Новая архитектура Transformer: адаптивные циклы и банки памяти вместо глубины
Немецкие исследователи предложили Transformer с адаптивными циклами и банками памяти. Модель на 12 слоёв обходит классическую 36-слойную на математических бенчмарках на 6,4%.
Языковые модели умеют рассуждать пошагово через chain-of-thought, но за каждый промежуточный шаг приходится платить токенами. Группа немецких исследователей из Lamarr Institute, Fraunhofer IAIS и Боннского университета предложила другой подход: пусть модель сама решает, сколько раз прогнать данные через один и тот же вычислительный блок. А для хранения фактов ей дали отдельные банки памяти.
Модель с 12 слоями и тройным циклом обходит классическую 36-слойную модель на математических бенчмарках. Статья опубликована на arXiv и представлена на воркшопе Latent & Implicit Thinking на ICLR 2026.
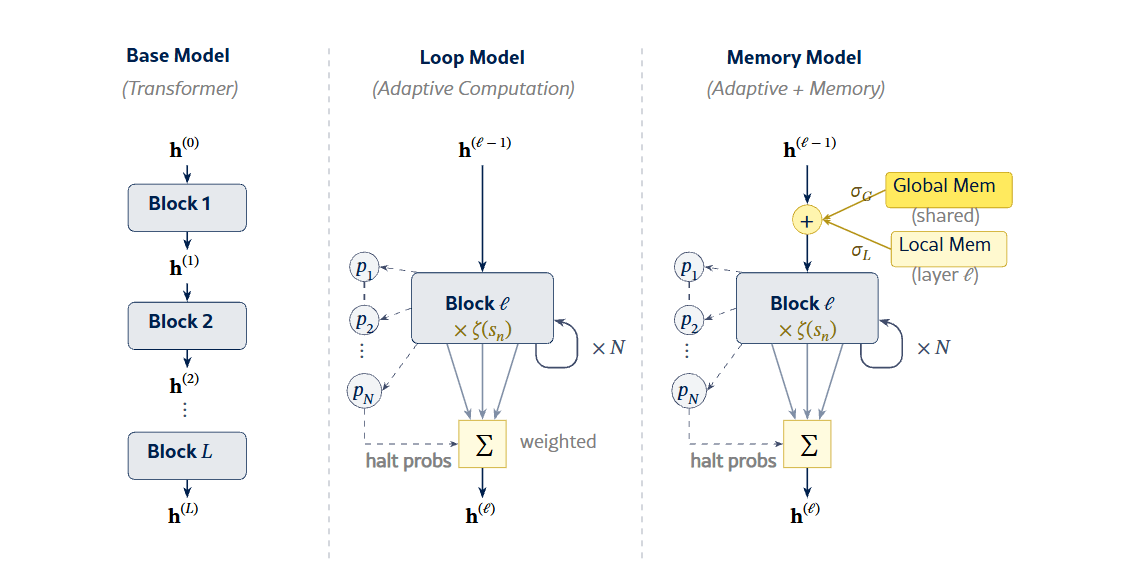
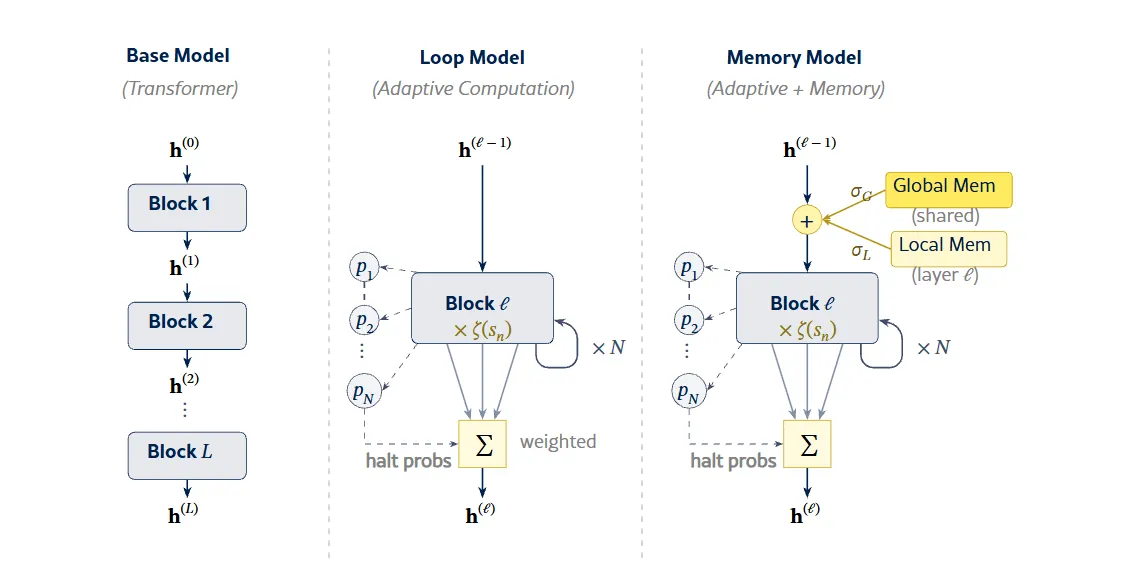
Как устроена архитектура
В основе лежит decoder-only Transformer на 12 слоёв и примерно 200 миллионов параметров, обученный на 14 миллиардах токенов из датасета FineWeb Edu. Исследователи добавили к нему два механизма.
Первый — адаптивные циклы. Каждый слой получил обучаемый механизм остановки (halting mechanism). Вместо однократного прохода данных через блок слой может прогнать их повторно, до 3, 5 или 7 раз в зависимости от конфигурации. Модель сама учится, когда повторять вычисления, а когда хватит одного прохода.
