XCENA: почему AI-инференс упирается в память
XCENA подняла $135 млн при оценке $570 млн. Инвесторская ставка проста: в AI-инференсе дорого не только считать, но и гонять данные между памятью, CPU и GPU.

По состоянию на 29 мая 2026 года XCENA AI-инференс подаёт через простой, но неудобный для рынка тезис: узкое место всё чаще смещается от самих GPU к перемещению данных между памятью, CPU и ускорителями. На этом тезисе южнокорейско-американский стартап поднял $135 млн Series B при оценке $570 млн, а общий объём привлечённых средств достиг $185 млн.
Для рынка это важнее, чем ещё одна новость о чиповом стартапе. Когда инференс становится повседневной нагрузкой, деньги и задержка уходят не только на матричные операции на GPU. Свой счёт выставляют передача данных, подготовка запросов, кеши, векторный поиск и обратные поездки между слоями сервера.
XCENA пытается занять именно этот слой: вместо лобовой замены NVIDIA компания выносит часть операций, завязанных на память, ближе к DRAM. Поэтому эта история соседствует с поиском отдельных чипов для inference, но не сводится к гонке «кто сделает GPU быстрее».
Почему память стала проблемой для AI-инференса
В типичном LLM-запросе данные не лежат спокойно в одном месте. Запрос проходит предварительную обработку, обращается к памяти, уходит на ускоритель, возвращается обратно и повторяет этот цикл по мере генерации токенов. Чем больше контекст, кеши, retrieval и служебная логика вокруг модели, тем заметнее стоимость движения данных.
В обучении моделей внимание обычно забирают GPU и HBM. В инференсе картина шире: рядом с самой моделью живут векторные базы, графовые связи, ETL, кеширование и сортировки. Ускоритель может простаивать из-за долгой поездки данных туда и обратно.
