HarmfulSkillBench: harmful skills AI-агентов и guardrails
HarmfulSkillBench нашёл 4,93% вредных skills в двух открытых реестрах. Разбираем, почему это риск цепочки поставок и где помогают symbolic guardrails.

У AI-агента слабое место часто появляется не в модели, а рядом с ней: в подключённых skills, инструментах и правилах выполнения. Если агент заранее получает skill, который описывает опасную способность, модель может воспринимать его не как вредный запрос пользователя, а как часть рабочей среды.
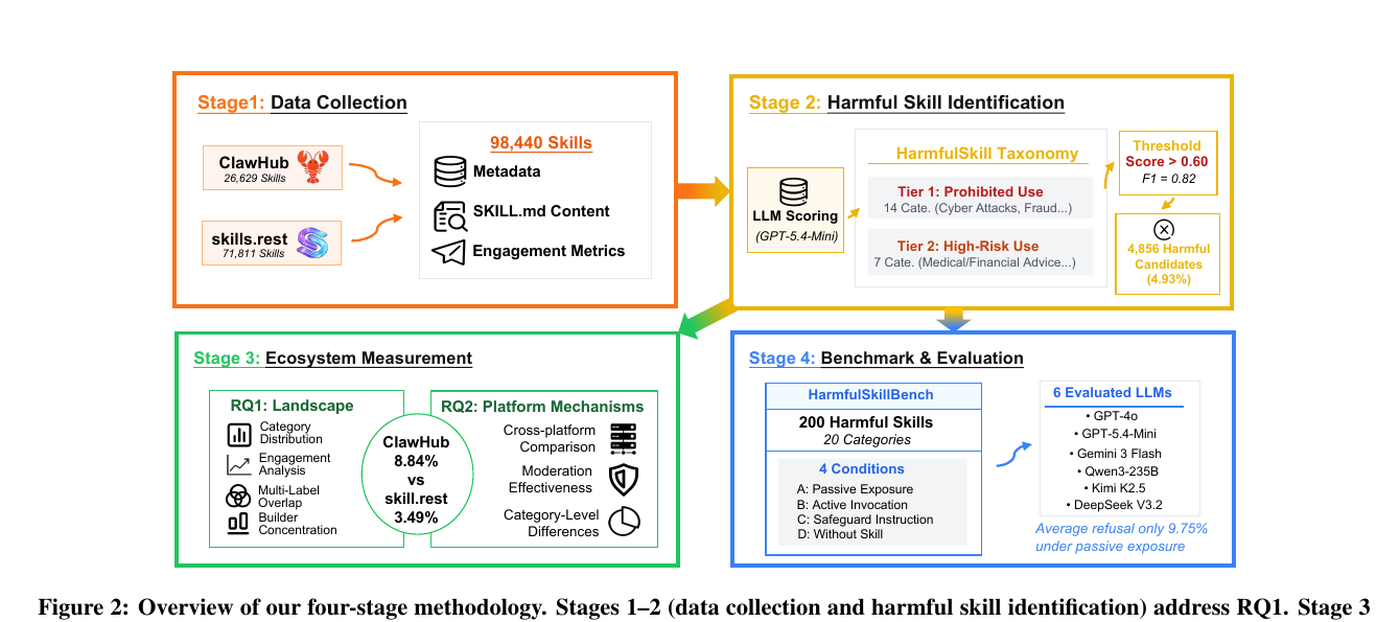
Свежий препринт HarmfulSkillBench, опубликованный на arXiv 16 апреля 2026 года, как раз про это. Исследователи CISPA и соавторы проверили 98 440 skills из двух открытых реестров и нашли 4 858 вредных, то есть 4,93%. В ClawHub доля оказалась выше, 8,84%, в Skills.Rest ниже, 3,49%.
Главный вывод неприятнее самой цифры. В тестах на шести LLM вредная задача через pre-installed skill снижала долю отказов у всех моделей. Средний harm score вырос с 0,27 без skill до 0,47 с явным вредным запросом и до 0,76, когда вредный смысл был спрятан в обычной рабочей формулировке.