Второй — банки памяти. К каждому слою подключены 1024 локальных слота памяти, плюс 512 глобальных слотов, общих для всех слоёв. Это добавляет около 10 миллионов параметров, менее 5% от общего числа. Доступ к памяти управляется гейтами, которые модель обучает совместно с остальными весами.
Циклы дают модели дополнительное «время на размышление» без генерации промежуточных токенов. Банки памяти компенсируют нехватку уникальных весов для хранения фактов, которая возникает при повторном использовании одних и тех же слоёв.
Циклы решают математику, память закрывает знания
Два механизма разделили зоны ответственности довольно чётко.
Модель с тройным циклом набрала на 22% больше на математических задачах по сравнению с базовой версией без циклов. Самый заметный рост показали подкатегории Precalculus (+31%) и Intermediate Algebra (+26%). На задачах, требующих бытовых знаний (социальные ситуации, физическая интуиция), циклы почти не помогли. При увеличении числа итераций результаты там даже немного снижались.
Банки памяти закрыли другую проблему. Бытовые знания нельзя получить повторным обдумыванием, их нужно где-то хранить. Память добавила 4,2% на математике и 2% на задачах здравого смысла по сравнению с вариантом без неё.
Ранние слои экономят, поздние работают интенсивнее
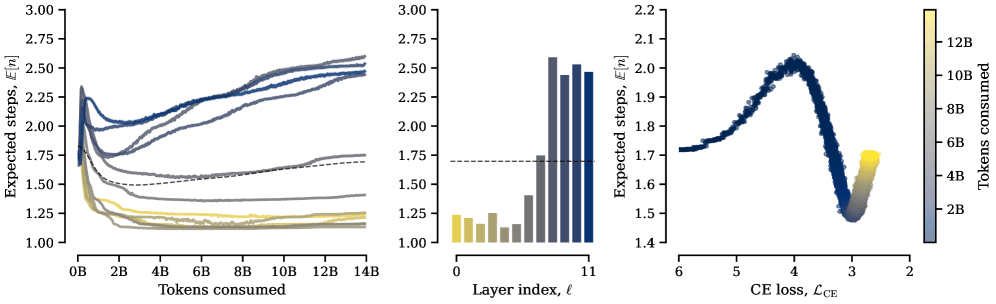
Хотя модель не получает штрафа за число итераций, специализация слоёв возникает сама собой. Ранние слои обучаются повторять вычисления минимально и почти не обращаются к памяти. Поздние, наоборот, активно используют и циклы, и банки памяти.
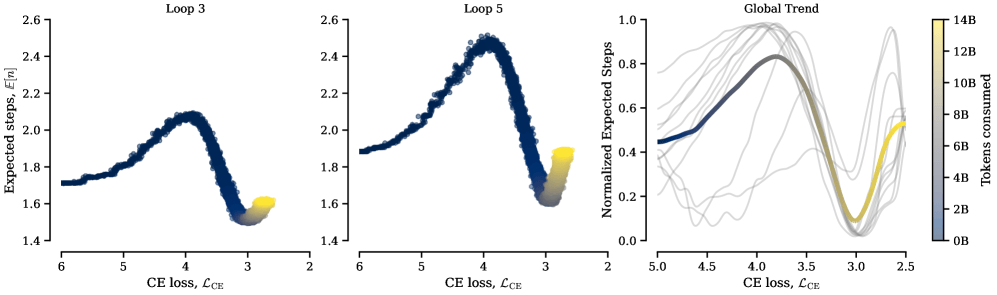
Это согласуется с предыдущими исследованиями: ранние слои Transformer кодируют локальные синтаксические паттерны, а поздние обрабатывают более сложные семантические и логические операции. Простые вычисления не выигрывают от повторных проходов, а вот сложные операции в глубоких слоях — вполне.
Есть и эффект порога. В начале обучения модели почти не используют циклы, хотя могут. Только когда модель достаточно хорошо освоила язык, она начинает повторять вычисления. По данным исследователей, этот порог срабатывает примерно в одной и той же точке для всех конфигураций. Сначала нужно научиться языку, и лишь потом можно извлечь пользу из повторного обдумывания.
Больше вычислений требует больше знаний
Авторы видят в результатах подтверждение того, как распределены роли внутри Transformer. Feed-forward слои работают как хранилище фактических ассоциаций, а слои внимания маршрутизируют и обрабатывают информацию. Циклы улучшают маршрутизацию, но не могут компенсировать недостаток ёмкости хранения.
Слои, которые чаще повторяют вычисления, также чаще обращаются к локальной памяти. Глобальная память, напротив, распределяется равномерно по всем слоям. Циклы и память работают в связке: больше вычислений требует больше фактов.
Ограничения и что дальше
Авторы обозначают границы работы. Эксперименты проводились на модели с 200 миллионами параметров и 14 миллиардами токенов обучения, это небольшой масштаб по современным меркам. Сохранится ли эффект для моделей с миллиардами параметров, которые уже обладают значительной встроенной ёмкостью, пока неизвестно.
Вместо наращивания числа слоёв (а с ними параметров и стоимости обучения) можно дать модели возможность самой выбирать глубину обработки для каждой задачи. Внешние банки памяти решают проблему хранения фактов без увеличения числа уникальных весов.
Для тех, кто следит за развитием промпт-инжиниринга и техник вроде chain-of-thought, работа ставит практичный вопрос: возможно, вербализация рассуждений не единственный способ заставить модель думать. А для проектирования open-source моделей адаптивные циклы могут стать способом получить производительность большой модели при заметно меньших затратах.



