Оркестрация AI-агентов: почему рынок снова строит новый LAMP
Оркестрация AI-агентов стала новым модным стеком, но устойчивое преимущество создают не связки фреймворков, а workflow competence и воспроизводимость.
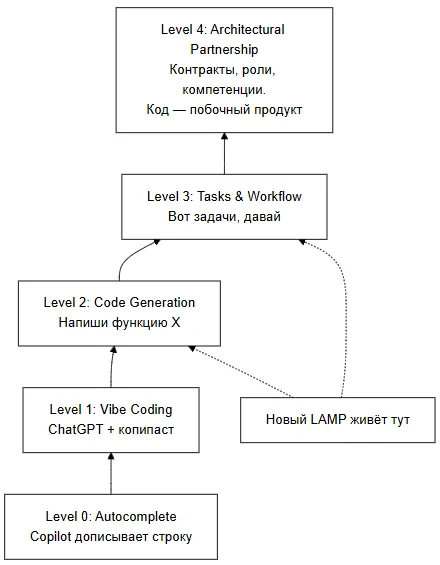
Оркестрация AI-агентов по состоянию на 27 апреля 2026 года стала тем слоем, который рынок пытается продать как новую базовую технологию. В тот же день, когда на Хабре вышла колонка «Новый LAMP, или почему ваш Agent Pipeline — это Apache в 2006 году», на arXiv уже лежали свежие papers, которые неожиданно поддерживают тот же тезис с другой стороны. Главный вопрос теперь не в том, умеет ли модель вызвать инструмент. Главный вопрос в том, может ли система удержать длинный рабочий процесс, доменный контекст и проверяемый результат.
Это важное смещение. LangChain, RAG, векторные базы, tool calling и наблюдаемость никуда не исчезают. Но сами по себе они слишком часто работают как набор коробок на схеме, а не как причина, почему продукт или команда будут делать работу лучше. Если переводить на язык двухтысячных, рынок снова увлёкся стеком раньше, чем договорился, какую именно задачу этот стек должен решать.
Почему метафора нового LAMP попала в нерв
В колонке на Хабре Сергей Васильев не спорит с тем, что оркестрация нужна. Его тезис жёстче: индустрия снова учит стек раньше, чем учит решать задачу. В 2006 году эту роль играл LAMP. Сегодня на том же месте оказываются связки вроде LangChain, RAG, vector DB, embeddings и маршрутизации вызовов. Они создают ощущение инженерной зрелости уже самим фактом присутствия в архитектуре.
Проблема в том, что стек почти всегда решает инфраструктурную задачу. Он отвечает на вопросы «как подать контекст», «как дернуть инструмент», «как проложить цепочку вызовов», «как собрать логи». Всё это важно. Но пользователь платит не за наличие orchestration layer. Он платит за то, что задача проходит путь от входа до результата без потери смысла, без лишних шагов и без скрытой ручной работы.
Поэтому метафора с LAMP работает не как шутка про моду, а как инженерное предупреждение. LAMP когда-то был хорошим фундаментом, но плохим ответом на вопрос об архитектуре. С оркестрацией AI-агентов происходит то же самое. Можно построить красивый agent pipeline и всё равно не получить ни устойчивости, ни накопления знания, ни нормальной воспроизводимости.
Оркестрация сама по себе не создаёт преимущества
У хорошей оркестрации есть понятная польза. Она снижает хаос в вызовах модели, помогает развести роли, выстраивает шаги, упрощает трассировку и делает долгие задачи менее хрупкими. Но на этом список не заканчивается. Как только команда пытается вывести агентную систему из демо в рабочий контур, выясняется, что главные провалы лежат не в маршрутизации как таковой.
Первый провал — проектный контекст. Агент может уметь искать по коду, но всё равно не понимать, почему команда в этом модуле не использует ORM, почему одна ветка заморожена до релиза или почему конкретный API нельзя вызывать без дополнительной проверки. Второй провал — контракты инструментов. Наличие tool calling ещё не означает, что агент понимает границы действия, входные форматы и цену ошибки. Мы уже разбирали, почему стандарты вроде MCP важны как интерфейсный слой, но сам интерфейс не заменяет дисциплину его использования.
Третий провал — организация знания. Если проектный контекст живёт в обрывках чатов, заметках отдельных инженеров и полуактуальных документах, никакой orchestrator не превратит это в надёжную систему. Поэтому для агентных команд всё важнее не только выбрать инструменты, но и держать проект в состоянии, где агенту вообще есть с чем работать. Про это мы подробно писали в материале как настроить проект для AI-агентов: без нормального слоя контекста даже сильная модель остаётся умным новичком, которого каждый раз приходится вводить в курс дела.
Если сжать мысль до одного предложения, получится неприятный, но полезный вывод. Оркестрация AI-агентов нужна, но рынок очень часто путает наличие диспетчера со зрелостью всей системы.
MolClaw показал, где начинается workflow competence
Свежий paper MolClaw: An Autonomous Agent with Hierarchical Skills for Drug Molecule Evaluation, Screening, and Optimization был подан на arXiv 2 апреля 2026 года. Это хороший пример того, как разговор про агенты перестаёт быть разговором про красивую обвязку и становится разговором про компетентность рабочего процесса. Авторы описывают не просто ещё одного агента для науки, а систему, которая объединяет более 30 специализированных ресурсов через трёхуровневую архитектуру навыков: tool-level, workflow-level и discipline-level. Всего в этой иерархии 70 skills.
