Llama 4 в 2026 году: Scout, Maverick и границы open weights Meta
Llama 4 — это не одна модель, а семейство Scout и Maverick с разной экономикой, лицензией и требованиями к запуску. Разбираем, что Meta реально открыла и где проходят границы.
Проверено 6 мая 2026 года. Llama 4 удобно обсуждать как одну модель, но это уже неточно. В актуальной открытой линейке Meta есть как минимум два разных продукта: Llama 4 Scout и Llama 4 Maverick. Рядом с ними Meta отдельно описывает Llama 4 Behemoth, но его не раздаёт как open-weight релиз: это teacher-модель, которая всё ещё находится в обучении.
Если нужен короткий ориентир, он такой: Scout стоит смотреть, когда важны длинный контекст и более реалистичный запуск в своей инфраструктуре; Maverick — когда нужен старший вариант семейства с более сильными результатами на reasoning, coding и image understanding; Behemoth пока полезен только как ориентир того, куда Meta ведёт линейку. Для более широкого сравнения рынка open-weight моделей у нас уже есть отдельный материал про Llama 4, Mistral и Qwen3, а здесь разбираем именно семейство Llama 4 как самостоятельный reference-URL.
Коротко: что входит в Llama 4
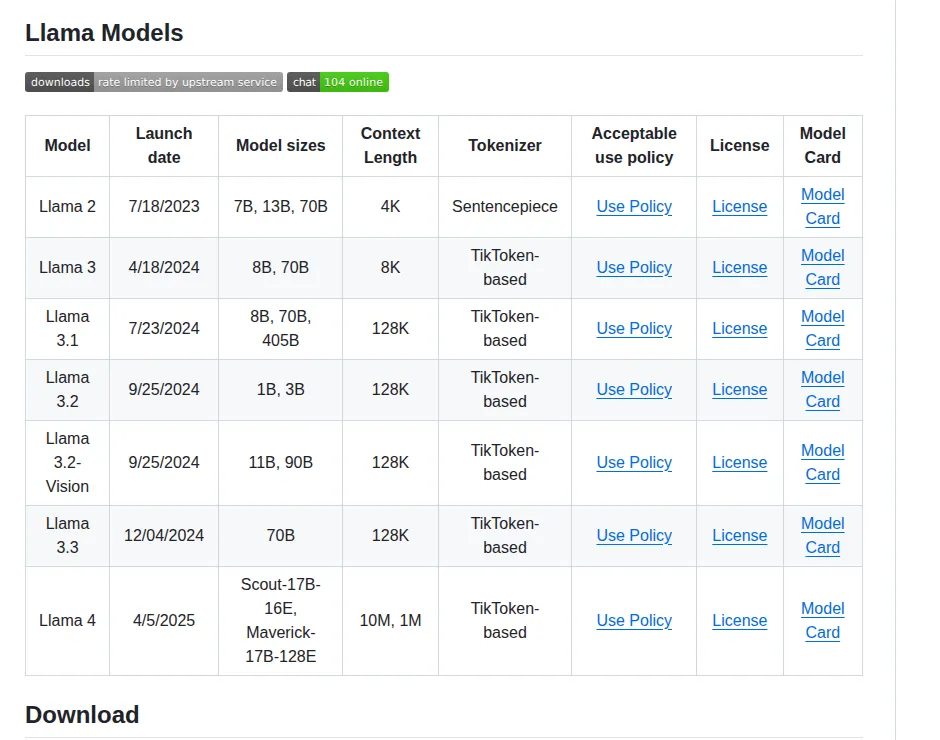
| Модель | Что подтверждено официально | Когда смотреть в первую очередь | Что помнить |
