Tool-use tax у LLM-агентов: где tool-calling начинает вредить
Tool-use tax у LLM-агентов показывает, как protocol overhead и semantic distractors могут сделать agentic loop слабее обычного CoT.

По состоянию на 5 мая 2026 года разговор про AI-агентов всё чаще строится вокруг простого рефлекса: если модели дать больше tools, она станет и умнее, и надёжнее. Свежий препринт Are Tools All We Need? Unveiling the Tool-Use Tax in LLM Agents, отправленный на arXiv 30 апреля 2026 года, бьёт ровно по этому рефлексу. Его тезис неприятен, но полезен: в условиях семантического шума tool-calling может ухудшать результат даже тогда, когда сами инструменты в принципе полезны.
Авторы называют эту просадку tool-use tax — налогом на качество, который вносит не задача и не отсутствие знаний у модели, а сам протокол вызова инструментов. И это важное смещение. Спор уже не о том, умеет ли агент вызвать калькулятор, поиск или API. Спор о другом: окупает ли сама механика tool-calling те потери, которые она добавляет в рассуждение.
Для рынка это не академическая придирка. Мы уже видим, как агентные продукты упираются в стоимость лишних действий и tool-overuse в продакшене, а команды заново собирают слой интеграции модели с инструментами через MCP и похожие протоколы. В этом же экономическом слое лежит и новая модель Anthropic: компания уже отделяет Agent SDK от подписки Claude и вводит отдельный кредит. Если авторы правы, то часть проблемы сидит не в конкретной модели, а в том, как мы вообще строим агентную обвязку.
Что paper называет tool-use tax
Сильная сторона работы в том, что авторы не ограничились лозунгом «tools иногда вредят». Они разложили путь агента на отдельные слои и попытались измерить, где именно начинается просадка. Для этого препринт вводит Factorized Intervention Framework — цепочку из нескольких режимов: от обычного native CoT без инструментов до полного агентного цикла с function calling и реальным исполнением tools.
Логика у схемы простая. Сначала модель решает задачу без tools. Затем ей меняют только форму промпта под function calling. После этого добавляют сам протокол агентного вызова, но без полезного результата инструмента. И только в последнем режиме дают реальное выполнение tools. Так авторы отделяют три вещи, которые обычно смешивают в одну корзину: цену нового формата промпта, накладные расходы протокола и реальную пользу от инструмента.
