бизнес Контроль расходов на ИИ: почему компании переходят от энтузиазма к лимитам Компании переходят от безлимитного внедрения ИИ к лимитам, бюджетам и маршрутизации моделей. Что меняет usage-based billing и как считать AI-агентов.
безопасность Киберриски frontier AI: Five Eyes говорят, что ждать нельзя Five Eyes предупредили: frontier AI меняет киберриски за месяцы. Разбираем практический вывод для бизнеса, AppSec и команд с ИИ-инструментами.
AI-агенты Sakana AI Fugu: один API для нескольких LLM Sakana AI Fugu — новый OpenAI-совместимый API, за которым работает модель-оркестратор нескольких LLM. Разбираем, что запустила Sakana, сколько это стоит и где заканчивается защита от vendor lock-in.
LLM Аудит прозрачности DiffusionGemma: что видно в reasoning Свежий аудит DiffusionGemma проверяет, насколько reasoning у diffusion-LLM остаётся наблюдаемым: opaque serial depth, token bottleneck и monitorability.
LLM SubQ LLM: что стоит за заявлениями о sparse attention и 12 млн токенов SubQ заявляет sparse attention, 12 млн токенов и резкое снижение стоимости длинного контекста. Разбираем, что подтверждено, а что пока остаётся claim.
Anthropic Зависимость от американского ИИ: что показало отключение Anthropic Fable 5 и Mythos 5 стали стресс-тестом для стран и компаний, зависящих от американских AI-платформ. Разбираем политический риск и сценарии снижения зависимости.
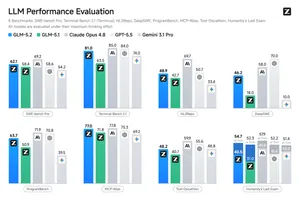
LLM GLM-5.2: open-source AI coding с контекстом 1M токенов GLM-5.2 делает ставку на long-horizon AI coding: 1M-token context, открытые веса, локальный serving и benchmark claims против закрытых frontier-моделей.