Rubric-Based GRM для SWE agents: почему pass/fail мало
Разбираем paper Rubric-Based GRM: как рубрики помогают обучать SWE-агентов лучше, чем один pass/fail по unit-тестам.

У SWE-агентов есть неудобная проблема: мы часто учим их по финальному сигналу «тесты прошли» или «тесты не прошли». Для обычного автогрейдера это нормально. Для многошагового агента, который ищет файл, запускает тесты, ошибается, откатывается и снова пробует, такой сигнал слишком грубый.
Свежий препринт Beyond Verifiable Rewards: Rubric-Based GRM for Reinforced Fine-Tuning SWE Agents, отправленный на arXiv 13 марта 2026 года, предлагает другой подход: Rubric-Based GRM для SWE agents. GRM здесь означает Generative Reward Model, то есть модель-награду, которая оценивает не только финальный результат, но и качество промежуточных действий по заранее заданным рубрикам.
По состоянию на 21 апреля 2026 года это исследовательская работа, а не готовая производственная методика. Но в ней хорошо сформулирован сдвиг, который важен для всех, кто строит AI coding agents: итоговый solve rate мало что говорит о том, какие привычки агент усвоил во время обучения.
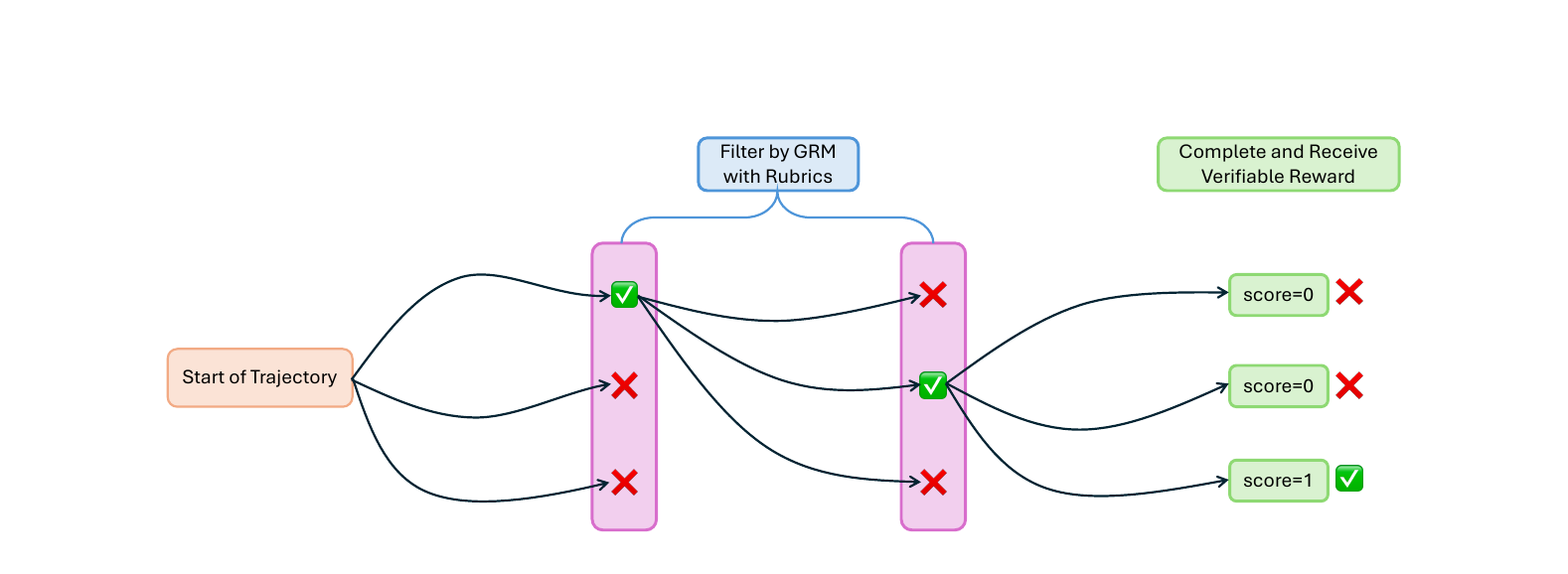
Что предложили авторы
Авторы Jiawei Huang, Qingping Yang, Renjie Zheng и Jiaze Chen работают с постановкой reinforced fine-tuning для SWE-задач. Базовый агент действует в среде OpenHands: может выполнять команды, смотреть файлы, править строки и завершать задачу. В конце среда даёт бинарный verifiable reward: решение прошло тесты или нет.