Это и есть ключевой сдвиг статьи. Проблема оказывается не в духе «модель не умеет считать» или «поиск вернул не тот документ». Авторы прямо показывают, что часть потерь появляется ещё до того, как инструмент успел что-то полезное сделать. То есть tool-calling может повредить траектории уже самим фактом, что модель вошла в другой режим работы: начала выбирать, когда остановиться, как оформить вызов, как встроить результат назад в рассуждение.
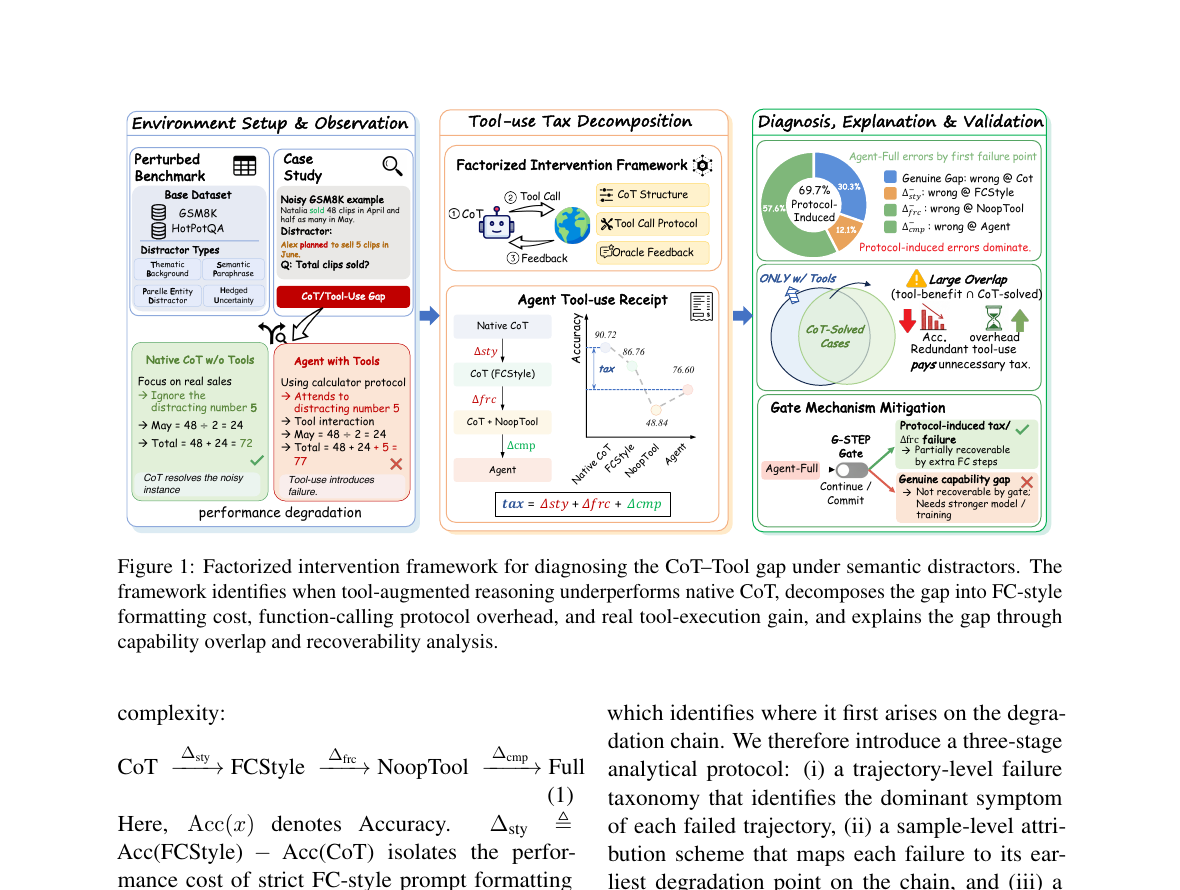
В этом смысле термин tool-use tax удачен. Он не говорит, что инструменты бесполезны. Он говорит, что у них есть собственная цена, и эту цену надо считать отдельно. Для инженерных команд это почти бухгалтерская мысль: вызов инструмента — не бесплатное улучшение reasoning, а событие с собственным бюджетом ошибок.
Где tools начали проигрывать собственному CoT
Авторы проверяют гипотезу на двух бенчмарках с семантическими отвлекающими фрагментами: математическом GSM8K и multi-hop QA на HotPotQA. Картина получается очень несимметричной.
| Задача | Модель | NoTool-CoT | Agent-Full | Разрыв |
|---|---|---|---|---|
| GSM8K | Qwen3-4B | 85,44% | 52,08% | -33,36 п.п. |
| GSM8K | Qwen3-32B | 91,40% | 75,76% | -15,64 п.п. |
| GSM8K | GPT-4.1-mini | 90,72% | 76,60% | -14,12 п.п. |
| HotPotQA | Qwen3-4B | 74,79% | 72,32% | -2,47 п.п. |
| HotPotQA | Qwen3-32B | 84,15% | 83,03% | -1,12 п.п. |
| HotPotQA | GPT-4.1-mini | 87,06% | 86,44% | -0,62 п.п. |
На математике просадка большая и системная. На Qwen3-4B полный agentic loop проигрывает обычному CoT больше 33 процентных пунктов. На Qwen3-32B и GPT-4.1-mini разрыв меньше, но всё равно двузначный. На HotPotQA картина заметно мягче: просадки остаются, но это уже единицы процентов, а не обвал.
Именно здесь статья становится по-настоящему полезной. Она показывает, что не все задачи одинаково чувствительны к tool-use tax. В retrieval-подобном режиме модель ещё может пережить лишний вызов, чуть шумный документ или неидеальное доказательство. В последовательной вычислительной задаче одно лишнее действие ломает всю цепочку. Если агент ошибся в моменте остановки, в промежуточном вычислении или в выборе следующего шага, правильный final answer уже неоткуда взяться.
Авторы отдельно проверяют, где узкое место сильнее: в качестве добытых evidence или в вычислительной цепочке. На Qwen3-4B разница показательная. В режиме Agent-Full на GSM8K модель даёт 52,08% accuracy. Если подменить только вычислительную часть oracle-ответом, показатель прыгает до 89,20%. Если дать чистое evidence, но оставить остальную механику прежней, получается лишь 52,48%. Это очень жёсткий сигнал: проблема не в том, что агент не нашёл факты, а в том, что он портит собственную вычислительную траекторию.
