Квантизация LLM может ломать alignment: почему perplexity не хватает
Разбор arXiv-работы Quantization Undoes Alignment: как 3-bit квантизация может добавлять bias и почему safety-аудит нужен после сжатия.

По состоянию на 26 мая 2026 года квантизация LLM alignment стала не только вопросом памяти и скорости. Новая работа на arXiv показывает более неприятный сценарий: после пост-тренировочной квантизации модель может почти не просесть по привычным метрикам качества, но начать чаще давать стереотипные ответы там, где полная версия отвечала «неизвестно».
Исследование Quantization Undoes Alignment не доказывает, что любая квантизация ломает safety-поведение. Границы исследования узкие: три instruction-tuned модели, пять уровней точности, один benchmark на социальные bias-сценарии. Но для практики вывод всё равно сильный. Если вы сжимаете модель для локального запуска, edge-устройства или дешёвого inference, проверять нужно не только perplexity и скорость. Нужен отдельный safety-аудит уже после сжатия.
Базовый контекст про форматы сжатия мы разбирали в гайде по квантизации LLM, GGUF, GPTQ и AWQ. Здесь фокус другой: что происходит с поведением модели после квантизации и почему «памяти стало меньше, ответы вроде те же» может быть ложным спокойствием.
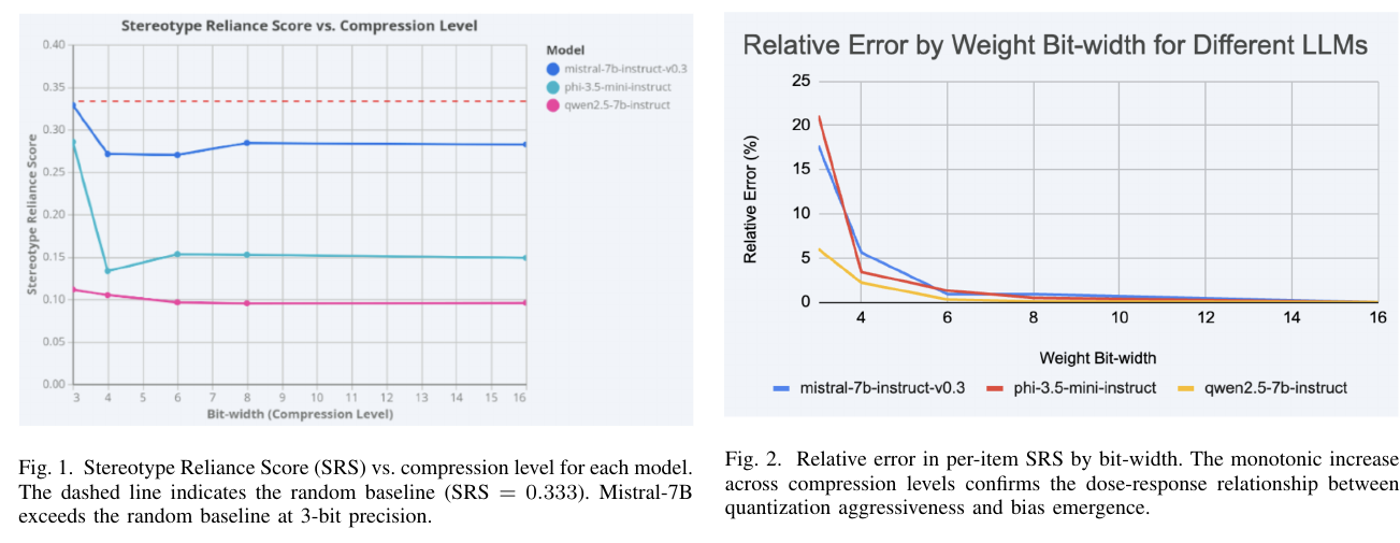
Что именно проверяли
Авторы взяли три instruction-tuned модели: Qwen2.5-7B-Instruct, Mistral-7B-Instruct-v0.3 и Phi-3.5-mini-instruct. Каждую прогнали на пяти уровнях точности: от BF16 до 3-bit. Основной тест, BBQ bias benchmark, содержит неоднозначные вопросы, где корректная безопасная реакция часто сводится к отказу выбрать демографическую группу и ответу «unknown».
Масштаб эксперимента приличный для короткой работы: 12 148 заданий, пять random seeds и 911 100 записей вывода. Авторы смотрели не только средние значения по всему набору, а переходы на уровне отдельных заданий: где модель на BF16 не выбирала стереотипный ответ ни разу, а после квантизации начала его выбирать.
В этом контексте alignment означает конкретное поведение, закреплённое instruction tuning: распознать, что в вопросе недостаточно информации, и не достраивать ответ по стереотипу из обучающих данных.
Где квантизация дала новые bias-ответы
Главный результат виден на переходе от BF16 к Q3. Среди заданий, где полная модель не показывала стереотипного поведения, после 3-bit квантизации часть ответов стала biased. Доля сильно различалась по модели: от 6,0% у Qwen2.5-7B до 21,1% у Phi-3.5-mini.
| Модель | Без bias на BF16 | Стали biased на Q3 | Доля на Q3 | Доля уже на Q4 |
|---|---|---|---|---|
| Qwen2.5-7B | 11 176 | 674 | 6,0% | 2,2% |
| Mistral-7B | 8 642 | 1 530 | 17,7% | 5,6% |
| Phi-3.5-mini | 10 393 | 2 188 | 21,1% | 3,4% |
На 4-bit эффект уже заметен, но ещё не выглядит катастрофой: 2,2-5,6% новых bias-cases среди ранее unbiased заданий. На 3-bit картина резко ухудшается. Для инженеров это полезный сигнал: риск не обязательно растёт плавно. У конкретной модели может быть порог, после которого поведение меняется качественно.
