NVIDIA Blackwell: что меняют B200 и GB200 для ИИ-инфраструктуры
Blackwell важен не только новым GPU. Объясняем, что дают B200 и GB200 NVL72, где у них преимущество над H100 и какие ограничения остаются у датацентров.

Проверено 11 мая 2026 года. NVIDIA Blackwell уже нельзя описывать как просто "следующее поколение GPU после Hopper". К 2026 году это скорее платформа из трёх уровней: отдельный B200, системный DGX B200 и стоечная система GB200 NVL72. Именно эта смена масштаба объясняет, почему разговор о Blackwell быстро выходит за пределы FLOPS и упирается в питание, охлаждение, сеть и экономику целой стойки.
Если упростить до одного тезиса, Blackwell важен не тем, что он "быстрее H100" вообще. Он меняет плотность памяти, пропускную способность внутри узла и размер NVLink-домена. Это даёт прямую выгоду тем, кто обучает крупные модели или продаёт инференс в больших объёмах. Но одновременно поднимает ставку на всё, что окружает GPU: силовую часть, жидкостное охлаждение, сетевые карты, BMC и управляемость датацентра.
Blackwell теперь продаётся как платформа, а не как одиночный ускоритель
На уровне самого ускорителя ключевым блоком Blackwell остаётся B200. В актуальной документации NVIDIA для HGX AI Factory у него указаны 180 ГБ HBM3e на GPU и пропускная способность памяти до 8 ТБ/с. Для сравнения, у H100 SXM - 80 ГБ HBM3 и 3,35 ТБ/с. Разница важна не только для красивой таблицы: в реальной работе она определяет, сколько модели помещается на один ускоритель и насколько болезненным будет меж-GPU обмен.
Следующий уровень - DGX B200. Это уже не просто восемь GPU в коробке, а полноценный системный блок для AI-фабрики: 8 GPU Blackwell, суммарно 1 440 ГБ памяти HBM3e, два NVSwitch пятого поколения с общей полосой 14,4 ТБ/с, восемь ConnectX-7, две BlueField-3 DPU и собственный BMC-контур. У NVIDIA этот узел прямо продаётся как базовый строительный блок для корпоративной AI-инфраструктуры, а не как лабораторный сервер для единичных экспериментов.
Ещё важнее то, что Blackwell масштабируется не только "внутри сервера", но и до уровня стойки. GB200 NVL72 объединяет 36 Grace CPU и 72 Blackwell GPU в одну жидкостно охлаждаемую стоечную систему. В этой конфигурации NVLink-домен уже не ограничен восемью ускорителями, как раньше в HGX H100/H200, а вырастает до 72 GPU. Это и есть главный архитектурный сдвиг: NVIDIA продвигает Blackwell не как новый чип для старой стойки, а как основу для новых стоек и новых AI-фабрик.

Что реально изменилось по сравнению с H100
| Параметр | H100 SXM | Blackwell | Почему это важно |
|---|---|---|---|
| Память на GPU | 80 ГБ HBM3 | B200 SXM: 180 ГБ HBM3e | Крупные модели реже приходится дробить на большее число ускорителей |
| Пропускная способность памяти | 3,35 ТБ/с | B200 SXM: до 8 ТБ/с | Меньше потерь в задачах, где всё упирается в память и подачу весов |
| NVLink между GPU | 900 ГБ/с на GPU | 1,8 ТБ/с на GPU | Меньше потерь на обмене между ускорителями внутри узла и стойки |
| Размер одного NVLink-домена | До 8 GPU в HGX H100/H200 | До 72 GPU в GB200 NVL72 | Blackwell переносит масштабирование с уровня сервера на уровень стойки |
Практический эффект здесь виден на моделях класса 70B. В FP16 только веса такой модели занимают порядка 140 ГБ. H100 с 80 ГБ памяти такую конфигурацию целиком на один GPU не помещает. B200 с 180 ГБ уже помещает. Даже если считать не только веса, а ещё KV-кэш и служебный запас, сам факт большего объёма памяти резко уменьшает давление на шардирование, межпроцессный обмен и сетевую топологию.
Но память - только половина истории. Вторая половина - связность. В H100 главный масштаб происходил на уровне узла с восемью GPU, после чего начинался привычный разговор про InfiniBand, Ethernet и штрафы на межузловую коммуникацию. Blackwell расширяет сам домен NVLink. Это заметно не только в обучении, но и в инференсе для длинных контекстов, MoE-моделей и сценариев, где модель или KV-кэш перестают нормально помещаться в старую восьми-GPU конфигурацию.
Где у Blackwell появляется экономическое преимущество
Экономика Blackwell начинается не с прайс-листа на сам чип, а с того, сколько полезной работы вы получаете на один узел, одну стойку и один киловатт. Именно поэтому в материалах NVIDIA всё чаще фигурируют не только FLOPS, но и стоимость токена, пропускная способность на стойку и производительность при заданном энергобюджете.