|---|---|---|---|
| Scout | 17B активных параметров, 109B total, 10M контекст, текст + изображения на входе | Длинные документы, мультимодальные пайплайны, экспериментальный self-hosted inference | Для полного bf16 Meta рекомендует минимум 4 GPU; одиночный H100 возможен только в более лёгких режимах вроде Int4 |
| Maverick | 17B активных параметров, 400B total, 1M контекст, текст + изображения на входе | Когда внутри Llama 4 нужен более сильный вариант по качеству, чем Scout | Это не «локальная модель для каждого»: требования к железу всё ещё серьёзные |
| Behemoth | 288B активных параметров, 16 экспертов, teacher-модель для новых релизов | Как ориентир направления линейки, а не как доступный релиз | Meta прямо пишет, что Behemoth всё ещё в обучении и не выпущен как открытый вес |
Что Meta реально изменила в Llama 4
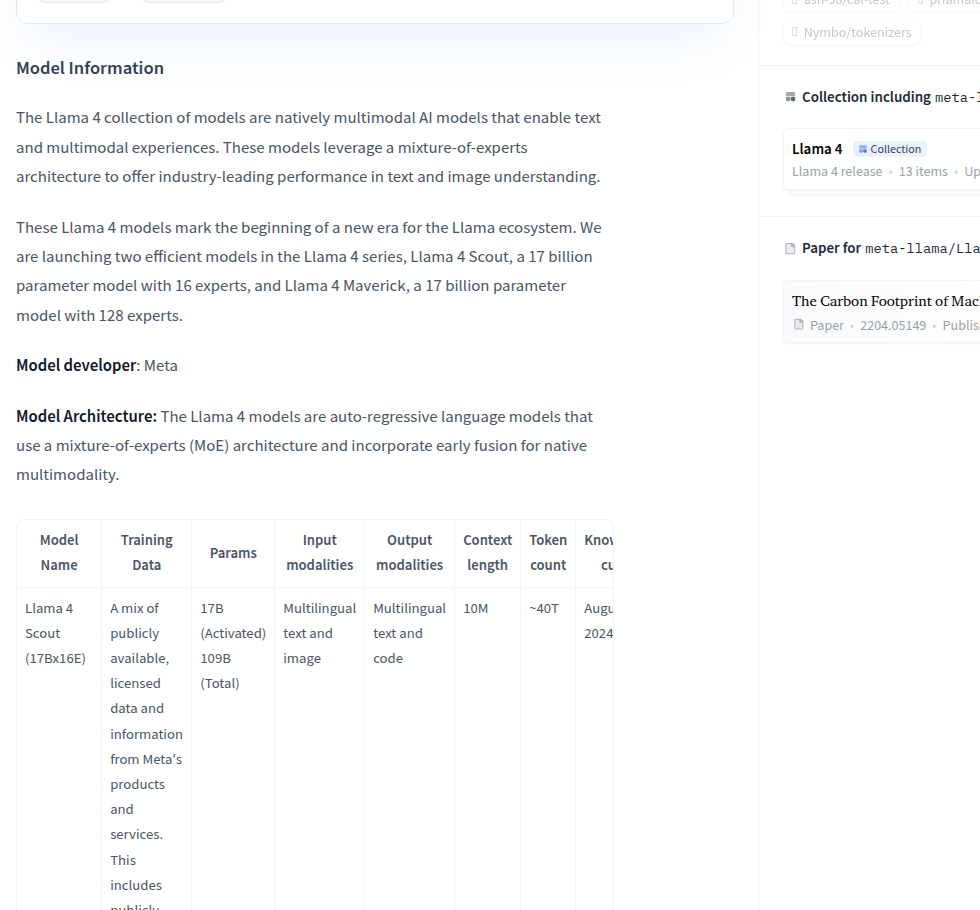
Официальная model card Meta описывает Llama 4 как natively multimodal семейство с архитектурой mixture-of-experts и early fusion. Это важнее, чем звучит в пресс-релизе. Для разработчика смысл такой: Meta пытается совместить более экономный inference с более богатой моделью, не возвращаясь к плотной схеме, где каждый токен тащит за собой весь вес модели.
