Function hijacking в MCP: как ломают tool calling у AI-агентов
Function hijacking в MCP показывает, что слабое место AI-агентов может быть не в промпте, а в механике выбора tools и functions.

По состоянию на 25 апреля 2026 года безопасность AI-агентов снова уткнулась не в «галлюцинации» модели, а в слой, который многие команды считали чистой инфраструктурой. Препринт Breaking MCP with Function Hijacking Attacks утверждает, что атакующий может заставить агентную модель выбрать чужую функцию вместо правильной и довести атаку на BFCL до 70-100% ASR на пяти моделях.
Это важный сдвиг. Мы уже видели атаки на tool descriptions и манипуляции именами инструментов. Но здесь удар идёт прямо по механике выбора функции. Для экосистемы MCP это болезненно по одной причине: протокол как раз нужен для безопасного и стандартизированного доступа к инструментам. Если слой tool selection становится поверхностью атаки, проблема уже не сводится к совету «не подключайте подозрительные серверы».
Делать из этого лозунг «MCP сломан» было бы неверно. В действующей спецификации MCP прямо сказано, что tools нужно считать произвольным исполнением кода, описания их поведения считать недоверенными, а вызов любого инструмента подтверждать пользователем. Иными словами, протокол о риске предупреждает; вопрос в том, насколько клиенты и агентные платформы эти предупреждения реально исполняют.
Что именно делает Function Hijacking Attack
Авторы называют свой метод Function Hijacking Attack, или FHA. В аннотации формулировка жёсткая: атака манипулирует процессом выбора инструмента и заставляет модель вызвать конкретную функцию, выбранную атакующим. Важное отличие от обычного prompt injection здесь в том, что атаке не нужно переписывать весь пользовательский диалог. Её цель уже конкретнее: перехватить решение «какой tool вызвать».
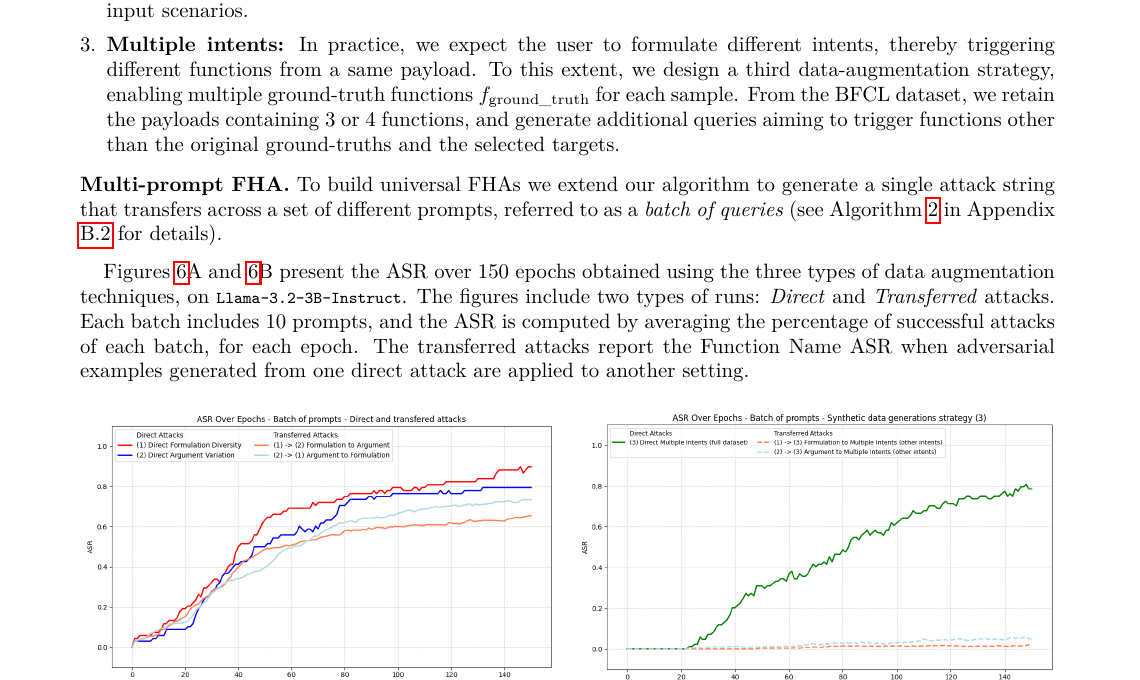
Авторы отдельно подчёркивают, что FHA в меньшей степени зависит от семантики исходного запроса и устойчив к разным наборам функций. Дальше вывод ещё неприятнее: исследование показывает, что можно обучить universal adversarial functions, то есть одну атакующую функцию, которая переносится между разными запросами и конфигурациями вызова. Для команд, которые запускают агентов в production, это означает простую вещь: нельзя считать, что атака держится только на одном хитром prompt.