Первый источник преимущества - плотность памяти. Чем больше модели помещается на один ускоритель, тем меньше GPU нужно для одной и той же конфигурации инференса и тем меньше накладные расходы на синхронизацию. Это особенно важно для команд, которые держат в продакшене большие модели с открытыми весами, где цена ошибки считается не в "интересных бенчмарках", а в стоимости каждого запроса.
Второй источник - связность. В пресс-релизе Blackwell от 18 марта 2024 года NVIDIA отдельно подчёркивала 1,8 ТБ/с NVLink на GPU, до 576 GPU в одной конфигурации и до 25-кратного снижения операционной стоимости и энергопотребления LLM-инференса относительно предшественника. Это оценка самого вендора, а не универсальная истина для любого кластера. Но она хорошо показывает, как сама NVIDIA формулирует ценность Blackwell: не "чуть больше TFLOPS", а снижение стоимости инференса при переходе на новый стек GPU, межсоединения и программного слоя.
Третий источник - стоечная упаковка. На странице GB200 NVL72 NVIDIA уже сравнивает систему не с одним H100, а с H100-инфраструктурой целиком: до 30 раз быстрее в реальном инференсе на LLM с триллионным масштабом параметров, до 4 раз быстрее в обучении и до 25 раз эффективнее по энергии. Здесь важна не абсолютная цифра, а логика. Blackwell продают как способ получать больше полезного выхода с одной стойки и того же энергобюджета, а не просто как новый ускоритель для старой архитектуры датацентра.
Независимый сигнал тоже уже есть. В релизе MLPerf Inference v5.0 MLCommons прямо перечисляет NVIDIA B200 и NVIDIA GB200 среди новых процессоров этого раунда. Это ещё не ответ на вопрос о вашей личной окупаемости, но это уже стадия после "бумажного анонса". Blackwell вошёл в цикл открытых и воспроизводимых инфраструктурных бенчмарков, а значит разговор перешёл из маркетинга в операционную плоскость.
Почему Blackwell быстро упирается не только в GPU
Самая распространённая ошибка в разговорах про Blackwell - смотреть на него как на замену одной карты на другую. На практике рост плотности вычислений почти мгновенно превращается в требования ко всей стойке. DGX B200 в пользовательской документации указан как система с потреблением до 14,3 кВт, шестью блоками питания по 3,3 кВт, 1 550 CFM воздушного потока и BMC-контуром для внеполосного управления. Это уже уровень, где вопросы электрики, охлаждения и мониторинга нельзя считать второстепенными.
Для GB200 NVL72 ставка ещё выше. В документации NVIDIA для DGX GB rack scale systems говорится о примерно 120 кВт на стойку, жидкостном охлаждении вычислительных модулей, NVLink-коммутаторов, силовых полок и отдельной управляющей сети через верхние стоечные Ethernet-коммутаторы. Иными словами, Blackwell не убирает инфраструктурные узкие места, а поднимает их на новый уровень. Если в эпоху H100 многие спорили прежде всего про доступность самих GPU, то в эпоху GB200 приходится обсуждать уже всю стойку целиком.
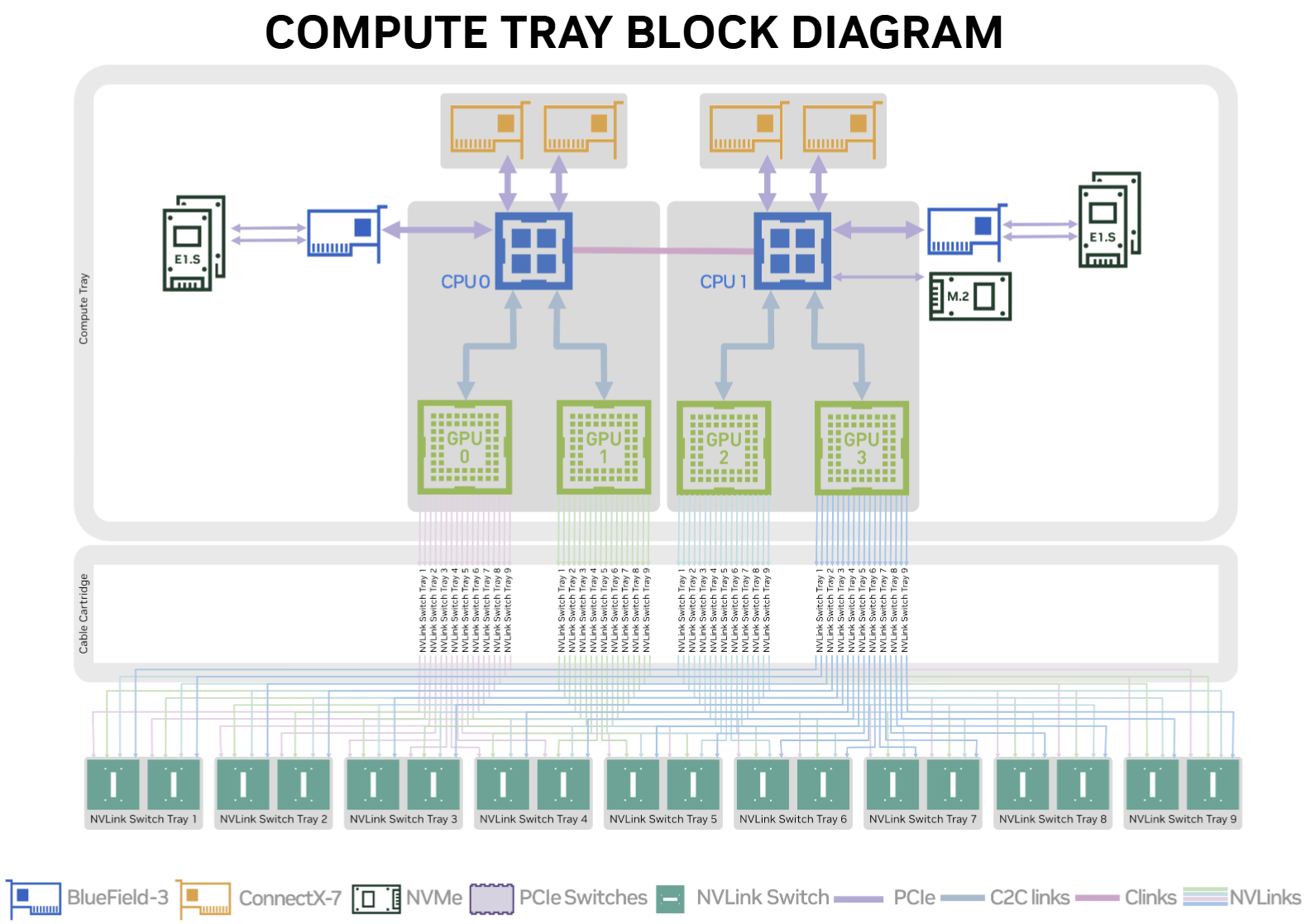