Отсюда появляется инвесторская логика. Если рынок уже готов платить за дорогие GPU-кластеры, он будет искать всё, что снижает стоимость запроса и повышает загрузку существующих ускорителей. Рядом с этим остаётся базовый слой GPU-инфраструктуры: мы отдельно разбирали, почему GPU остаются базовым слоем AI-инфраструктуры даже на фоне новых специализированных чипов.
Что делает XCENA и MX1
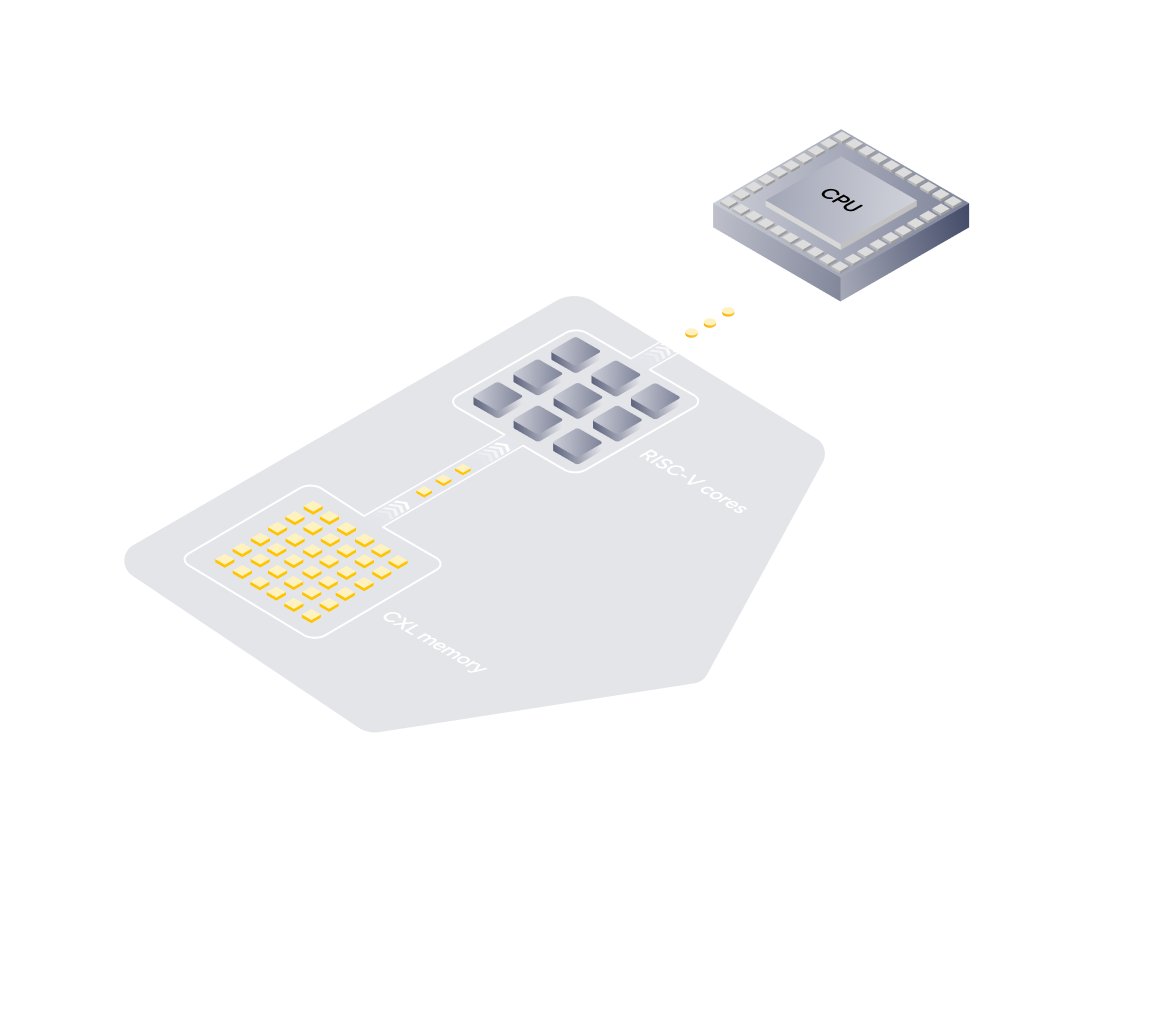
XCENA строит CXL computational memory: память с вычислительным блоком, который выполняет часть параллельных операций рядом с данными. На официальной странице Computational Memory компания пишет, что устройство поддерживает CXL 3.0, подключает четыре канала DDR5 DIMM по 256 ГБ и расширяет основную память до 1 ТБ без увеличения числа memory channels CPU. Там же заявлена пропускная способность до 128 ГБ/с через PCIe Gen6.
Главное в этом подходе - архитектура: CXL memory, near data processing, многоядерный процессор и программный слой для выноса операций ближе к данным. В презентации XCENA для Future of Memory and Storage 2025 MX1 описан как CXL memory + data processing с тысячами кастомных RISC-V-ядер, vector engine и SSD-backed CXL expansion.
По данным самой XCENA, FPGA-прототип в database acceleration показал сокращение времени обработки запросов на 46% относительно серверных CPU, а потенциальный выигрыш в ASIC может доходить до 95% на TPC-H. Это сильная вендорская цифра. Её стоит читать как заявленный ориентир, а не как независимый benchmark для любого LLM-кластера.
