Квантизация LLM: как выбрать GGUF, GPTQ и AWQ в 2026 году
Практический разбор GGUF, GPTQ и AWQ: что выбрать для Ollama, vLLM или TGI и где 4-битный запуск помогает, а где только добавляет путаницу.
Проверено 6 мая 2026 года. Вокруг квантизации LLM в 2026 году слишком много путаницы. GGUF, GPTQ и AWQ часто обсуждают как взаимозаменяемые варианты, хотя на практике они отвечают на разные вопросы: где вы запускаете модель, какой рантайм используете и кто потом будет сопровождать этот стек.
Если часть терминов вроде KV-cache, GGUF или AWQ пока смешивается в одну кучу, сначала откройте словарь терминов ИИ, а затем возвращайтесь к выбору формата.
Если нужен общий маршрут по выбору моделей, начните с полного гайда по LLM для разработчиков. Если выбираете между семействами моделей с открытыми весами, держите рядом разбор Llama, Mistral и Qwen. А здесь разбираем уже следующий слой: как выбрать квантизацию без лишней религии и без дорогостоящих проб вслепую.
| Сценарий | С чего начать | Почему |
|---|---|---|
| Ноутбук, Mac, домашний ПК, локальный запуск через Ollama или llama.cpp | GGUF, обычно Q4_K_M как базовая точка |
GGUF напрямую поддерживается в локальном стеке, а Ollama умеет импортировать и квантизировать такие модели. |
| GPU-сервер под vLLM, где нужны готовые 4-битные веса | AWQ или GPTQ | Эти форматы живут ближе к серверному инференсу и поддерживаются в современных рантаймах вроде vLLM. |
| Serving через Hugging Face TGI | GPTQ или AWQ, если у вас уже есть заранее квантованные веса | TGI поддерживает оба варианта, но для них нужны уже подготовленные веса, а не просто исходный fp16-чекпоинт. |
| Нужен минимум сюрпризов для первой локальной проверки модели | GGUF | Самый короткий путь до ответа на вопрос «эта модель вообще полезна на нашем железе или нет?» |
Что именно меняет квантизация
Квантизация уменьшает точность представления весов, чтобы модель занимала меньше памяти и легче помещалась на доступное железо. В документации vLLM это сформулировано прямо: меньше точность, меньше требуемый объём памяти, шире круг устройств, на которых модель вообще можно запустить. Это не магия и не бесплатный бонус. Это инженерный обмен: вы экономите память, а заодно берёте на себя риск ухудшения качества, несовместимости с рантаймом или более сложной диагностики.
Грубая арифметика здесь простая. Если считать только веса, без служебных тензоров и KV-cache, модель на 70 млрд параметров в fp16 требует около 140 ГБ памяти: два байта на параметр. В 4-битном виде та же модель опускается примерно до 35 ГБ. Уже не карманный вариант, но разница между «совсем не запускается» и «помещается в рабочий контур» здесь вполне реальная.
Именно на этом месте многие команды делают неверный вывод. Они смотрят только на размер весов. А потом выясняется, что контекст длинный, пакет запросов выше ожидаемого, KV-cache разрастается быстрее модели, и экономия на квантовании не спасает. Поэтому вопрос надо ставить не так: «какой формат самый модный?». Правильнее так: «какой формат проще всего обслужить в нашем рантайме и на нашем железе?»
Для общей инженерной карты рядом полезен hub ИИ для разработчиков, а для соседнего подхода к памяти — разбор Google TurboQuant.
GGUF: когда выбирают локальный путь, а не серверный
Самая полезная мысль про GGUF звучит скучно, зато избавляет от половины ошибок: GGUF — это в первую очередь формат файла, а не отдельная теория про «лучшую квантизацию». В документации llama.cpp сказано прямо: проект требует модель в формате GGUF. Там же перечислены целевые сценарии, ради которых этот стек и живёт: локальный инференс на широком наборе железа, включая Apple Silicon, CPU и обычные потребительские GPU.
Отсюда и практический вывод. Если вы запускаете модели через Ollama, llama.cpp или похожий локальный рантайм, начинать почти всегда рационально с GGUF. Не потому что он «лучше GPTQ вообще», а потому что он родной для этого контура. Ollama отдельно документирует импорт GGUF-моделей и умеет квантизировать fp16/fp32 чекпоинты в уровни вроде q4_K_M.