Rubric-Based GRM добавляют между началом и финалом. На каждом шаге или на отрезке из нескольких шагов агент генерирует несколько кандидатов продолжения. GRM сравнивает их по рубрикам и оставляет тот вариант, который лучше соответствует желаемому поведению. После завершения траектория всё равно попадает в обучающий набор только при финальной награде 1, то есть когда unit-тесты прошли.
В работе использованы четыре рубрики с равным весом 0,25:
- следование рабочему процессу: запуск тестов, воспроизведение бага, проверка гипотез;
- информационная ценность действия: помогает ли шаг продвинуться к решению;
- стратегический взгляд: умеет ли агент связывать факты и планировать следующие шаги;
- контроль ошибок: меньше ли лишних циклов, синтаксических промахов и бесполезных действий.
Это не замена тестов. Скорее фильтр качества до того, как траектория попадёт в RFT-датасет. Смысл в том, чтобы агент учился не только «доходить до зелёной галочки», но и делать это более внятным путём.
Почему pass/fail по тестам мало
Финальная награда хороша тем, что её легко проверить. Unit-тесты не спорят о стиле рассуждений, они просто проходят или падают. Но для SWE-агента это почти всегда поздний сигнал: к моменту проверки агент уже сделал десятки действий, и система не знает, какие из них были полезными.
Paper выделяет две проблемы. Первая: плохой промежуточный паттерн может сам себя исправить. Агент сходил не туда, получил ошибку, поправился и всё-таки решил задачу. Финальный reward равен 1, хотя в траектории были действия, которые лучше не закреплять.
Вторая: полезные промежуточные действия не получают кредита. Агент написал reproduction script, запустил релевантный тест, нашёл файл с корнем проблемы, но финальная правка не прошла. Terminal reward равен 0, и эти удачные шаги теряются вместе со всей траекторией.
На Toolarium мы уже разбирали, почему бенчмарки ИИ-агентов могут давать ложную уверенность. Rubric-Based GRM смотрит на соседнюю часть той же проблемы: оценивать нужно не только итоговую цифру, но и то, каким поведением она получена.
Что получилось на SWE-bench Verified
Эксперименты проводились на seed-OSS-36B. В качестве GRM авторы использовали seed-1.6-thinking. Обучающие задачи взяли из SWE-Gym, SWE-ReBench и SWE-Smith; для теста использовали SWE-bench Verified, набор из 500 human-validated задач из тестового split SWE-bench. Размер RFT-датасета держали на уровне 500 траекторий.