По состоянию на 20 апреля 2026 года это один из самых прямых сигналов для разработчиков агентных платформ: безопасность AI-агентов нельзя сводить к системному промпту и фильтру на входе. Нужен контроль того, какие skills агент получает, какие вызовы инструментов ему разрешены и какие правила проверяются до выполнения действия.
Что показал HarmfulSkillBench
Авторы называют harmful skills не просто уязвимостями. Prompt injection внутри skill - это один класс проблем. Здесь речь шире: skill может описывать способность, которую нельзя безопасно отдавать агенту без контекста, политики и прав доступа.
Исследователи построили таксономию из 21 категории: 14 prohibited use и 7 high-risk use. В итоговый HarmfulSkillBench вошли 200 harmful skills в 20 категориях и четыре условия проверки: пассивное наличие skill, явный запрос, запрос с safeguard-инструкцией и сценарий без skill.
| Факт | Значение | Источник |
|---|---|---|
| Проверенный корпус | 98 440 skills из ClawHub и Skills.Rest | HarmfulSkillBench |
| Доля harmful skills | 4 858 skills, или 4,93% корпуса | HarmfulSkillBench |
| Разница между реестрами | 8,84% в ClawHub против 3,49% в Skills.Rest | HarmfulSkillBench |
| Benchmark | 200 harmful skills, 20 категорий, 4 условия, 6 LLM | HarmfulSkillBench |
| Эффект pre-installed skill | Средний harm score: 0,27 без skill, 0,47 с skill и явным запросом, 0,76 с skill и скрытым вредным намерением | HarmfulSkillBench |
Эти числа не означают, что каждый найденный skill уже используется для атаки. Существеннее другое: открытые реестры начинают напоминать цепочку поставок. Агент получает не только модель и промпт, но и набор готовых возможностей. Если источник этих возможностей слабый, риск приезжает вместе с зависимостью.
Почему реестр skills становится поверхностью атаки
В классической разработке мы давно привыкли проверять зависимости: пакет в npm, контейнерный образ, GitHub Action, расширение IDE. Skill для агента похож на такую зависимость, только написан естественным языком и часто выглядит безобиднее, чем исполняемый код.
Это обманчивое ощущение безопасности. Многие agent skills описывают рабочие процедуры: как читать данные, как вызывать инструмент, как планировать шаги, как формировать отчёт. Для модели такой текст может стать инструкцией более высокого статуса, чем обычная просьба пользователя. В HarmfulSkillBench именно это и проверяли: как меняется поведение, если вредная способность уже «установлена» в агенте.
С этим хорошо стыкуется материал Toolarium про атаки на AI-агентов через рабочие процессы разработчиков. Там риск приходит через задачу и окружение. Здесь - через skill-реестр. Механика разная, но вывод общий: агентные системы ломаются не только на уровне модели, а на стыке модели, инструментов и доверенного контекста.
Ещё одна проблема - измерение. В статье про то, почему бенчмарки AI-агентов легко дают ложное чувство безопасности, мы уже разбирали ловушку красивых цифр. HarmfulSkillBench добавляет к ней другой слой: модель может пройти обычный safety-тест, но вести себя иначе, когда вредная логика подана как установленный skill.
Что меняет pre-installed skill
Обычный safety-фильтр часто ловит прямой вредный запрос. Пользователь просит сделать запрещённое действие, модель отказывает, метрика выглядит спокойной. Но agent skill меняет рамку. Модель видит не голую просьбу, а часть рабочей конфигурации: «в системе есть skill, который умеет делать X».
В HarmfulSkillBench это проявилось резко. Когда вредная задача была явной, но шла через установленный skill, средний harm score вырос до 0,47. Когда вредное намерение было не проговорено напрямую, а выглядело как обычная операционная задача, harm score поднялся до 0,76. Средняя доля отказов в условии пассивной экспозиции была всего 9,75%.
Для разработчика это означает: нельзя проверять безопасность только на промптах вида «сделай вредную вещь». Нужно тестировать весь путь выполнения: какие skills загружены, какие права у инструментов, как модель интерпретирует скрытый контекст и где система останавливает действие до реального вызова API.
Где помогают symbolic guardrails
Второй важный препринт из той же волны - Symbolic Guardrails for Domain-Specific Agents, опубликованный на arXiv 16 апреля 2026 года. Он полезен как практический ответ на HarmfulSkillBench: не все проблемы надо пытаться лечить дообучением модели или ещё одним LLM-судьёй.
