Google TurboQuant: алгоритм сжимает память LLM в 6 раз без потери качества
Google Research представила TurboQuant — алгоритм сжатия KV-кэша до 3 бит, который уменьшает память LLM в 6 раз и ускоряет attention в 8 раз. Без потери качества.
Google Research представила TurboQuant — алгоритм сжатия KV-кэша, который уменьшает потребление памяти больших языковых моделей в 6 раз и ускоряет вычисление attention в 8 раз на GPU H100. Качество ответов при этом не страдает — ни в одном из бенчмарков.
CEO Cloudflare Мэттью Принс назвал TurboQuant «моментом DeepSeek для Google». Как DeepSeek показал, что мощные модели можно обучать дёшево, так TurboQuant показывает, что инференс (самая затратная часть работы LLM в продакшене) можно удешевить программным путём. Алгоритм будет представлен на конференции ICLR 2026 в Рио-де-Жанейро (данные от 25 марта 2026 года).
KV-кэш: главное узкое место современных LLM
Когда языковая модель генерирует текст, она хранит промежуточные вычисления в key-value кэше — «шпаргалке», которая избавляет от повторных расчётов на каждом шаге. Без неё модели пришлось бы пересчитывать весь контекст при генерации каждого нового токена.
Проблема в масштабе. По мере роста контекстного окна (у современных моделей — до сотен тысяч токенов) KV-кэш разрастается и занимает основную часть GPU-памяти. Для длинных документов или многошаговых агентных задач кэш может потреблять больше VRAM, чем сами веса модели.
Стандартные методы квантизации (уменьшения битности хранения) помогают уменьшить KV-кэш, но обычно вносят собственный «налог на память»: для каждого блока данных нужно хранить поправочные коэффициенты в полной точности. Эти коэффициенты добавляют 1–2 бита на число и частично сводят на нет выигрыш от сжатия. TurboQuant решает именно эту проблему — сжимает кэш до 3 бит на значение без дополнительных поправочных констант.
Как работает TurboQuant
Алгоритм состоит из двух этапов, каждый решает свою задачу.
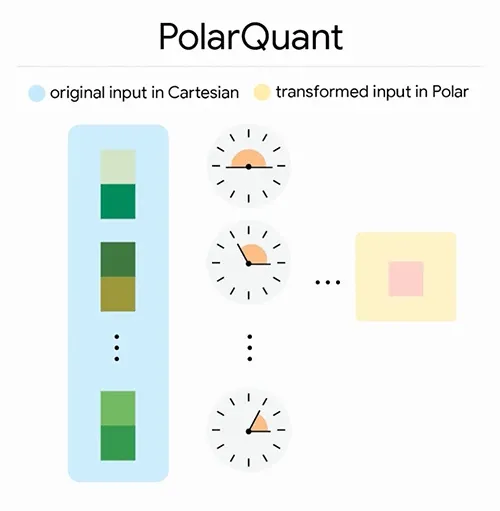
Этап 1: PolarQuant — полярные координаты вместо декартовых
Обычно векторы в моделях хранятся в декартовых координатах (X, Y, Z). PolarQuant переводит их в полярную систему. Google поясняет на бытовом примере: вместо «3 квартала на восток, 4 на север» получается «5 кварталов под углом 37 градусов».
Перед преобразованием данные случайным образом поворачиваются (random rotation). Это упрощает геометрию и позволяет квантовать каждую компоненту по отдельности. После поворота угловые распределения становятся предсказуемыми и концентрированными — данные ложатся на «круговую» сетку с заранее известными границами. Дорогой шаг нормализации данных, который требуют обычные квантизаторы, просто не нужен. PolarQuant берёт на себя основной объём сжатия и не требует хранения поправочных коэффициентов.
Этап 2: QJL — однобитовая коррекция ошибок
После PolarQuant остаются мелкие погрешности. Для их устранения Google использует метод Quantized Johnson-Lindenstrauss (QJL), который основан на классической лемме о проекциях — она гарантирует сохранение расстояний между точками при переходе в пространство меньшей размерности.
QJL сводит каждый остаточный вектор к одному биту (+1 или −1) и не требует дополнительной памяти. Комбинация высокоточного запроса с упрощёнными данными кэша позволяет точно вычислить attention score — ту метрику, по которой модель определяет, на какие части входного текста обращать внимание. QJL устраняет систематическое смещение в оценке, а стоит всего 1 бит на вектор.
Результаты тестов: ноль потерь при 6-кратном сжатии
Google протестировала TurboQuant на стандартных бенчмарках длинного контекста: LongBench, Needle In A Haystack, ZeroSCROLLS, RULER и L-Eval. В качестве моделей использовались открытые Gemma и Mistral (Llama-3.1-8B-Instruct также упоминается в статье).