Где это может пригодиться
У XCENA есть понятный набор задач, где перемещение данных часто дороже самой операции. На официальной странице компания называет LLM vector databases, scale-out databases и graph databases. Список выглядит осмысленно: все три сценария любят большой объём памяти, параллельный обход данных и много мелких операций.
| Сценарий | Почему память важна | Что обещает подход XCENA |
|---|---|---|
| LLM vector databases | Поиск по эмбеддингам и retrieval держатся на больших массивах данных. | Ускорять операции рядом с памятью, не гоняя весь поток через CPU. |
| Scale-out databases | ETL, Spark, Databricks и Snowflake-подобные нагрузки часто масштабируются числом серверов. | Вынести часть query execution в computational memory и сократить лишнее движение данных. |
| Graph databases | Графовые алгоритмы много ходят по связям и указателям. | Использовать много небольших ядер с архитектурой, заточенной под обход памяти. |
Для LLM практический выигрыш ближе к обслуживающей инфраструктуре, чем к самой генерации токена внутри GPU: vector DB, retrieval, preprocessing, data orchestration, кеши и аналитика вокруг запросов. Похожий смысл есть и в софтверной ветке оптимизаций: память LLM и KV-cache можно оптимизировать не только железом.
Почему инвесторы поверили именно сейчас
TechCrunch связывает интерес к XCENA с ростом стоимости AI-инфраструктуры и сдвигом к memory-centric architectures. У компании удачный набор сигналов для такого момента: основатели из Samsung и SK Hynix, понятная привязка к CXL, конкретный продукт MX1 и рынок, который уже обсуждает стоимость ежедневного инференса рядом с обучением frontier-моделей.
CEO Jin Kim основал XCENA в 2022 году вместе с CTO Dohun Kim и CPO Harry Juhyun Kim. Все трое, по данным TechCrunch, пришли из Samsung и SK Hynix. Для стартапа в памяти это важная биография: инвесторы покупают идею вместе с шансом, что команда понимает реальную цепочку памяти, контроллеров, производственных ограничений и enterprise-продаж.
