Streaming experts: как запустить триллионную модель на MacBook
Технология streaming experts позволяет запускать триллионные модели ИИ на обычном MacBook. Разбираем Flash-MoE, практические настройки и результаты тестов Qwen и Kimi.
Дэн Вудс, вице-президент по ИИ-платформам CVS Health, за сутки собрал движок на C и Metal, который запускает 397-миллиардную языковую модель на обычном MacBook Pro с 48 ГБ оперативной памяти. На следующий день ту же модель запустили на iPhone 17 Pro. А через пять дней другой разработчик поднял Kimi K2.5, модель с триллионом параметров, на MacBook с 96 ГБ RAM.
Идея простая: вместо того чтобы загружать все веса модели в память, читать их с SSD по мере необходимости.
Mixture of Experts и почему SSD достаточно
Классические языковые модели (dense) при генерации каждого токена задействуют все свои параметры. Для модели на 397 миллиардов параметров это значит: все 397 миллиардов весов должны быть в памяти. При четырёхбитной квантизации получается порядка 200 ГБ, больше, чем есть у любого ноутбука.
Архитектура Mixture of Experts (MoE) работает иначе. Модель содержит сотни «экспертов» — небольших подсетей внутри каждого слоя. Для каждого токена маршрутизатор выбирает только 4 из 512 экспертов. У Qwen3.5-397B-A17B общий объём параметров составляет 397 миллиардов, но активных в любой момент всего 17 миллиардов.
Отсюда и лазейка: не нужно держать в памяти всю модель. Достаточно загружать нужных экспертов с диска для каждого токена. Постоянно в памяти находятся только неэкспертные веса (5,5 ГБ) и текущие активные эксперты.
Flash-MoE: чистый C, Metal и никакого Python
Проект Flash-MoE написан с нуля: 7 000 строк на Objective-C, 1 200 строк Metal-шейдеров и кастомный BPE-токенизатор на чистом C. Ни PyTorch, ни llama.cpp, ни каких-либо других фреймворков.
Ключевая техника — SSD Expert Streaming. Веса экспертов (209 ГБ при четырёхбитной квантизации) лежат на NVMe-диске. Для каждого слоя трансформера движок определяет четырёх активных экспертов, параллельно читает их веса через pread() с GCD и отправляет на GPU. Каждый эксперт занимает около 6,75 МБ; на чтение четырёх уходит примерно 2,4 мс при скорости SSD 17,5 ГБ/с.
Кеширование экспертов полностью отдано операционной системе. Вудс и его ИИ-ассистент перепробовали 58 вариантов: LRU-кеш на Metal, сжатие LZ4, предзагрузка через F_RDADVISE, предсказание маршрутов. Всё оказалось медленнее стандартного page cache macOS с 71% попаданий. Они назвали этот принцип «Trust the OS».
Бенчмарки на MacBook Pro
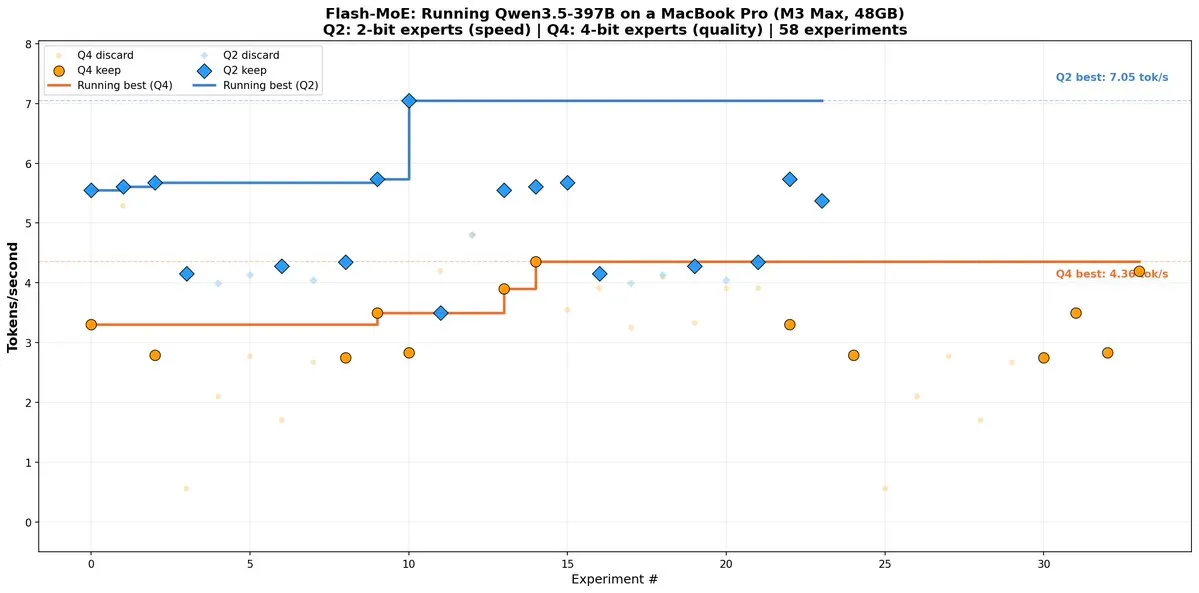
Тестовая машина — MacBook Pro на Apple M3 Max: 48 ГБ unified memory, SSD на 17,5 ГБ/с последовательного чтения. Результаты для Qwen3.5-397B-A17B:
| Конфигурация | Скорость (токенов/с) | Качество | Размер на диске |
|---|---|---|---|
| 4-bit эксперты, FMA-ядро | 4,36 | Отличное, tool calling работает | 209 ГБ |
| 4-bit эксперты, базовое ядро | 3,90 | Отличное | 209 ГБ |
| 2-bit эксперты | 5,74 | Хорошее, но ломает JSON | 120 ГБ |
| 2-bit, пиковый токен | 7,05 | Хорошее, только тёплый кеш | 120 ГБ |
Рабочая конфигурация — четырёхбитная. При двухбитной квантизации модель путает кавычки в JSON-выводе (\name\ вместо "name"), что ломает tool calling. Стартовая скорость до оптимизаций была 0,28 токена в секунду, итоговое ускорение — более чем в 15 раз.