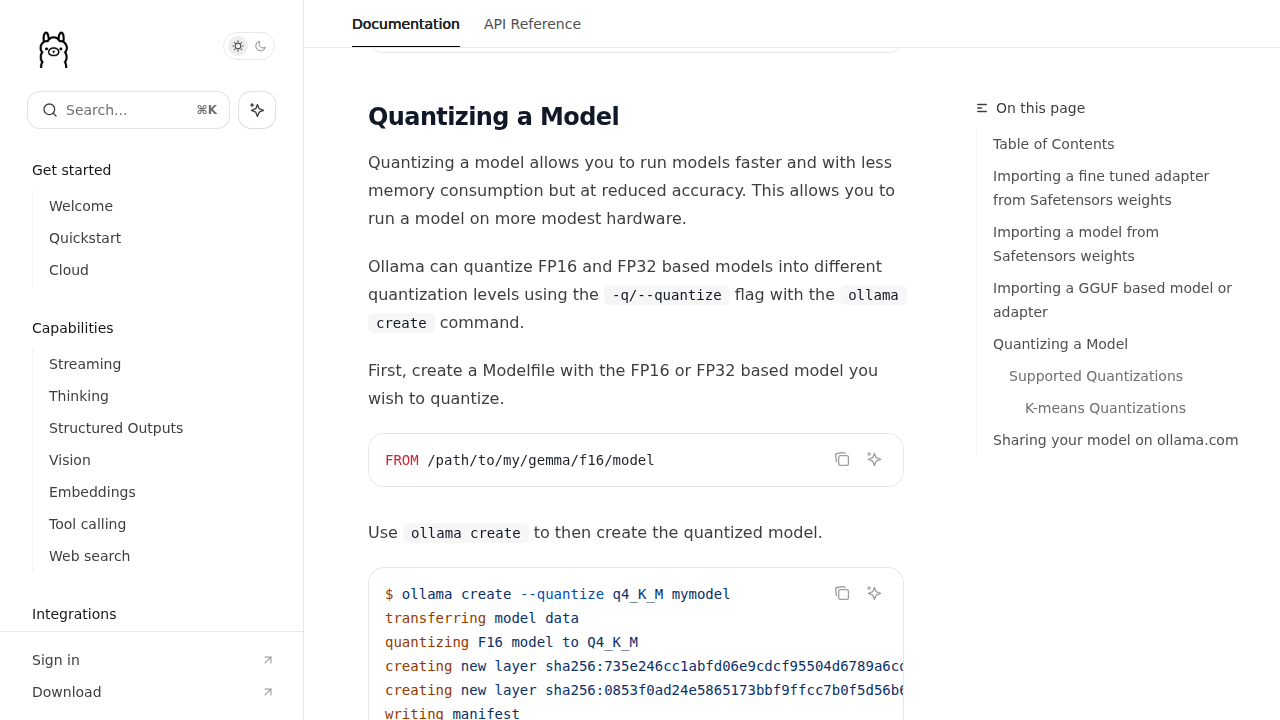
ollama create --quantize q4_K_M. Источник: Ollama Docs.Но важно не переобещать GGUF лишнего. Он хорош для локального запуска, быстрой проверки гипотезы и команд, которым нужен понятный маршрут от скачивания модели до первого ответа. Это не значит, что GGUF автоматически лучший выбор для любого продакшн-контура. Если ваш следующий шаг — выделенный GPU-сервер с vLLM, баланс требований уже меняется.
GPTQ: когда нужны готовые 4-битные веса под серверный GPU-контур
GPTQ полезно читать не как модное слово, а как конкретный пост-тренировочный метод. В актуальной документации Transformers проект GPT-QModel описан так: веса квантизируются до int4, а во время инференса восстанавливаются до fp16 «на лету». Отсюда и главный практический смысл GPTQ: сильная экономия памяти без полного разрыва с GPU-контуром, в котором вы уже живёте.
Есть ещё одна деталь, которую легко пропустить, если читать старые гайды. В свежей документации Hugging Face отдельно сказано, что AutoGPTQ больше не поддерживается в Transformers; вместо него актуальным backend считается GPT-QModel. Для evergreen-страницы это не мелочь. Если оставить в тексте старую рекомендацию «ставьте AutoGPTQ и живите спокойно», материал стареет не через год, а прямо сейчас.