Почему tools не дают чистый выигрыш
Самый сильный кусок работы — не таблица с итоговыми цифрами, а объяснение, почему вообще возникает такой парадокс. Авторы выделяют два слоя.
Первый слой — protocol-induced errors. На GSM8K большая часть ошибок Agent-Full появляется не потому, что модель «вообще не умеет решить задачу», а потому что сбой случается уже после входа в tool-calling loop. Для Qwen3-4B работа относит к таким ошибкам 79,4% провалов Agent-Full, для Qwen3-32B — 75,8%, для GPT-4.1-mini — 69,7%. Причём главным источником оказывается именно protocol overhead: 58,7%, 45,5% и 44,6% всех ошибок соответственно.
Переводя на нормальный русский: агент может испортить задачу не отсутствием интеллекта, а тем, что начал жить по слишком сложному ритуалу. Нужно оформить tool call, не потерять контекст, верно интерпретировать промежуточный результат, решить, нужен ли ещё один шаг, и не сорваться в premature termination или в лишнюю итерацию. Каждый такой переход добавляет ещё одну точку отказа.
Второй слой авторы называют Capability Overlap Principle. Он бьёт по самой интуиции «раз инструмент помог, значит он был нужен». На GSM8K доля tool-benefited cases, которые одновременно решались и обычным CoT, составляет 89,6% у Qwen3-4B, 94,0% у Qwen3-32B и 95,4% у GPT-4.1-mini. То есть почти весь измеримый выигрыш от инструмента оказывается избыточным: модель и так могла дойти до ответа без внешнего действия.
Отсюда получается неприятная, но очень трезвая арифметика. Да, реальный tool execution даёт положительный computation gain. Но если этот выигрыш в основном дублирует native reasoning, а protocol overhead параллельно ломает часть и без того решаемых примеров, суммарный баланс уходит в минус. Инструмент что-то добавил, но цена входа в инструментальный режим оказалась выше.
Это хорошо рифмуется с тем, что мы уже видели в материале про tokenmaxxing и tool-overuse у AI-агентов. Там основная проблема выглядела как лишние вызовы и плохой порядок действий. Здесь работа даёт чуть более фундаментальную формулу: иногда вред приносит не лишний конкретный tool call, а сам слой оркестрации, который превращает решаемую задачу в хрупкую многоходовку.
Что даёт G-STEP и почему этого мало
Авторы не останавливаются на диагнозе и пробуют лечение. Их intervention называется G-STEP — лёгкий inference-time gate, который включается в момент, когда модель собирается завершить tool loop и выдать финальный ответ. Задача gate простая: решить, стоит ли сейчас коммитить ответ или лучше сделать ещё один шаг и продолжить взаимодействие с инструментом.
На слабом математическом сетапе это работает заметно. В GSM8K-4B G-STEP поднимает accuracy с 50,64% до 69,12%, а версия с critic-style prompts — до 74,88%. Это закрывает 75,75% разрыва между Agent-Full и CoT. На GSM8K-32B эффект есть, но намного слабее: 73,28% превращаются в 77,04%, а потом лишь в 77,44% с critic-pass.
А вот на HotPotQA-32B магии уже нет. Там Agent-Full даёт 83,02%, G-STEP — 82,90%, а critic-версия опускается до 82,10%. То есть gate помогает только там, где основная проблема действительно в протоколе. Когда bottleneck сидит в genuine capability gap, дополнительный контроллер поверх tool loop не спасает.
И это, пожалуй, самый зрелый вывод работы. Она не продаёт ещё одну обвязку как универсальное решение. Наоборот, она показывает предел самой идеи: если агент страдает от плохой внутренней reasoning capacity или не умеет работать с задачей по существу, сверху можно навесить сколько угодно guard layer, но чудо не случится.
Почему из этого не следует, что tools не нужны
Самая дешёвая интерпретация этой работы звучала бы так: «инструменты переоценены, давайте вернёмся к чистому CoT». Это был бы плохой вывод. Корректнее сказать иначе: tools окупаются не везде и не одинаково. Особенно хорошо это видно на фоне свежей работы ARuleCon: Agentic Security Rule Conversion.