Оптимизации, которые сработали
Из 90 с лишним экспериментов Вудс выделил несколько ключевых улучшений:
- FMA-ядро деквантизации: перестановка арифметики в шейдере с
(nibble × scale + bias) × xнаfma(nibble, scale×x, bias×x)позволяет GPU выполнять деквантизацию и умножение за одну инструкцию. Прирост — 12%. - Ускорение линейного внимания через Accelerate BLAS: рекуррентное обновление состояния GatedDeltaNet через
cblas_sgemvиcblas_sgerускорило attention-слои на 64%. - Отложенное выполнение на GPU: CMD3 (прямой проход экспертов) отправляется без ожидания результата, GPU работает параллельно с подготовкой следующего слоя на CPU.
- Фьюзинг операций: combine + residual + нормализация выполняются в одном GPU-ядре, убирая лишние round-trip между CPU и GPU.
Что не сработало: сжатие экспертов LZ4 (−13%), предсказание маршрутов через MLP (точность всего 31%), кластеризация файлов экспертов (NVMe игнорирует scatter на гранулярности 7 МБ), spin-poll ожидание GPU (−23% из-за нагрева CPU). Полный лог экспериментов доступен в репозитории.
397 миллиардов на iPhone 17 Pro
Разработчик под ником anemll портировал Flash-MoE на iOS. На iPhone 17 Pro (чип A19 Pro, 12 ГБ RAM) Qwen3.5-397B-A17B выдаёт 0,6 токена в секунду при двухбитной квантизации. Время до первого токена — почти 50 секунд.
Для повседневной работы это непригодно. Но 400-миллиардная модель работает на телефоне, занимая 5,5 ГБ оперативной памяти, а остальное стримится с SSD. Телефон при этом остаётся рабочим, другие приложения продолжают работать.
Главный ограничитель здесь — скорость SSD. У M3 Max она достигает 17,5 ГБ/с, у iPhone 17 Pro заметно меньше. При таком подходе именно пропускная способность диска, а не объём RAM определяет скорость генерации.
Триллион параметров на MacBook
Саймон Уиллисон сообщил, что разработчик @seikixtc запустил Kimi K2.5 — MoE-модель с триллионом параметров и 32 миллиардами активных весов — на MacBook Pro M2 Max с 96 ГБ RAM. Принцип тот же: неактивные эксперты лежат на диске, активные подгружаются по требованию.
Kimi K2.5 от Moonshot AI — та самая модель, которая недавно оказалась под капотом Cursor Composer 2. У неё 512 экспертов на слой, как и у Qwen3.5, но общий объём параметров на порядок больше. Ещё месяц назад запуск триллионной модели на потребительском ноутбуке казался нереальным.
Практическая ценность streaming experts
Streaming experts — не конкурент облачному inference. При 4 токенах в секунду модель генерирует текст в 10–50 раз медленнее серверных кластеров с GPU. Но у подхода есть практические ниши.
Приватность: данные не покидают устройство. Для юристов, врачей, финансистов это может оказаться решающим аргументом. Автономность: модель работает без интернета, без подписки, без API-ключей, что актуально в полевых условиях и на удалённых локациях. И наконец, доступность: frontier-модель теперь запускается на ноутбуке, а не на кластере GPU за миллионы долларов.
Вудс и сообщество продолжают оптимизацию. По словам Уиллисона, они запускают autoresearch-циклы — автоматические серии экспериментов — чтобы выжать ещё больше производительности. Ближайший ориентир: 10 токенов в секунду на потребительском железе.