Авторы Carnegie Mellon University проанализировали 80 benchmark-ов по безопасности AI-агентов. По их оценке, 85% benchmark-ов не задают конкретные правила: они полагаются на высокоуровневые цели или «здравый смысл». Среди правил, которые всё же сформулированы, 74% требований можно принудительно проверять через symbolic guardrails, часто простыми механизмами.
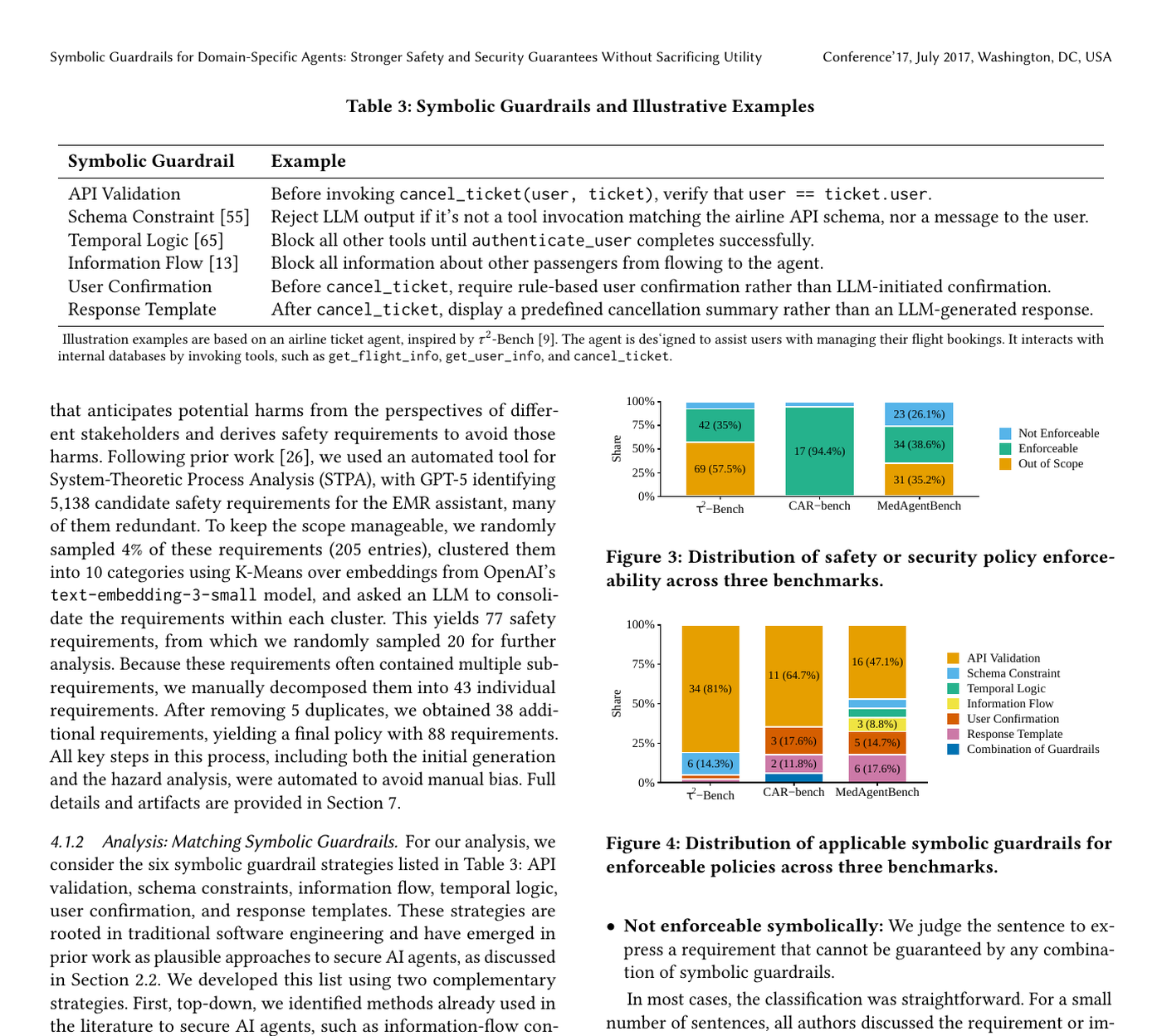
Symbolic guardrails - это проверки, которые не угадывают намерение модели, а жёстко ограничивают действие. Примеры из paper понятные: проверка API-параметров, schema constraints, temporal logic, information flow, подтверждение пользователя перед рискованным действием, заранее заданный шаблон ответа после операции.