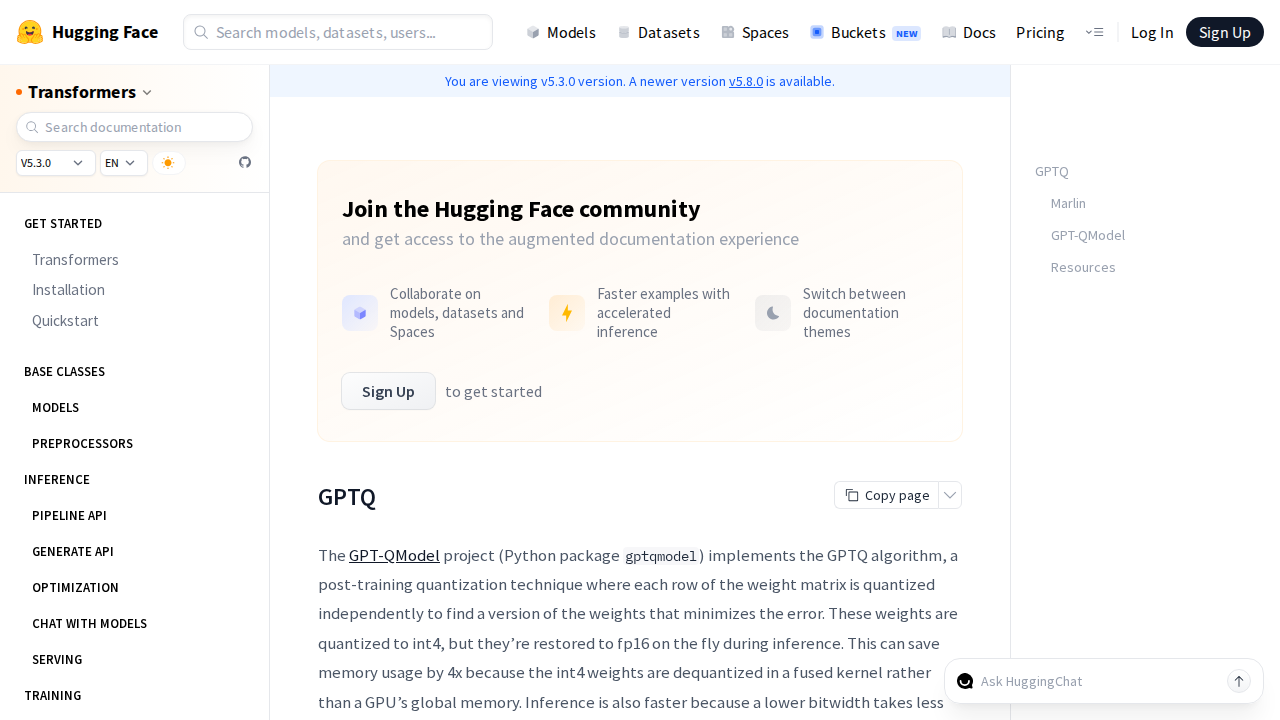
int4-квантование с восстановлением в fp16 во время инференса, а AutoGPTQ уже отмечен как неактуальный путь. Источник: Hugging Face Transformers.Где GPTQ уместен на практике? Там, где у вас уже есть серверный GPU-контур, готовые заранее квантованные веса и не хочется возвращаться в локальный стек ради одного формата файла. Для части команд это самый прагматичный путь: берёте модель, у которой уже есть рабочий GPTQ-вариант, проверяете совместимость с рантаймом и не изобретаете свой конвейер квантизации с нуля.
AWQ: когда важнее работа с рантаймом, чем с файлом
AWQ полезно ставить рядом с GPTQ, а не напротив него. В документации Transformers AWQ описан как Activation-aware Weight Quantization: метод сохраняет небольшую долю наиболее важных весов и сжимает модель до 4 бит с минимальной деградацией качества. Это не обещание чуда. Это более узкое обещание: если нужная модель уже доступна в AWQ, вы получаете понятный 4-битный путь для инференса без ухода в GGUF-контур.