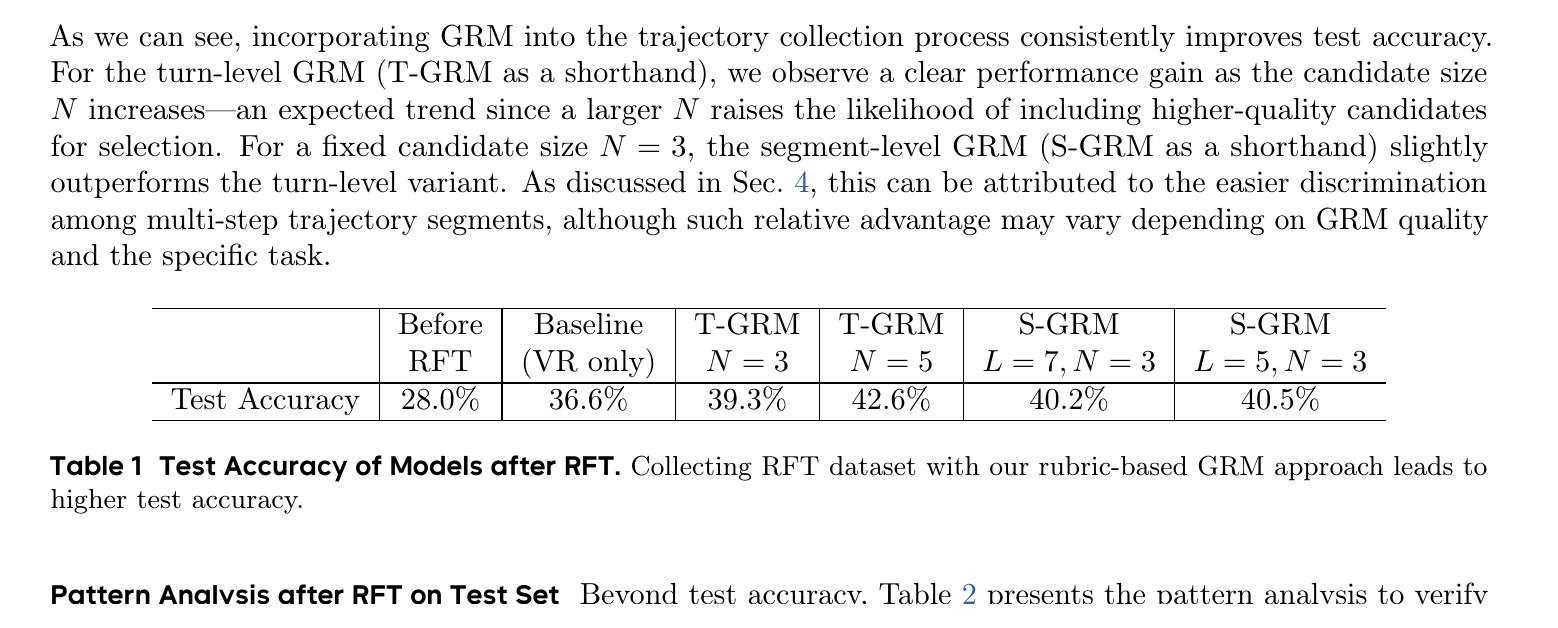
Главная таблица простая: baseline с обычным verifiable reward уже улучшает модель, но GRM-фильтрация даёт больший прирост.
| Вариант после RFT | Test accuracy на SWE-bench Verified | Что менялось |
|---|---|---|
| До RFT | 28,0% | Базовый seed-OSS-36B |
| Baseline, только verifiable reward | 36,6% | Обычная фильтрация по прошедшим тестам |
| Turn-level GRM, N=3 | 39,3% | GRM выбирает действие на уровне шага |
| Turn-level GRM, N=5 | 42,6% | Больше кандидатов для выбора |
| Segment-level GRM, L=7, N=3 | 40,2% | GRM сравнивает отрезки траектории |
| Segment-level GRM, L=5, N=3 | 40,5% | Более частая сегментная фильтрация |
Источник данных: arXiv:2604.16335, таблица 1. Разница между baseline и лучшим вариантом T-GRM N=5 составляет 6 процентных пунктов: 36,6% против 42,6%.
Вторая часть результата интереснее для практиков. GRM снижал долю avoidable errors и сокращал среднее число ходов. В таблице 2 task-level error rate у baseline был 32,7%, а у S-GRM L=5, N=3 - 27,4%. Среднее число ходов снизилось с 35,2 у baseline до 32,0 у T-GRM N=5. Это не только про «модель решила больше задач», но и про то, что траектории стали менее шумными.
Практический вывод для команд
Если команда оценивает AI coding agents, одного solve rate мало. Две системы могут показать похожий итоговый процент, но одна добирается до него через воспроизводимый процесс, а другая через случайные блуждания и удачные догадки. В производственной разработке это разница между помощником и источником новых инцидентов.
