MetaClaw: ИИ-агент, который учится на ошибках, пока вы на совещании
Исследователи из четырёх университетов представили MetaClaw — фреймворк, который позволяет ИИ-агентам учиться на ошибках и дообучаться через LoRA, пока пользователь на совещании. Kimi-K2.5 с MetaClaw догнал GPT-5.2.
Исследователи из четырёх американских университетов представили фреймворк, который позволяет ИИ-агентам улучшаться в процессе работы. Система проверяет Google Calendar пользователя, чтобы определить, когда запустить обучение, не мешая работе.
ИИ-агенты не учатся после развёртывания
Большинство агентов на базе больших языковых моделей обучаются один раз и дальше работают как есть. Задачи пользователя меняются, рабочие процессы усложняются, а модель стоит на месте. В платформах вроде OpenClaw, где агент обрабатывает задачи из 20+ каналов, статичная модель быстро отстаёт от реальных потребностей.
Группа из UNC-Chapel Hill, Carnegie Mellon, UC Santa Cruz и UC Berkeley предложила MetaClaw — фреймворк непрерывного мета-обучения, который совмещает два механизма: быстрые правила из ошибок и фоновую дообучку весов.
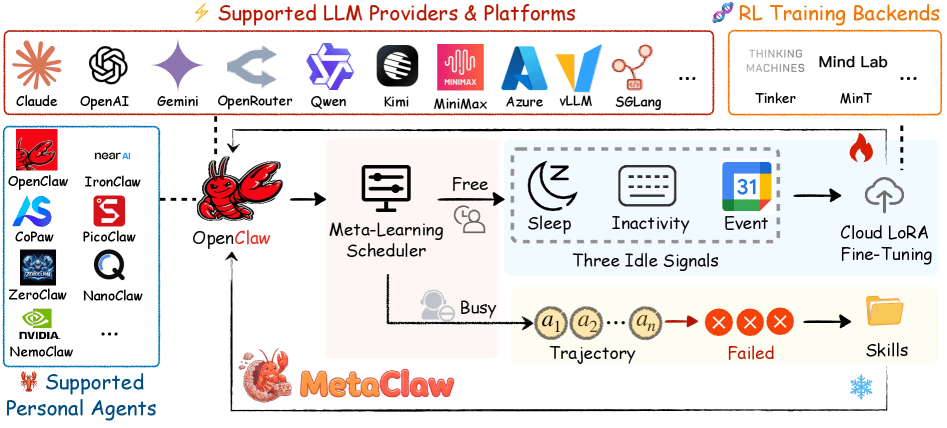
Мгновенные правила из провалов
Когда агент проваливает задачу, отдельная языковая модель (evolver) анализирует неудачное взаимодействие и формулирует компактное поведенческое правило. Правило немедленно добавляется в системный промпт агента и применяется ко всем последующим задачам. Сама модель при этом не меняется, сервис не прерывается.
По данным из статьи, из анализа ошибок чаще всего рождаются три типа правил: корректная нормализация форматов времени, создание бэкапов перед деструктивными файловыми операциями и соблюдение соглашений об именовании. Правила не привязаны к конкретной задаче, поэтому одна ошибка может улучшить работу агента в совершенно других сценариях.
Правила хранятся как Markdown-файлы в директории ~/.metaclaw/skills/. Библиотека навыков растёт автоматически с каждым сеансом. В комплекте идёт банк из 40+ готовых навыков для кодинга, безопасности и агентных задач.
Обучение модели в окнах простоя
Второй механизм обновляет веса модели через reinforcement learning с облачной LoRA-дообучкой. Обновление ненадолго прерывает работу агента, поэтому его нельзя запускать, когда пользователь активен.
MetaClaw решает это с помощью планировщика OMLS (Opportunistic Meta-Learning Scheduler), который следит за тремя сигналами:
- Настроенные часы сна (например, 23:00–07:00)
- Неактивность клавиатуры и мыши на уровне ОС
- События в Google Calendar: если пользователь на совещании, открывается окно для обучения

Если пользователь вернётся посреди обновления, частичный прогресс сохраняется и продолжается в следующее окно.
Система жёстко разделяет данные до и после изменения правил. В обучение попадают только данные, собранные уже с новыми правилами, иначе модель наказывалась бы за ошибки, которые правила уже исправили.
Kimi-K2.5 догнал GPT-5.2
Исследователи тестировали MetaClaw на собственном бенчмарке из 934 вопросов, распределённых по 44 симулированным рабочим дням. Использовались модели GPT-5.2 и Kimi-K2.5.
| Метрика | Kimi-K2.5 (без MetaClaw) | Kimi-K2.5 + MetaClaw | GPT-5.2 baseline |
|---|---|---|---|
| Точность | 21,4% | 40,6% | 41,1% |
| Прирост от правил | — | +32% относительно | — |
| Скорость решения | 1x | 8,25x | — |
| Устойчивость к ошибкам | — | +18,3% | — |
Kimi-K2.5 с MetaClaw практически догнал GPT-5.2 без какого-либо дополнительного обучения на стороне GPT. Слабые модели выигрывают больше: у них больше пробелов в процедурных знаниях, которые библиотека правил заполняет.
Два механизма усиливают друг друга. Улучшенная модель генерирует более информативные ошибки, из которых получаются более точные правила. Те, в свою очередь, дают качественные данные для следующего цикла дообучки.
На отдельном тесте с AutoResearchClaw (автономный пайплайн из 23 шагов: от обзора литературы до готовой статьи) одни только правила без дообучки снизили повторение шагов на 24,8% и количество циклов доработки на 40%.
Техническая архитектура
MetaClaw работает как прозрачный прокси между пользователем и LLM. Локальный GPU не нужен — обучение идёт через облачные сервисы (Tinker, MinT или Weaver) с LoRA. Поддерживает несколько агентных платформ: OpenClaw, CoPaw, IronClaw, NanoClaw и другие.
Три режима работы:
skills_only— только инъекция правил, без дообучки. Самый лёгкий, без GPU.rl— правила + непрерывное RL-обучение. Тренировка сразу при заполнении батча.madmax(по умолчанию) — правила + RL + планировщик. Обучение только в окнах простоя.
Установка занимает две команды:
metaclaw setup # интерактивный мастер настройки
metaclaw start # запуск в режиме madmaxВерсия 0.4.0 (от 25 марта 2026) добавила долгосрочную память: MetaClaw запоминает факты, предпочтения и контекст проектов между сессиями.
Код открыт под лицензией MIT. Статья (arXiv:2603.17187) заняла первое место в HuggingFace Daily Papers 18 марта.
Ограничения
Авторы сами указывают, что бенчмарк — симуляция, а не реальные пользовательские сессии. Цифры нельзя напрямую переносить на продакшн. Обнаружение окон простоя зависит от настроек: если календарь пустой, а мышь не трогать, MetaClaw может не найти подходящего момента для обучения.
MetaClaw пока заточен под текстовые (CLI) задачи агентов. Мультимодальные сценарии — вопрос будущих версий.
Читайте также
- Hyperagents: ИИ, который улучшает сам механизм самосовершенствования — похожая тема от Meta
- Агентный ИИ: модели, которые действуют самостоятельно — общий обзор агентного ИИ
- Claude Code: как перестать бороться с регрессиями — практические приёмы работы с ИИ-ассистентом