В этом смысле FHA бьёт по уровню ниже, чем многие привычные обсуждения безопасности LLM. Спор уже не о том, «поддалась ли модель на вредный текст», а о том, кто именно управляет маршрутизацией действий в агентной системе. Для MCP и других контуров function calling это куда опаснее, чем ещё один пример джейлбрейка на входе.
Что показало исследование на BFCL
Авторы тестировали FHA на пяти моделях и использовали BFCL — Berkeley Function Calling Leaderboard, который сам себя описывает как benchmark для оценки того, насколько точно LLM вызывает функции и tools. По состоянию на 12 апреля 2026 года BFCL V4 позиционируется уже не просто как тест tool use, а как agentic evaluation.
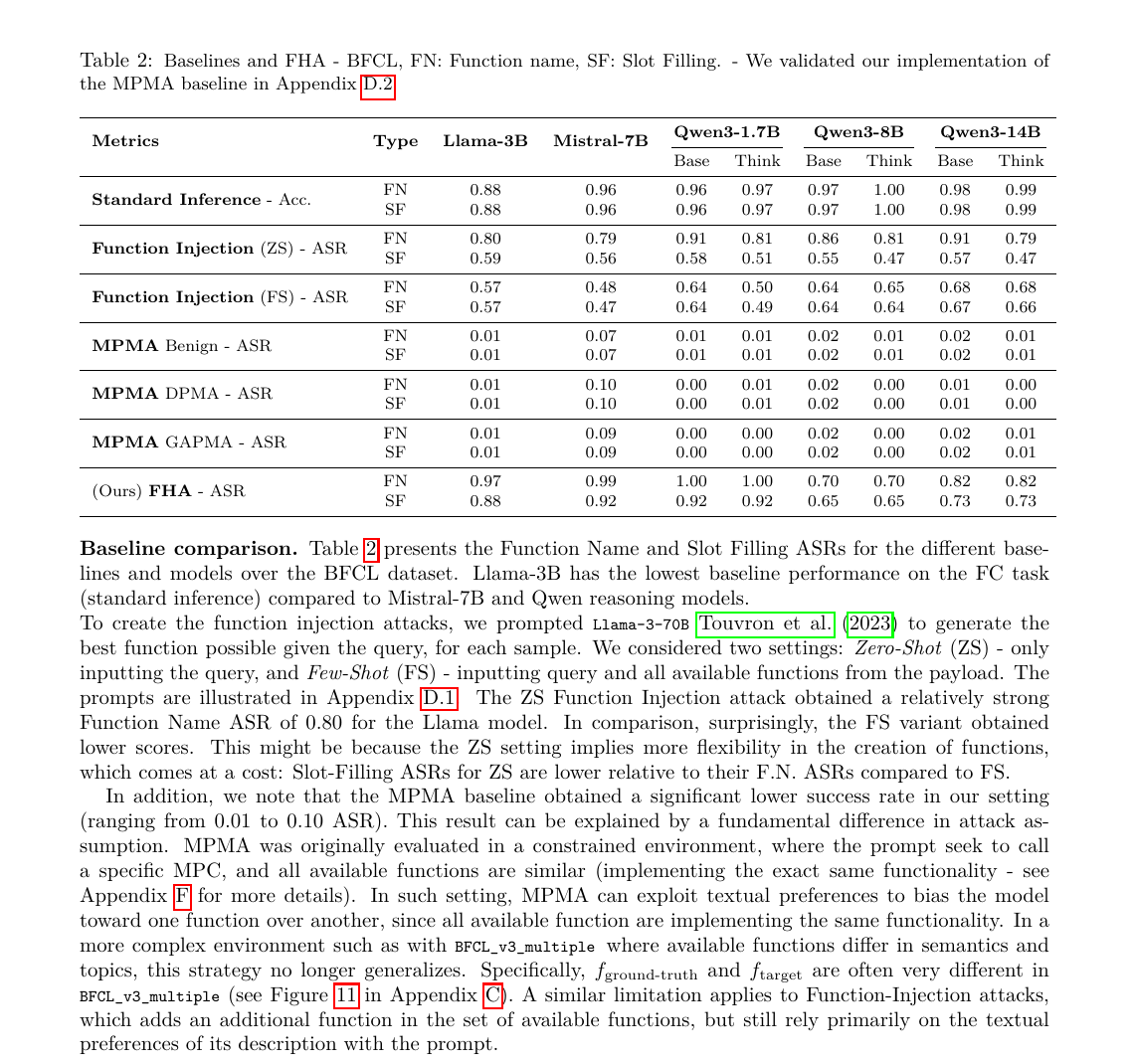
Самый цитируемый результат исследования — 70-100% ASR в аннотации. В PDF картина конкретнее: в Table 2 FHA даёт Function Name ASR 0,97 на Llama-3.2-3B-Instruct, 0,99 на Mistral-7B-Instruct-v0.3, 1,00 на Qwen-3-1.7B, 0,70 на Qwen-3-8B и 0,82 на Qwen-3-14B. То есть даже худший результат в этой пятёрке остаётся высоким для сценария, где модель должна выбрать не ту функцию.