Rubric-Based GRM полезен как язык для обсуждения reward design. Команда может явно описать, какие действия агента нужно усиливать: запуск локального теста перед правкой, проверка stack trace, поиск минимального reproduction, отказ от косметических правок. И отдельно описать, что нужно штрафовать: повтор одних и тех же команд, правку без проверки, доступ к несуществующим путям.
Это хорошо стыкуется с материалом про то, как Cursor обучает Composer на реальных пользовательских сигналах. Чем ближе обучение к реальной разработке, тем точнее нужно формулировать reward, чтобы агент не учился обходить метрику. А на уровне отдельного репозитория похожая логика появляется в CLAUDE.md, skills и rulesync: правила проекта тоже задают агенту критерии хорошего поведения, только не через RFT, а через рабочий контекст.
Что ещё видно в свежей подборке
Вокруг reward, evaluation и test-time control сейчас много движения. Две соседние papers из той же research-подборки хорошо показывают общий вектор.
| Paper | Что проверяли | Подтверждённые цифры |
|---|---|---|
| SaFeR-Steer | Многоходовая safety-настройка мультимодальных LLM через synthetic bootstrapping и tutor-in-the-loop GRPO | STEER-SFT: 12 934 диалога, STEER-RL: 2 000, STEER-Bench: 3 227; диалоги на 2-10 ходов |
| Sampling for Quality | Training-free reward-guided decoding через Sequential Monte Carlo | До 54,9% прироста на HumanEval; 87,8% HumanEval и 78,4% MATH500 с Qwen2.5-7B |
Обе работы не про SWE-агентов напрямую, но они показывают тот же сдвиг: исследователи ищут способы давать модели более полезный сигнал, чем один финальный ответ. SaFeR-Steer переносит safety-оценку в многоходовой диалог. Sampling for Quality двигает reward на этап генерации, не меняя веса модели.
Rubric-Based GRM находится между этими подходами. Он не отменяет verifiable reward, но добавляет слой оценки процесса. Для coding agents это особенно естественно: разработка почти никогда не сводится к одному ответу, зато хорошо раскладывается на проверяемые рабочие привычки.
Где ограничения
Главное ограничение - рубрики пока проектируются вручную. Авторы сами пишут, что поиск эффективных критериев и систематическое построение rubric остаются открытой задачей. Для команды это означает дополнительные расходы: кто-то должен описать, что такое хороший процесс решения, и проверить, что GRM действительно оценивает его, а не красивую имитацию.
Второе ограничение - исследовательская среда. OpenHands, SWE-bench Verified и фиксированный набор инструментов удобны для эксперимента, но реальный репозиторий добавляет CI, flaky tests, ревью, секреты, локальные политики и ограничения доступа. Нельзя переносить 42,6% из таблицы как обещание production-эффекта.
Третье - verifier не обязан быть сильнее агента, но он должен уметь отличать полезное поведение. В отдельном эксперименте авторы усилили базовую модель траекториями Claude Opus 4: начальная test accuracy выросла до 48,0%, выше 43% у GRM. Даже тогда T-GRM N=3 дал 50,6%, а baseline с verifiable reward only просел до 46,8%. Это интересный сигнал, но не универсальный закон.
Что стоит вынести
Rubric-Based GRM для SWE agents важен не самой аббревиатурой. Важна идея: обучение coding agents нужно оценивать по поведению внутри траектории, а не только по финальному pass/fail. Если агент решает задачу, но делает это через ошибки, лишние команды и случайные правки, метрика должна это видеть.
Для исследователей это путь к более плотному reward-сигналу. Для команд разработки - напоминание, что критерии качества агента нужно писать так же явно, как тесты и правила репозитория. Иначе агент будет подгонять поведение под то, что проще измерить, а не под то, что реально делает работу безопаснее и быстрее.
Источники и дата проверки
Факты и числа в материале проверены 21 апреля 2026 года по arXiv/PDF: Rubric-Based GRM for Reinforced Fine-Tuning SWE Agents, SaFeR-Steer и Sampling for Quality.