ARuleCon решает очень узкую, но очень практичную задачу: перенос правил между разными SIEM-платформами. В этом домене агентный слой не заменяет уже имеющееся у модели знание, а даёт доступ к тому, чего у неё обычно нет: к официальной vendor-документации, к синтаксическим ограничениям каждой платформы и к исполнимой проверке эквивалентности результата.
В работе это измерено вполне приземлённо. Авторы прогоняют 1 492 пары конверсии между пятью SIEM-системами и пишут, что ARuleCon в среднем опережает базовые LLM-модели примерно на 15% по similarity alignment. При этом execution success для готовых target rules во многих направлениях держится выше 90%, а для некоторых конверсий вокруг Splunk и Google Chronicle доходит почти до 100%.

Разница между двумя работами принципиальная. В работе про tool-use tax инструмент часто дублирует уже доступную модели способность и лишь усложняет маршрут до ответа. В ARuleCon слой инструментов даёт то, чего у модели без него просто нет: authoritative docs, vendor-specific grammar и executable consistency check. Там агентная обвязка работает не как модная схема, а как доменный рабочий процесс.
Это и есть полезная граница для рынка. Инструменты оправданы там, где они дают комплементарную capability, а не косметическое удлинение траектории. Когда без внешнего контекста, внешней среды или исполнимой проверки задача по-честному не решается, слой инструментов имеет смысл. Когда модель и так знает ответ, но мы заставляем её пройти длинный протокол ради красивой архитектуры, налог почти неизбежен.
На более широком уровне это продолжает тезис из статьи про оркестрацию AI-агентов и новый LAMP. Рынок слишком легко принимает сам факт сложной обвязки за признак зрелости. Но зрелость создаёт не схема из блоков и стрелок, а способность пройти задачу до результата без лишних переходов и с понятной ценой ошибки.
Что это меняет для команд, которые строят агентов
Если смотреть на оба paper вместе, практический вывод получается не романтический, а инженерный.
- Считайте вызов инструмента отдельным событием с ценой. У него есть не только token cost, но и protocol cost: форматирование, лишние ходы, ошибки остановки, интеграция результата обратно в reasoning.
- Делайте no-tool валидным выбором. Если агент не умеет честно решить, что внешний инструмент здесь не нужен, он будет плодить лишние действия просто потому, что у него есть такая возможность.
- Отделяйте задачи, где слой инструментов добавляет новую способность, от задач, где он лишь дублирует native CoT. В первом случае инструменты дают преимущество. Во втором — часто только добавляют tax.
- Логируйте не только final accuracy, но и стадию, на которой началась деградация. Работа про tool-use tax полезна именно этим: она разводит styling cost, protocol overhead и real computation gain, а не сваливает всё в одну метрику.
- Если workflow узкий и доменно жёсткий, как в ARuleCon, подпирать агента официальной документацией и исполнимой проверкой важнее, чем давать ему ещё один универсальный tool.
Иначе говоря, главный вопрос для 2026 года звучит уже не так: «сколько tools подключить к агенту?» Правильный вопрос другой: «какую новую способность даёт этот инструмент, и окупает ли она протокол, который мы вокруг него строим?»
Вывод
Tool-use tax у LLM-агентов — это полезный термин не потому, что красиво звучит, а потому что заставляет считать реальную цену tool-calling. Препринт от 30 апреля 2026 года показывает: под семантическим шумом полный agentic loop может проигрывать обычному CoT не вопреки, а из-за собственной механики. В математических и многошаговых задачах этот налог особенно заметен.
Но вывод «tools не нужны» был бы слишком ленивым. Более точная формула такая: tools хороши там, где они добавляют модели внешнюю capability, которую нельзя честно заменить её внутренним reasoning. Когда инструментальный слой просто оборачивает уже решаемую задачу в лишний протокол, он начинает брать налог — на качество, стоимость и сложность системы.
Источники и дата проверки
Факты и цифры в материале проверены 5 мая 2026 года. Быстро меняющиеся детали по моделям, agent stacks и соседним продуктам могут измениться после этой даты.
- arXiv: Are Tools All We Need? Unveiling the Tool-Use Tax in LLM Agents, submitted on 30 April 2026.
- PDF paper: Are Tools All We Need? Unveiling the Tool-Use Tax in LLM Agents.
- arXiv: ARuleCon: Agentic Security Rule Conversion, arXiv version dated 8 April 2026.
- PDF paper: ARuleCon: Agentic Security Rule Conversion.