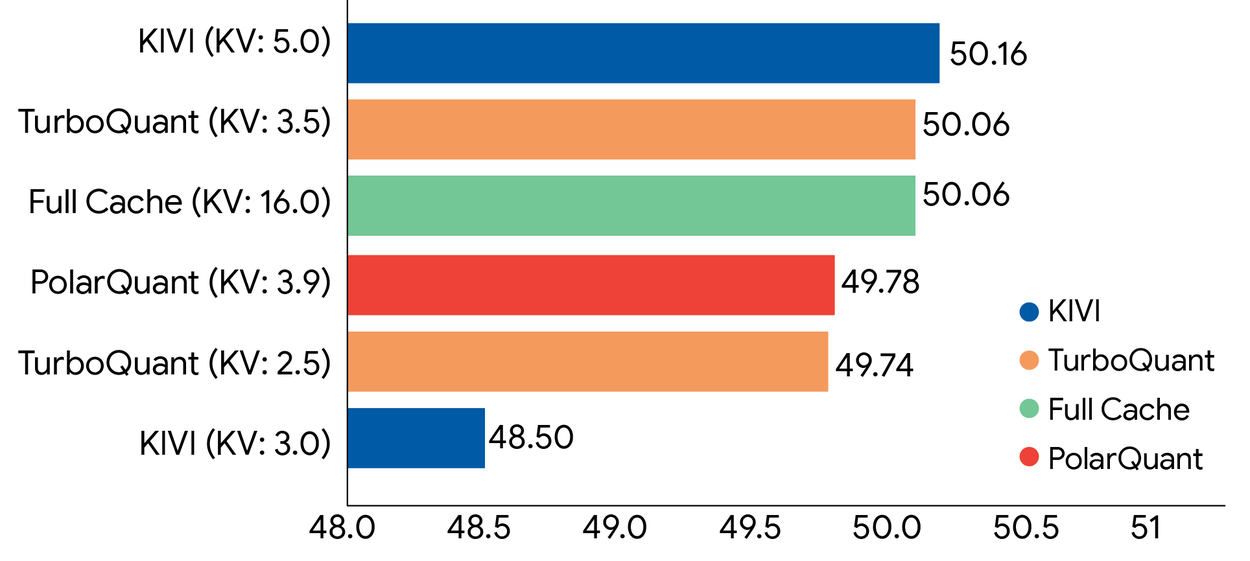
Ключевые цифры:
- Память KV-кэша сократилась в 6 раз (с 32-битных ключей до 3-битных)
- Вычисление attention logits ускорилось в 8 раз (4-битный TurboQuant vs 32-битные ключи на NVIDIA H100)
- Потеря качества — нулевая во всех тестах по сравнению с полноразмерным кэшем
- Не нужно дообучение или файнтюнинг — алгоритм применяется к готовым моделям
На задаче Needle In A Haystack (поиск конкретного факта, спрятанного в длинном тексте) TurboQuant получил идеальные оценки при любой длине контекста. На LongBench, который включает задачи ответов на вопросы, генерацию кода и суммаризацию, TurboQuant сравнялся или превзошёл базовый метод KIVI по всем подзадачам.
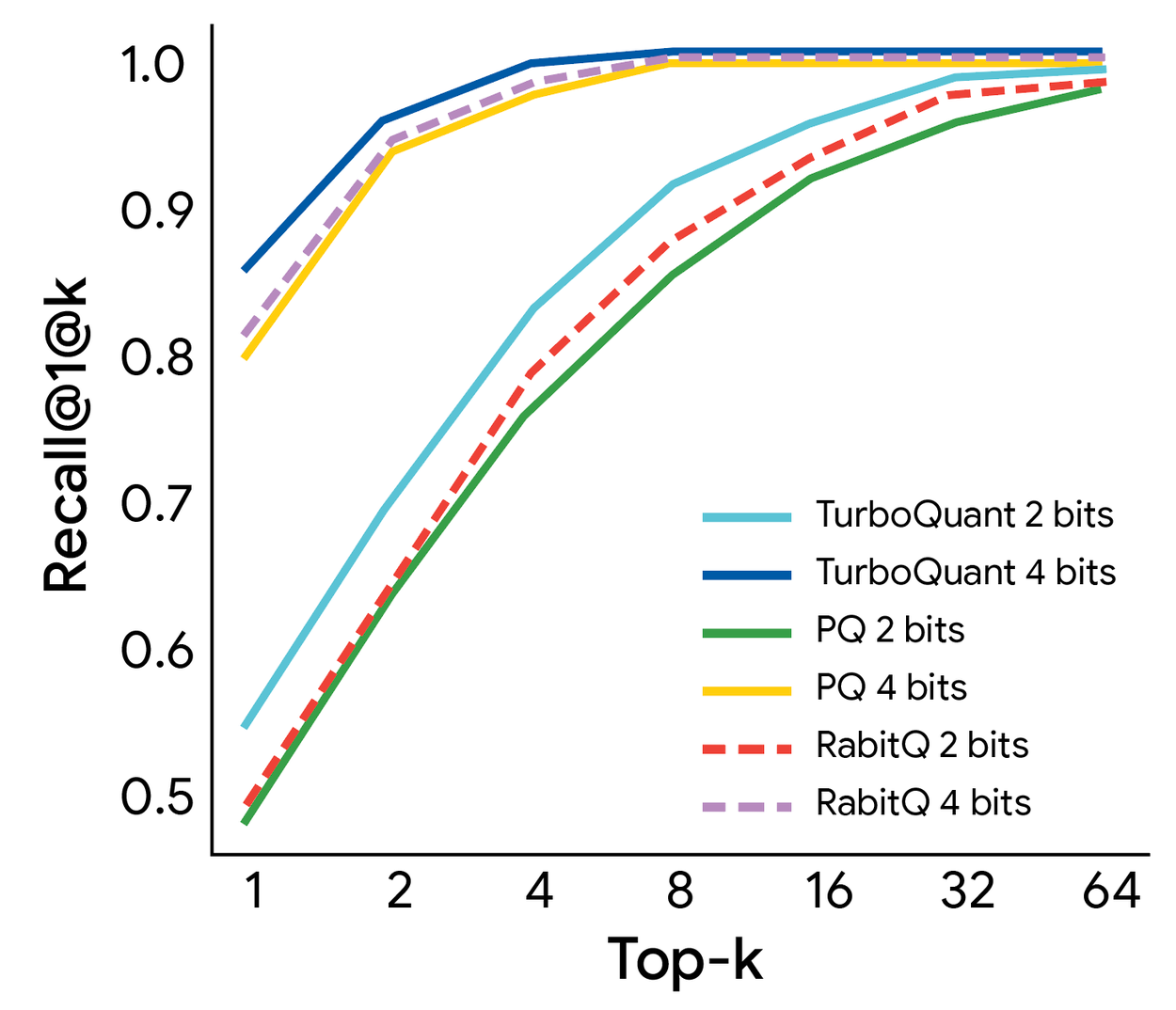
Google также проверила TurboQuant на задачах векторного поиска. На датасете GloVe (200-мерные векторы) алгоритм показал лучший recall, чем Product Quantization и RabbiQ, хотя те используют большие кодовые книги и настраиваются под конкретный датасет. TurboQuant работает «вслепую» — ему не нужно знать данные заранее (data-oblivious).
«Момент DeepSeek» для Google: реакция рынка и отрасли
CEO Cloudflare Мэттью Принс отреагировал одним из первых, написав, что TurboQuant — это «момент DeepSeek для Google». DeepSeek доказал, что для обучения сильных моделей не обязательны тысячи GPU. TurboQuant доказывает то же для инференса: можно обойтись в разы меньшим объёмом памяти.
Рынок отреагировал жёстко. После публикации алгоритма 25 марта акции крупных производителей памяти — Micron, Western Digital, Seagate — заметно просели. Логика инвесторов: если программное сжатие снижает потребность в памяти в 6 раз, спрос на HBM (High Bandwidth Memory) для ИИ-серверов может оказаться ниже прогнозов. Впрочем, многие аналитики напоминают о парадоксе Джевонса: повышение эффективности часто ведёт не к снижению, а к росту потребления — модели станут больше, контексты длиннее, а память всё равно понадобится.
Сообщество: порты за 24 часа