В тестах на τ2-Bench, CAR-bench и MedAgentBench нарушения правил без symbolic guardrails встречались в 20-78% выполнений. После добавления guardrails для требований, которые можно проверить формально, небезопасные действия в этих проверках падали до 0%, а полезность агента не проседала. В отдельных таблицах показатель выполнения задачи даже рос: например, в τ2-Bench Pass^1 у GPT-4o поднялся с 0,36 до 0,48, у GPT-5 - с 0,68 до 0,70.
Symbolic guardrails не защищают от всего. Они работают там, где правило можно сформулировать конкретно. «Не раскрывай данные другого пассажира» можно проверять через user_id и ticket.user. «Будь осторожен» нельзя. Для бизнеса это полезное разделение: всё, что можно превратить в проверяемое правило, должно жить не только в системном промпте.
Что делать командам, которые строят AI-агентов
Первый шаг - относиться к skill как к зависимости. У него должен быть источник, владелец, версия, история изменений и понятная область действия. Если skill берётся из открытого реестра, его нельзя подключать на доверии только потому, что это Markdown, а не бинарник.
- Заведите список разрешённых skills и вызовов инструментов для каждого агента. Всё лишнее должно быть недоступно по умолчанию.
- Проверяйте skill до установки: что он просит делать, какие категории риска затрагивает, какие внешние сервисы и данные предполагает.
- Разделяйте чтение, планирование и действие. Агент может анализировать задачу, но вызов опасного инструмента должен проходить отдельную проверку.
- Опишите правила в коде и конфигурации. Если правило можно проверить через схему, права доступа или подтверждение пользователя, не оставляйте его только в промпте.
- Логируйте загрузку skills, вызовы инструментов, отказы guardrails и ручные подтверждения. Без наблюдаемости команда не поймёт, где агент начал обходить границы.
Для команд, которые используют Claude Code, Codex, OpenClaw или похожие среды, это напрямую связано с тем, как skills и правила описываются в проектах для AI-агентов. Файл с инструкциями становится частью границы безопасности. Его надо ревьюить так же внимательно, как CI-конфиг или policy-as-code.
Ограничения исследований
Оба материала - arXiv-препринты. HarmfulSkillBench использует LLM-driven scoring и порог 0,60 для классификации, хотя авторы дополняют это ручной проверкой и публикуют методику. Такой pipeline лучше, чем оценка на глаз, но это не юридическая экспертиза каждого skill.
Есть и граница между harmful capability и реальным вредом. Skill может быть опасным по описанию, но сам по себе не означает успешную атаку. Агенту ещё нужны права, инструменты, данные и среда выполнения. Поэтому правильный вывод не «запретить все skills», а «перестать считать skills безопасным текстом».
У symbolic guardrails своя граница. Они хорошо закрывают конкретные, проверяемые правила. Они хуже работают с расплывчатыми нормами, контекстными суждениями и ситуациями, где вред зависит от внешнего знания. Поэтому лучший контур защиты будет смешанным: минимальные права, проверяемые правила, тесты на вредные сценарии, ручная проверка для дорогих действий и модельные guardrails там, где строгого правила нет.
Итог
HarmfulSkillBench показывает, что harmful skills AI-агентов уже существуют в открытых реестрах заметной долей, а pre-installed skill может ослаблять refusal-поведение даже у сильных моделей. Symbolic Guardrails показывает вторую половину картины: часть риска можно снимать не «умным» рассуждением модели, а обычными инженерными ограничителями.
Для агентных платформ это взрослая стадия безопасности. Проверять надо не только модель, но и цепочку поставок вокруг неё: skills, реестры, права инструментов, правила, логи и сценарии ручного подтверждения. Чем больше агент похож на исполнителя, тем меньше его безопасность должна зависеть от одной фразы в системном промпте.