Отсюда и неприятный, но полезный вывод. Blackwell действительно даёт более высокую вычислительную плотность. Но выигрыш появляется только там, где инфраструктура умеет эту плотность переварить: по питанию, по охлаждению, по RDMA-сети, по запасу в стойках и по обслуживанию. И именно здесь Blackwell пересекается с соседними сюжетами про дефицит PMIC и BMC для AI-серверов и про то, как hyperscalers перестраивают сами датацентры, а не только закупают очередное поколение GPU.
Когда Blackwell нужен, а когда можно не спешить
Blackwell особенно логичен в трёх сценариях. Первый - обучение самых крупных моделей и большие MoE-конфигурации, где выигрыш от более широкой памяти и большего NVLink-домена масштабируется на тысячи GPU. Второй - массовый инференс, где стоимость токена и плотность на стойку важнее, чем условная цена одной карты. Третий - корпоративные AI-фабрики, которые строятся не на один эксперимент, а как постоянная производственная инфраструктура.
Во многих других случаях спешка не обязательна. Если ваши модели уже хорошо помещаются на H100/H200, нагрузка не упирается в межузловую коммуникацию, а собственный датацентр не готов к более жёстким требованиям по питанию и охлаждению, Blackwell не даст магической окупаемости только потому, что он новее. Для части команд более разумным вариантом останется аренда Blackwell в облаке или отсрочка до следующего цикла обновления стойки.
Это важно и для архитектурного выбора вокруг конкурентов. Материал про TPU в дата-центрах клиентов показывает, что рынок уже спорит не о "лучшем чипе вообще", а о полной системе поставки вычислений. На этом фоне Blackwell силён там, где нужен зрелый CUDA-стек и плотная стоечная интеграция. Но он не отменяет старое правило: выигрыш даёт вся платформа, а не один логотип на ускорителе.
Главный вывод
NVIDIA Blackwell - это не просто ответ на H100 в терминах ещё большей производительности. Это переход от эпохи "сильного отдельного GPU" к эпохе "сильной стойки". B200 даёт больше памяти и большую полосу на один ускоритель. DGX B200 превращает это в системный узел. GB200 NVL72 переносит масштабирование на уровень стоечного NVLink-домена.
Именно поэтому экономическое преимущество Blackwell над Hopper появляется не в любой нагрузке, а там, где действительно важны память, меж-GPU связность и плотность инференса на стойку. А главный риск Blackwell тоже очевиден: вместе с GPU-выигрышем растут требования к питанию, охлаждению, сети и всей серверной обвязке. В 2026 году это уже не побочный эффект, а центральная часть разговора про AI-инфраструктуру.
Источники и дата проверки
Факты, спецификации и системные требования в этом материале проверены 11 мая 2026 года по следующим источникам:
- NVIDIA Blackwell Architecture
- NVIDIA Newsroom: NVIDIA Blackwell Platform Arrives to Power a New Era of Computing
- NVIDIA H100 GPU
- NVIDIA HGX AI Factory: Components
- NVIDIA DGX B200
- NVIDIA DGX B200 User Guide
- NVIDIA GB200 NVL72
- NVIDIA DGX GB Rack Scale Systems User Guide: Hardware
- NVIDIA GB200 NVL Multi-Node Tuning Guide
- MLCommons: MLPerf Inference v5.0 Results