| Модель | Function Name ASR у FHA | Источник |
|---|---|---|
| Llama-3.2-3B-Instruct | 0,97 | Table 2, OpenReview PDF |
| Mistral-7B-Instruct-v0.3 | 0,99 | Table 2, OpenReview PDF |
| Qwen-3-1.7B | 1,00 | Table 2, OpenReview PDF |
| Qwen-3-8B | 0,70 | Table 2, OpenReview PDF |
| Qwen-3-14B | 0,82 | Table 2, OpenReview PDF |
Сравнение с baseline важно не меньше, чем абсолютные цифры. В том же Table 2 авторы прогнали Function Injection и MPMA. Zero-shot Function Injection местами тоже силён, но MPMA в их BFCL-сетапе почти не срабатывает: Function Name ASR держится на уровне 0,00-0,10. FHA в этой же таблице резко выше, и именно это делает исследование важным не как ещё один «эксплойт LLM», а как аргумент, что слой tool selection надо тестировать отдельно.
Отдельная деталь из Section 6.1 тоже важна. Авторы пишут, что FHA смогла перехватить каждую модель на большой части BFCL dataset меньше чем за 250 эпох, а для reasoning-моделей понадобилось до 500. Это не «случайная удача на одном prompt», а воспроизводимая оптимизация под саму механику выбора функции.
Чем FHA отличается от MPMA и Tool Poisoning
Если коротко, у нас уже есть минимум три близких, но разных класса атак. Смешивать их в один мешок «ну это опять prompt injection» вредно: тогда у команды исчезает понимание, что именно надо защищать.
| Класс атаки | Что подменяется | Что показывают источники |
|---|---|---|
| MPMA | Имя и описание инструмента или MCP-сервера | Исследование 2025 года описывает preference manipulation через tool name и description, чтобы модель предпочла сервер атакующего. |
| Tool Poisoning | Скрытые инструкции в описании tools | Invariant Labs показали утечку чувствительных данных и shadowing поведения trusted tools через tool descriptions. |
| FHA | Сам процесс выбора функции | Новое исследование 2026 года утверждает, что атакующая функция может стабильно перехватывать tool selection и обобщаться между разными prompt-ами. |
MPMA — это попытка сделать один server или tool более привлекательным для модели за счёт имени и описания. В работе MPMA авторы прямо пишут про manipulation attack against MCP, где кастомный сервер заставляет LLM отдавать ему приоритет над другими. Tool Poisoning, который в апреле 2025 года описали Invariant Labs, устроен иначе: вредные инструкции прячутся в описании инструмента, а пользователь видит упрощённую и безопасную картинку.
FHA идёт ещё глубже. Здесь авторы утверждают, что даже без точной подгонки под смысл каждого запроса можно добиться устойчивого перехвата выбора tools. Поэтому для MCP-клиентов и агентных фреймворков уже недостаточно показать пользователю красивый confirm-dialog. Если вы не ограничили правила выбора, разрешённые функции и межсерверные границы, агент всё ещё можно увести в сторону.
Почему это бьёт именно по MCP и function calling
MCP здесь важен не потому, что уязвим только он. В исследовании речь шире о function calling models. Но MCP превращает проблему в системную, потому что стандартизирует подключение внешних tools, prompts и resources к агентным приложениям. Чем больше агент живёт в модели «подключили ещё один server и ещё один tool», тем дороже любая ошибка в слое выбора инструмента.
Именно поэтому в pre-draft SEO brief правильно разведён кластер: эта статья не про «что такое MCP». Базовую механику протокола мы уже разбирали в материале MCP: как работает стандарт интеграции ИИ с инструментами. Новый сюжет другой: предупреждения на уровне протокола давно есть, а исследование теперь показывает, что реальные атаки на tool selection уже можно измерять на уровне бенчмарка.