В течение суток после публикации разработчики начали портировать TurboQuant на популярные фреймворки. На GitHub появилась реализация для локального запуска в llama.cpp с Metal-ядрами для Apple Silicon. В MLX (библиотека Apple для машинного обучения) алгоритм протестировали на модели Qwen3.5-35B: при контекстах от 8 500 до 64 000 токенов 2,5-битная квантизация дала 100% совпадение результатов с оригиналом и сокращение KV-кэша почти в 5 раз.
Модель, которая раньше упиралась в потолок VRAM при длинном контексте, теперь может обрабатывать 100 000 токенов на Mac Mini — без отправки данных в облако и без деградации качества.
Практическое значение
Облачные провайдеры могут обслуживать на том же GPU больше запросов или работать с более длинным контекстом. VentureBeat оценивает потенциальное снижение стоимости инференса в 50% и более.
RAG-системы (retrieval-augmented generation) получают возможность расширить контекстное окно без пропорционального увеличения расходов на память. Это важно для корпоративных приложений, работающих с большими внутренними базами документов.
На мобильных устройствах, где память ограничена физически, TurboQuant позволяет запускать более качественные модели локально, без отправки данных в облако.
Есть применение и за пределами LLM: рекомендательные системы, семантический поиск, поисковые движки. Везде, где используется векторный поиск, TurboQuant ускоряет построение индексов и снижает затраты на хранение.
Ограничения
У алгоритма есть ограничения. Пока он протестирован только на открытых моделях: Gemma, Mistral, Llama. Результатов на закрытых системах масштаба GPT-5 или Claude Opus нет. Кроме того, сжимается только KV-кэш — веса модели, активации и другие компоненты остаются за рамками метода.
Реальные реализации в продакшен-системах пока тоже в процессе. Сообщество портировало алгоритм на llama.cpp и MLX за считанные дни, но интеграция в крупные inference-платформы (vLLM, TensorRT-LLM) потребует времени.
Тем не менее для задач с длинным контекстом, где KV-кэш — главное узкое место, 6-кратное сжатие без потери качества меняет расклад. Авторы алгоритма — исследователь Амир Зандие и вице-президент Google Fellow Вахаб Мирокни — представят работу на ICLR 2026 в апреле.