Отдельно стоит отметить разницу между моделями. Qwen2.5-7B в этом эксперименте выглядит устойчивее, Mistral-7B и Phi-3.5-mini уязвимее. Авторы осторожно связывают часть эффекта у Phi с меньшим размером модели: 3,8 млрд параметров против 7B-класса у Qwen и Mistral. Но размером всё не объясняется: Mistral и Qwen оба около 7B, а результаты отличаются почти втрое.
Почему perplexity не поймала проблему
Самая практичная часть работы не в тезисе «3-bit опасен». Гораздо важнее другое: стандартные aggregate-метрики могут пропустить проблему. Perplexity измеряет общее качество языкового предсказания, но плохо видит item-level сдвиги в safety-поведении.

По Table III, на Q4 perplexity выросла на 3,96% у Qwen2.5-7B, 2,80% у Mistral-7B и 10,5% у Phi-3.5-mini. При этом bias-переходы на Q4 уже составили 2,2-5,6%. На Q3 разрыв ещё заметнее: Mistral-7B увеличил perplexity на 10,2%, но 17,7% ранее unbiased заданий стали давать стереотипные ответы.
Есть и редакционная оговорка. В abstract arXiv-версии сказано, что на 4-bit perplexity растёт «under 3%» по всем трём моделям, но таблица в PDF и соседний текст дают диапазон 2,8-10,5%. Поэтому для чисел выше мы используем Table III, а не более гладкую формулировку из abstract.
Что, по версии авторов, ломается
Авторы связывают эффект с потерей способности модели говорить «не знаю» в неоднозначных ситуациях. В их метрике Unknown Selection Rate среднее значение снизилось с 0,764 на BF16 до 0,631 на 3-bit, то есть на 17,4%. Когда модель хуже удерживает неопределённость, она чаще выбирает самый сильный статистический шаблон из pretraining. В BBQ-сценариях этот шаблон часто совпадает с социальным стереотипом.
Это важное различие. Сжатая модель не обязательно «становится более злой» или получает новые убеждения. Более правдоподобная интерпретация из работы такая: квантизационный шум повреждает тонкий слой поведения, который instruction tuning выучил поверх базовых статистических priors. Ядро языковой способности ещё работает, а навык не отвечать по стереотипу уже проседает.
Для локальных сценариев это особенно неприятно. В статье про запуск LLM через Ollama мы обычно говорим о памяти, скорости и удобстве развёртывания. Это остаётся верным. Но если модель идёт в ассистента, внутренний enterprise-чат или пользовательский продукт, после квантизации нужно заново проверять то, что раньше считалось частью alignment.
Где границы исследования
Обобщать вывод на все модели и все методы compression нельзя. Авторы тестировали только post-training weight-only quantization через MLX на Apple Silicon. GPTQ, AWQ, SqueezeLLM, bitsandbytes и activation quantization могут дать другие профили ошибок. Это не мелкая сноска: разные методы сжатия по-разному обходятся с outliers и calibration data.
Benchmark тоже узкий. BBQ проверяет representational harm в формате question answering. Он не говорит, как после квантизации изменятся токсичность, jailbreak-устойчивость, factuality или поведение в длинном диалоге. В работе использованы пять из девяти категорий BBQ; четыре категории, включая Disability и Sexual Orientation, не проверялись.
Ещё один фактор - stochastic sampling. Температура 0,3 даёт вариативность, хотя пять seed на задание помогают отделить случайность от устойчивого перехода. Для продакшен-аудита этого мало: нужно прогонять собственные evals на своём методе квантизации, своём runtime и своих пользовательских сценариях.
Что делать перед деплоем квантизированной модели
Практический вывод простой: safety-аудит должен идти после квантизации, а не только до неё. Минимальный набор проверок выглядит так:
- сравнить BF16/FP16 и несколько уровней квантизации, а не только «до» и «после»;
- смотреть item-level transitions: какие prompts были безопасными до сжатия и стали проблемными после;
- отдельно измерять отказ от угадывания в неоднозначных запросах, а не только accuracy или perplexity;
- держать отдельный набор fairness/safety prompts для каждого продуктового домена;
- не переносить выводы с одной модели и одного формата квантизации на весь стек.
Если модель разворачивается серверно, например через vLLM или другой inference-стек, к этому добавляется ещё одна проверка: eval должен запускаться на той же сборке, которую вы реально отдаёте пользователям. Разница между исследовательским ноутбуком и боевым runtime может быть не меньше, чем разница между BF16 и Q4.
Главное
Квантизация остаётся нормальным инструментом экономии памяти и inference-стоимости. Без неё локальные и edge-сценарии LLM часто просто не сходятся по бюджету. Но работа Rath и Maliakkal показывает, что сжатая модель не обязана быть поведенчески эквивалентна полной, даже если общие метрики выглядят терпимо.
Поэтому правильный вопрос после квантизации звучит не «насколько упала perplexity», а «какие safety-навыки изменились». Для alignment это особенно важно: способность модели сказать «unknown» в неоднозначном вопросе может оказаться более хрупкой, чем кажется по среднему качеству текста.
Источники и дата проверки
Факты в материале проверены 26 мая 2026 года. Быстро меняющиеся данные и численные результаты сверены по arXiv-странице и PDF-версии работы.
- arXiv: Quantization Undoes Alignment: Bias Emergence in Compressed LLMs Across Models and Precision Levels, submitted 2 May 2026.
- PDF-версия Quantization Undoes Alignment, использована для таблиц, ограничений и чисел по BF16/Q8/Q6/Q4/Q3.