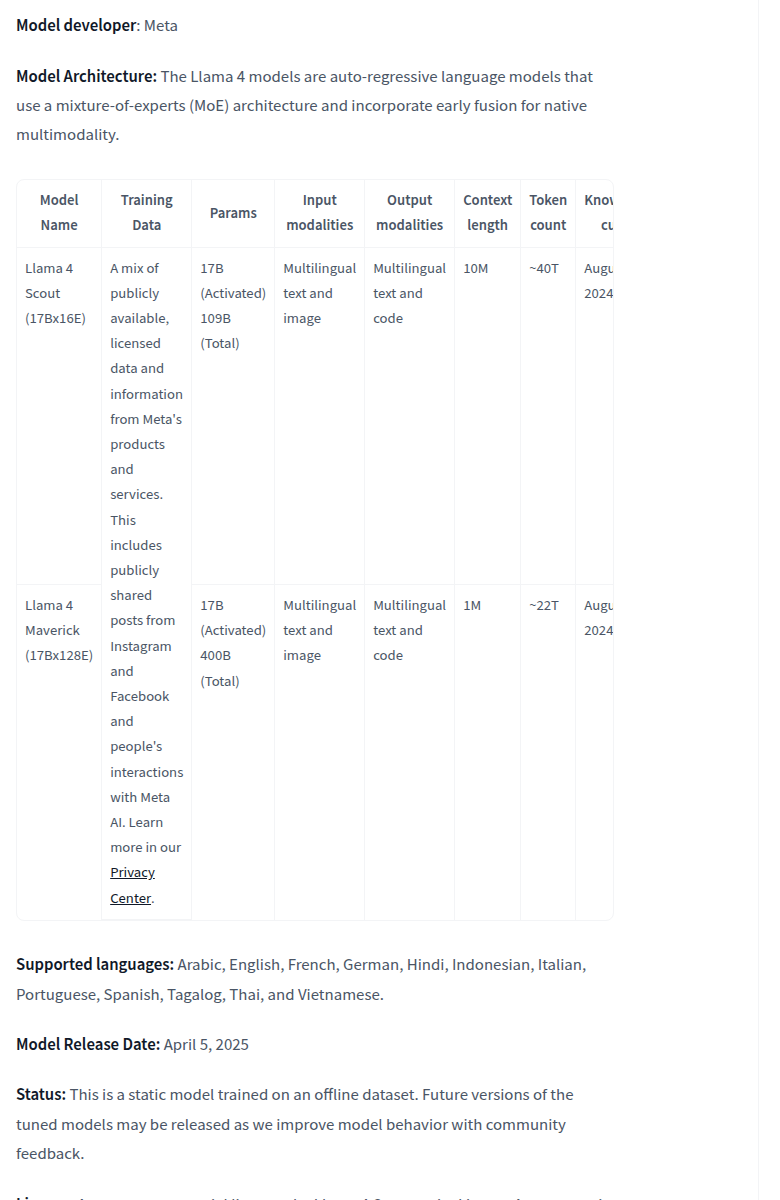
У Scout и Maverick общий активный размер — 17B параметров, но разный общий объём весов и разная геометрия линейки. По model card Scout — это 17B activated / 109B total с 10M контекста, Maverick — 17B activated / 400B total с 1M контекста. Именно поэтому разговор про Llama 4 нельзя сводить к одной цифре «сколько у модели параметров»: практический опыт определяется не только total weights, но и тем, сколько из них реально включается в работу, какой контекст вы получаете и на каком железе вообще можете это запустить.
Meta также прямо пишет, что Scout и Maverick — это первые open-weight мультимодальные модели семейства. Здесь важна формулировка open weights, а не привычное для сообщества «open source». Весы доступны, но поверх них лежит собственная лицензия Meta с отдельными коммерческими условиями и use policy.
Почему Llama 4 нельзя путать с Apache-стеком
Самая частая ошибка вокруг Llama — называть её «полностью открытой» в том же смысле, что и модели под Apache 2.0 или MIT. Официальные документы Meta этому противоречат. И в model card на Hugging Face, и в файле LICENSE из репозитория meta-llama/llama-models указана Llama 4 Community License, а не permissive open-source лицензия.
- Лицензия даёт право использовать, модифицировать и распространять Llama 4, включая коммерческие сценарии.
- При распространении Meta требует сохранять текст лицензии и видимую пометку Built with Llama.
- Если продукт или сервис на дату релиза имеет более 700 миллионов monthly active users, нужна отдельная лицензия от Meta.
- Использование должно соответствовать отдельной acceptable use policy.
Практический вывод отсюда простой: Llama 4 — это не «бери и делай что угодно без условий». Для стартапа или внутренней корпоративной команды такая лицензия обычно не блокер. Для большого потребительского продукта и особенно для юридического сравнения с моделями под действительно свободными лицензиями это уже важная развилка. Если вам нужен более общий разбор выбора между open weights и закрытыми API, посмотрите наш материал про открытые модели и закрытые API: там эта развилка разобрана отдельно, а здесь важно не путать доступность весов с полной свободой лицензирования.
Что это означает для русскоязычного использования
Для русскоязычной аудитории у Llama 4 есть важная оговорка, которую часто пропускают пересказы. В официальной model card Meta перечисляет 12 supported languages: Arabic, English, French, German, Hindi, Indonesian, Italian, Portuguese, Spanish, Tagalog, Thai и Vietnamese. Русского в этом списке нет.