Для серверного стека это часто удобнее, чем спорить, «что лучше по определению». В актуальной документации vLLM список поддерживаемых квантованных форматов включает и AutoAWQ, и GGUF, и GPTQModel. А документация TGI отдельно говорит, что AWQ и GPTQ поддерживаются, но для них нужны уже подготовленные веса. Иными словами, выбирать приходится не между «хорошим» и «плохим», а между совместимыми путями внутри конкретного рантайма.
Если упростить до рабочего правила, оно звучит так. Для локального старта — смотрите на GGUF. Для серверного 4-битного инференса — сначала проверяйте, что ваш рантайм и нужная модель нормально живут в AWQ или GPTQ. Только потом выбирайте формат. Не наоборот.
Где команды теряют время зря
Самая дорогая ошибка — путать разные уровни стека.
- Формат файла и метод квантизации — не одно и то же. GGUF — контейнер и способ упаковки модели для определённых рантаймов. GPTQ и AWQ — методы квантизации, которые потом должны ещё совпасть с тем, чем вы модель обслуживаете.
- Совместимость рантайма важнее красивого названия. То, что модель есть в AWQ или GPTQ, ещё не значит, что ваш конкретный стек, версия рантайма и железо дадут беспроблемный запуск.
- Экономия на весах не равна экономии на всём инференсе. KV-cache, контекст, batch и latency никуда не исчезают. Иногда команда выигрывает десятки гигабайт на весах, а упирается в память уже на длинном контексте.
- Нельзя слепо тащить старые инструкции. Документация по GPTQ и AWQ меняется быстрее, чем evergreen-гайды. Проверять надо не только формат, но и жив ли тот backend, на который ссылается статья.
Как выбрать без мифов и без зигзагов
Если вам нужен короткий и честный маршрут, он такой.
Сначала ответьте, где модель будет жить через месяц, а не через час. На ноутбуке разработчика? На Mac команды? На выделенном GPU-сервере? В TGI-контуре? Ответ на этот вопрос отсечёт половину вариантов раньше, чем вы откроете первый benchmark.
Потом проверьте, что поддерживает ваш рантайм сегодня, а не полгода назад. Для локального стека это обычно быстро приводит к GGUF. Для серверного стека — к AWQ или GPTQ, если нужные веса и железо уже совместимы с выбранным рантаймом. Если не совместимы, не надо героизма. Формат, который запускается стабильно, почти всегда выгоднее формата, который красиво выглядит в чужом посте, но ломает ваше развёртывание.
И только после этого имеет смысл спорить о тонкостях: какой именно квантизатор даёт лучшее качество на вашей модели, стоит ли уходить в 4 бита или хватит 8, нужна ли вам вообще агрессивная квантизация на текущем объёме нагрузки. До этого этапа спор о «лучшем формате» обычно бесполезен.
Итог
Если убрать маркетинговый шум, картина довольно земная. GGUF — рабочий старт для локального запуска и экспериментов через Ollama или llama.cpp. GPTQ — практичный путь к готовым 4-битным весам в серверном GPU-контуре, особенно если ваш стек уже опирается на Transformers, TGI или vLLM. AWQ — соседний серверный вариант, который стоит проверять первым там, где рантайм и модель уже поддерживают его без боли.
Главное — не искать универсального победителя. Побеждает не формат сам по себе. Побеждает стек, который помещается в ваше железо, не ломает рантайм и остаётся понятным команде через месяц после запуска.
Источники и дата проверки
Формулировки про GGUF, GPTQ, AWQ, поддержку рантаймов и рабочие сценарии проверены 6 мая 2026 года по официальной документации:
- Ollama Docs: Importing a Model — импорт GGUF, квантизация через
ollama create --quantize, поддерживаемые уровни вродеq4_K_M. - llama.cpp — требования к формату GGUF, локальный инференс на Apple Silicon и других типах железа.
- Hugging Face Transformers: GPTQ — GPT-QModel,
int4с восстановлением вfp16во время инференса, отказ от AutoGPTQ как основного пути. - Hugging Face Transformers: AWQ — определение AWQ и поддержка загрузки AWQ-моделей в Transformers.
- Hugging Face TGI: Quantization — поддержка GPTQ и AWQ, требование заранее квантованных весов.
- vLLM: Quantization — актуальный список поддерживаемых квантованных форматов и оговорка, что hardware-матрица со временем меняется.