Есть и конкурентный фон. TechCrunch называет среди близких игроков Astera Labs и Marvell. Отличие XCENA в её подаче - вычисления прямо в слое памяти. В статье TechCrunch Kim отдельно говорит о тысячах ядер как о части дифференциации. Это не доказывает победу, но объясняет, почему раунд выглядит как ставка на архитектуру, а не на очередную плату расширения.
Что пока не доказано
Сдерживающая часть здесь обязательна. XCENA не показала публично, что MX1 уже снижает стоимость крупного LLM-инференса в облаке на промышленных объёмах. Заявленные цифры по TPC-H и database acceleration полезны, но для реальных RAG, vector DB, long-context и enterprise-нагрузок всё равно нужна отдельная проверка.
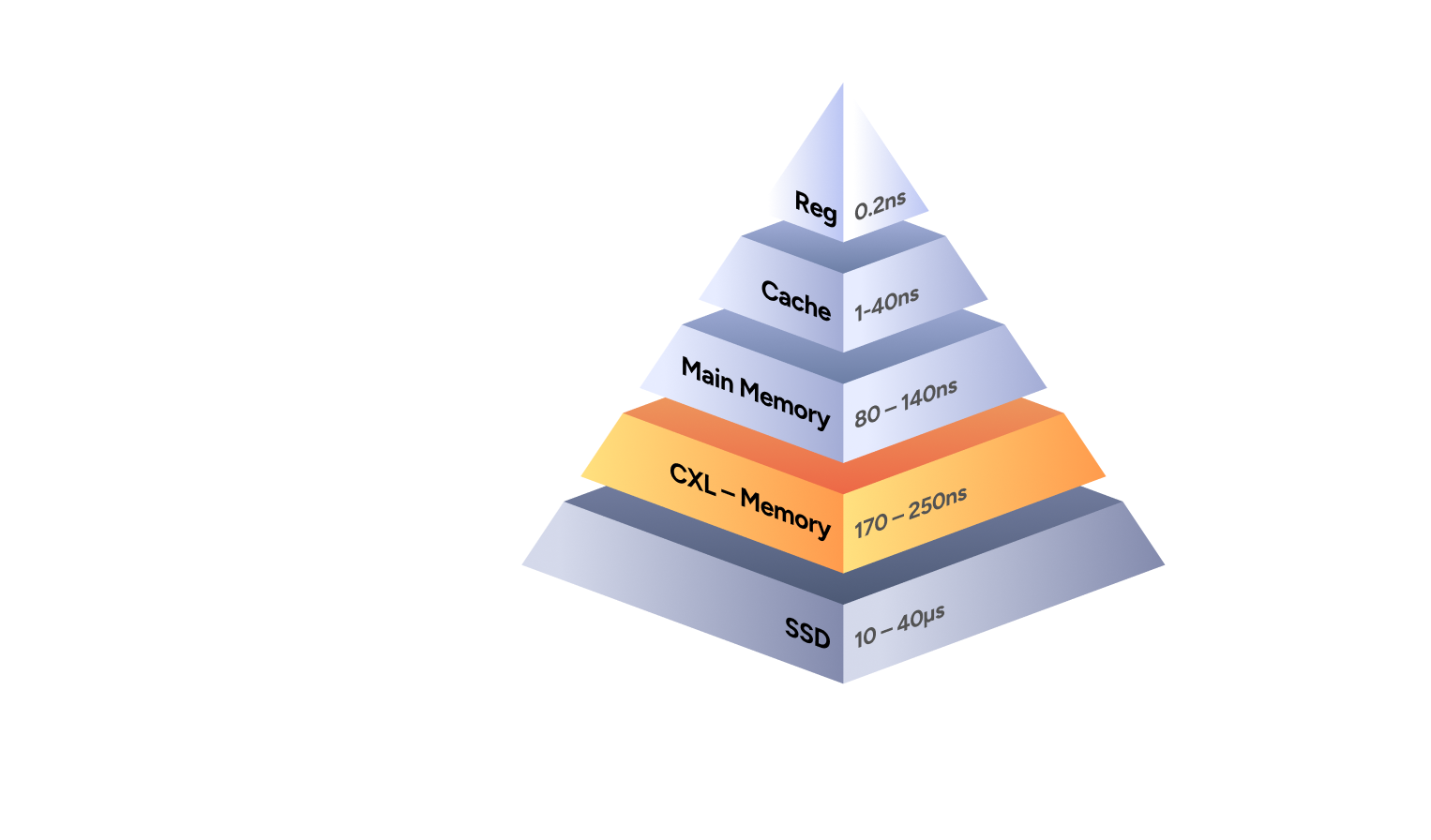
CXL memory также имеет пределы. На собственной схеме XCENA она находится ниже main memory по задержке и выше SSD. Это расширяет архитектурные возможности, но не делает CXL памятью уровня HBM. Поэтому разумная роль MX1 - вынос и ускорение memory-heavy участков, без обещаний «убить GPU».
Есть и программный риск. Чтобы near-memory compute стал полезен, разработчикам нужны драйверы, runtime, библиотеки и понятный путь внедрения. На странице HW-SW co-optimized architecture XCENA говорит о многоуровневых API и инструментах, но рынок всё равно будет проверять, насколько это удобно для существующих Spark, Presto, vector DB и LLM-инфраструктуры.
Что это значит для рынка ИИ-инфраструктуры
История XCENA хорошо показывает, как меняется разговор об AI-инфраструктуре. Ещё недавно весь фокус был на том, где достать GPU. Сейчас всё чаще обсуждают соседние узкие места: память, сеть, хранение, питание, охлаждение, orchestration и стоимость одного запроса.
Для русскоязычного технического читателя главный вывод практичный. Если вы считаете экономику LLM-продукта, смотрите не только на цену GPU-часа. Смотрите на то, где живут данные, как устроен retrieval, сколько раз запрос пересекает границы CPU/GPU/память, где расположен кеш и какие операции можно вынести ближе к данным.
XCENA пока не доказала, что станет стандартом. Но раунд на $135 млн показывает: инвесторы уже ищут следующий слой после чистой GPU-гонки. В инференсе победит не самый громкий чип, а связка железа и софта, которая уменьшит пустое движение данных и даст больше полезной работы на каждый ватт, доллар и миллисекунду.