При этом Meta отдельно пишет, что в pretraining использовалось 200 total languages, и разработчики могут дообучать модель для дополнительных языков, если соблюдают лицензию и policy. Это не противоречие, а нормальная инженерная граница. По-русски Llama 4 может работать, но Meta не даёт здесь того же уровня supported-обязательств, что по 12 перечисленным языкам. Поэтому для русскоязычного продакшна правильный подход только один: не переносить англоязычные цифры как гарантию качества, а прогонять собственную оценку на русских данных.
Локальный запуск без самообмана
Ещё одна ловушка старых обзоров — писать про Llama 4 так, будто это «модель для локального ноутбука». Официальные документы Meta дают куда более жёсткую картину.
- В GitHub-репозитории
meta-llama/llama-modelsпрямо сказано: серия Llama 4 требует как минимум 4 GPU для inference в полномbf16. - Там же Meta пишет, что для Scout в режиме
fp8_mixedнужны 2 GPU по 80GB, а вint4_mixedдостаточно одной 80GB GPU. - В model card Meta уточняет, что Maverick выпускается и в
FP8, и что FP8-весы помещаются на single H100 DGX host.
То есть Llama 4 действительно можно запускать вне чужого API, но это не означает «дёшево и везде». Для большинства команд реальный вопрос звучит не «можно ли локально», а готовы ли вы к инфраструктуре уровня H100-класса ради контроля над весами, длинного контекста и лицензии Meta вместо закрытого API. Если нужен практический разбор, у нас есть отдельный материал как запустить Llama локально и использовать её на русском. А если нужен соседний инженерный контекст про то, как индустрия вообще пытается удешевить запуск огромных моделей, полезно посмотреть наш материал про Streaming Experts и триллионную модель на MacBook.
Что показывают официальные бенчмарки
Meta в model card сравнивает Llama 4 в первую очередь со своими предыдущими поколениями, а не строит универсальную «таблицу истины» по всему рынку. Это хороший сигнал: такие цифры проще читать без лишнего маркетинга.
По pre-trained таблице Maverick выше Scout на ряде важных метрик: MMLU-Pro 62.9 против 58.2, MATH 61.2 против 50.3, MBPP 77.6 против 67.8. По instruction-tuned блоку разрыв тоже виден: LiveCodeBench 43.4 против 32.8, GPQA Diamond 69.8 против 57.2, MMLU Pro 80.5 против 74.3. Проще говоря, официальные таблицы Meta сами подсказывают, что Maverick — это не просто ещё одна версия Scout, а более сильный старший вариант внутри одной семьи.
Отдельно стоит помнить, что Meta позиционирует Behemoth как teacher-модель для новых релизов и в официальной статье пишет, что она превосходит GPT-4.5, Claude Sonnet 3.7 и Gemini 2.0 Pro на STEM-бенчмарках вроде MATH-500 и GPQA Diamond. Но это важно читать аккуратно: Behemoth не выпущен как доступный open-weight релиз, поэтому для практического выбора между доступными моделями сегодня этот тезис скорее объясняет происхождение линейки, чем помогает выбрать конкретный чекпойнт для работы.
Когда Llama 4 имеет смысл, а когда нет
Llama 4 стоит смотреть в первую очередь, если у вас есть одна из трёх задач: нужен контроль над весами и инфраструктурой, нужен экстремально длинный контекст без перехода в закрытый API, или вам важен мультимодальный стек Meta под собственные ограничения безопасности и развёртывания.
Llama 4 не лучший первый шаг, если команда на самом деле ищет дешёвый старт, ноутбучный локальный запуск «для всех», гарантированную сильную работу на русском из коробки или просто хочет быстрее дойти до продакшна без собственной inference-инфраструктуры. В таких сценариях разговор надо начинать не с бренда Llama 4, а с более общего выбора между самостоятельным развёртыванием и управляемым API.
Итог
Llama 4 в 2026 году — это уже не новостной анонс, а вполне оформленное семейство со своей логикой выбора. Scout — про длинный контекст и более реалистичный вход в open-weight стек Meta. Maverick — про старший уровень качества внутри доступной линейки. Behemoth — про направление развития, а не про то, что можно скачать сегодня.
Главная редакторская поправка здесь одна: не путайте open weights с полной свободой лицензирования и не путайте поддержанный язык с любым языком, который модель когда-то видела на pretraining. Именно на этих двух местах старые статьи про Llama 4 быстрее всего превращаются в неточный пересказ.