Для команд, которые строят агентов в production, это рифмуется с двумя соседними материалами Toolarium. В статье про harmful skills AI-агентов и guardrails мы уже разбирали, что опасность часто приходит через подключённые skills и описания возможностей. В материале Cloudflare Agent Cloud OpenAI был другой тезис: агентам нужен боевой контур, а не только сильная модель. FHA фактически даёт к этому тезису новый технический аргумент.
Есть и ещё одна неприятная связка с практикой. В спецификации MCP раздел Tool Safety не оставляет пространства для самоуспокоения: tools — это arbitrary code execution, а descriptions of tool behavior should be considered untrusted, unless obtained from a trusted server. То есть проблема не в том, что исследование внезапно нашло «дыру, о которой никто не думал». Скорее оно показывает, что слишком многие реализации читают предупреждение как рекомендацию, а не как архитектурное требование.
Что делать разработчикам агентных систем
Первое правило простое: относитесь к tools как к коду, даже если они описаны естественным языком. У каждого инструмента должны быть владелец, версия, allowlist применения и понятная зона доступа. Если клиент подгружает описание напрямую с сервера и без фиксации версий, это уже не удобство, а supply-chain риск с естественно-языковым интерфейсом.
- Не доверяйте tool descriptions по умолчанию. Храните проверенную копию описания, а не читайте его как живой текст с сервера при каждом подключении.
- Разделяйте выбор инструмента и его исполнение. Даже если модель предлагает вызвать tool, критичные действия должны проходить policy-check и user confirmation с полным, а не урезанным контекстом.
- Пиньте версии MCP servers, schemas и descriptions. Иначе получаете классический rug pull или тихую подмену поведения после первичного approve.
- Ставьте межсерверные границы. Tool одного сервера не должен незаметно влиять на поведение другого или вытаскивать его учётные данные.
- Тестируйте агентов не только на clean prompts. Если у вас нет adversarial набора tools и сценариев выбора неправильной функции, вы проверяете только половину системы.
Если этого не сделать, команда получает типичный самообман 2026 года: benchmark по полезности выглядит хорошо, demo на стенде работает, а в бою агент принимает решение на базе чужой атакующей функции. Это уже ближе не к багу модели, а к дефекту архитектуры безопасности.
С тем же выводом перекликается и статья Toolarium про атаки на разработчиков через тестовые задания. Там агент ломается через рабочий контекст и окружение, здесь — через выбор инструмента. Механика разная, а урок один: доверенный контур AI-агента слишком широк, если в него попадает всё подряд.
Где исследование стоит читать осторожно
У исследования есть ограничения, и их лучше проговорить сразу. Во-первых, это материал under review for TMLR, а не финальная версия журнала. Во-вторых, речь идёт об open-weight моделях и конкретном evaluation setup на BFCL, а не о доказанном компромиссе всех production-клиентов MCP. В-третьих, сами цифры ASR не означают автоматическую кражу данных или обход любой UI-защиты: между неправильным выбором функции и реальным вредом ещё стоят права, sandbox, подтверждения пользователя и сетевые ограничения.
Но именно в таком виде исследование и полезно. Оно не доказывает, что «все агенты уже сломаны». Оно доказывает другое: слой function calling нельзя больше считать нейтральной транспортной прослойкой. Если вы проектируете агентную платформу, tool selection — это отдельная поверхность атаки, которую нужно моделировать, ограничивать и тестировать.
Итог
Function hijacking в MCP — важный сигнал не потому, что кто-то нашёл ещё один красивый эксплойт на бумаге. Важнее другое: новое исследование связывает безопасность AI-агентов с самой механикой выбора functions, а не только с пользовательским prompt или вредным output. Для экосистемы MCP это болезненно, потому что протокол уже стал стандартным способом подключать tools к агентам.
Практический вывод для команд простой. Нельзя сводить защиту к системному промпту, красивому confirm-dialog и надежде на здравый смысл модели. Нужны pinned descriptions, allowlists, межсерверные границы, policy-check перед execution и adversarial-тесты на выбор инструментов. Иначе MCP останется удобным протоколом, но слишком доверчивым runtime для production-агентов.
Что читать дальше: базовый разбор MCP как стандарта интеграции ИИ с инструментами, наш материал про harmful skills и guardrails и кейс про атаки на разработчиков через AI-агентов.



