опубликовано 3 июня 2026 года, использовано для первичных данных Ramp, методологии расходов, позиции DeepSeek в Trending, Anthropic в Fastest growing и источника графика.
- The Decoder: Deepseek topped Ramp's trending software vendors in June 2026, опубликовано 7 июня 2026 года, использовано для пересказа отчёта Ramp, формулировки про direct payments и контекста AI-рынка.
- 9to5Mac: Security Bite: DeepSeek trending among US firms, опубликовано 4 июня 2026 года, использовано для security framing и изображения приложения DeepSeek на iPhone.
- DeepSeek Privacy Policy, обновлено 10 февраля 2026 года, использовано для сведений о собираемых пользовательских данных, обучении/улучшении технологий, праве opt-out и хранении персональных данных в КНР.