Ключевая деталь не в самом числе навыков. Важнее, что MolClaw упаковывает доменное знание в повторяемые рабочие цепочки с проверками и рефлексией, а не ограничивается плоским вызовом инструментов. Для оценки авторы вводят MolBench — набор задач для screening, optimization и end-to-end discovery, где агенту нужно пройти цепочки длиной от 8 до 50+ последовательных tool calls. Это уже не игрушечный тест на один вызов API. Это стресс-тест на удержание состояния, последовательности и научной логики.
Дальше начинается самое интересное. В abstract авторы прямо пишут, что выигрыш MolClaw концентрируется на задачах, где нужны структурированные workflow, и исчезает там, где хватает ad hoc scripting. То есть преимущество создаёт не сам факт, что агент умеет дёргать десятки инструментов, а способность собирать их в устойчивую процедуру. Именно поэтому paper так хорошо ложится в наш разговор про новый LAMP. Bottleneck смещается от выбора фреймворка к качеству рабочих процессов.
Для разработчиков здесь есть практический урок. Если ваша агентная система не умеет аккумулировать domain knowledge в повторяемые шаги, то сложный стек не делает её зрелой. Он только делает её сложной. MolClaw интересен именно потому, что показывает обратное: доменная ценность появляется тогда, когда orchestration встроена в научный workflow, а не висит поверх него как универсальный middleware.
Reproducibility важнее красивого scaffold
Второй важный paper, Read the Paper, Write the Code: Agentic Reproduction of Social-Science Results, был подан на arXiv 23 апреля 2026 года. Это уже более жёсткая проверка зрелости агентных систем. Авторы спрашивают не «может ли агент помочь учёному», а «может ли агент воспроизвести эмпирические результаты по описанию метода и исходным данным, не имея доступа к оригинальному коду, результатам и даже самому paper в ходе исполнения».
Конструкция эксперимента показательна сама по себе. Система извлекает структурированное описание методологии, затем запускает переimplementation под строгой информационной изоляцией и сравнивает результат на уровне отдельных ячеек таблиц и выходов. Авторы оценивают четыре agent scaffolds и четыре LLM на 48 papers с human-verified reproducibility. Их вывод одновременно оптимистичен и отрезвляет: агенты часто могут восстановить опубликованные результаты, но разброс между моделями, scaffold-ами и самими papers остаётся большим.
Самая полезная часть abstract не в словах про успех, а в словах про причины неудач. Root cause analysis показывает, что проблемы возникают не только из-за ошибок агента, но и из-за недоопределённости самих научных текстов. И вот это уже сильный аргумент против наивной веры в «правильный стек». Даже хороший agent pipeline не спасает, если входная методология расплывчата, промежуточные шаги плохо специфицированы, а воспроизводимость держится на молчаливых допущениях автора.
Для рынка AI-агентов это неприятный, но здоровый сигнал. Красивый scaffold может улучшить логистику шагов. Он не заменяет ясности спецификации. А значит, настоящая зрелость системы измеряется не количеством ролей и не длиной prompt chain, а способностью довести задачу до проверяемого результата в условиях, где нельзя подглядывать в ответ.
Что командам строить вместо охоты за ещё одним стеком
Если смотреть на Habr-метафору и два arXiv papers вместе, вывод получается довольно приземлённый. Командам не нужно отказываться от оркестрации. Им нужно перестать считать её конечной целью. Оркестрация — это слой координации. Ценность возникает уровнем выше: в проектном контексте, в контрактах инструментов, в повторяемых workflow и в воспроизводимости решений.
Отсюда вытекает и более практический список. Во-первых, хранить знания проекта так, чтобы агент мог опираться на них не как на шумный архив, а как на рабочий контекст. Во-вторых, разводить безопасные и опасные инструменты по чётким контрактам. В-третьих, фиксировать трассу выполнения и не считать, что «модель сама разберётся». В-четвёртых, оставлять человека не в роли кнопки approve для красоты, а в роли реального владельца границ системы.
Мы уже видели близкий сдвиг в материале про AI-агентов в продакшене, tokenmaxxing и tool-overuse. Там основной вывод был в том, что стоимость и ошибки растут не от недостатка интеллекта, а от плохого порядка действий. Здесь картина та же, только глубже. Рынок может сколько угодно продавать новый agent stack. Но выигрывать будут команды, которые умеют строить компетентные рабочие процессы, а не просто собирать модные компоненты в одну диаграмму.
- Не занимайте архитектурный слот красивой обвязкой, если у вас не описан рабочий процесс.
- Считайте контекст проекта частью системы, а не внешним приложением к ней.
- Проверяйте не только итоговый ответ агента, но и путь, которым он к нему пришёл.
- Делайте ставку на воспроизводимость и повторяемость, а не на эффектную автономность в демо.
Вывод
Сегодняшний хайп вокруг оркестрации AI-агентов во многом и правда напоминает эпоху LAMP. Рынок снова полюбил стек. Это нормально: индустрии всегда проще продавать набор компонентов, чем культуру проектирования. Но свежие данные уже показывают, где проходит настоящая граница. MolClaw выигрывает там, где решает задачу workflow competence. Paper про reproduction соцнаук показывает, что красивый scaffold ломается на неясной методологии и хрупкой воспроизводимости.
Поэтому главный вопрос для 2026 года звучит не так: «какой стек взять для AI-агентов?» Правильный вопрос другой: «какую рабочую дисциплину мы строим вокруг модели, инструментов и контекста?» Стек поможет начать. Преимущество создаст не он.
Источники и дата проверки
- Хабр: «Новый LAMP, или почему ваш Agent Pipeline — это Apache в 2006 году». Опубликовано 27 апреля 2026 года, проверено 27 апреля 2026 года.
- arXiv: MolClaw. Submitted on 2 April 2026, проверено 27 апреля 2026 года.
- arXiv: Read the Paper, Write the Code. Submitted on 23 April 2026, проверено 27 апреля 2026 года.



