FIPO обошёл o1-mini, Memori режет токены в 20 раз: три исследования недели
Три исследования недели: FIPO обогнал o1-mini в математике, Memori режет токены агентов в 20 раз, и ИИ-гонка давит на энергосети Европы.

На прошлой неделе на arXiv появились две работы, которые заслуживают внимания практиков: одна про обучение LLM с подкреплением, другая про долгосрочную память агентов. Параллельно WIRED разобрал, как спрос ИИ-индустрии на вычисления упирается в физические ограничения европейских энергосетей. Разбираем все три.
FIPO: reward-сигнал на уровне токенов
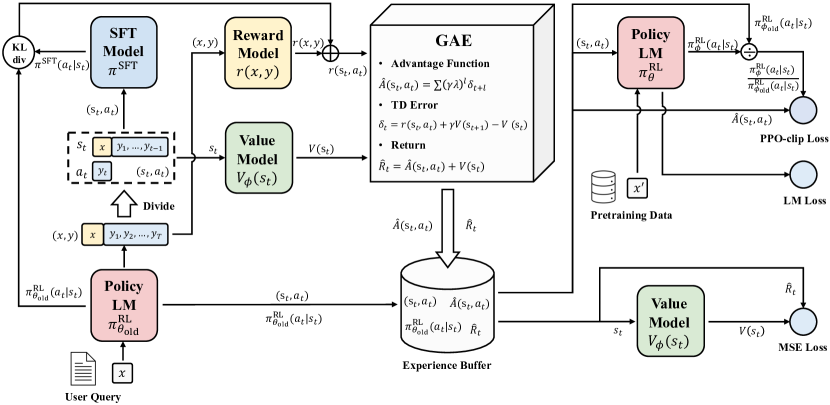
Команда из Alibaba и Дартмутского колледжа представила FIPO (Future-KL Influenced Policy Optimization), алгоритм обучения с подкреплением, который решает конкретную проблему GRPO-подобных методов.
Стандартные RL-подходы для LLM (GRPO, REINFORCE) используют outcome-based rewards. Модель получает одну оценку за весь ответ, и она делится поровну на все токены. Токен с ключевым логическим поворотом получает такой же градиент, как служебное слово «therefore». Это создаёт потолок: модель не учится различать важные и неважные шаги рассуждения.
FIPO добавляет в формулу обновления политики дисконтированную future-KL дивергенцию. Каждый токен получает вес пропорционально тому, насколько он повлиял на дальнейшее поведение модели. Вместо uniform advantage получается dense advantage, плотный сигнал вознаграждения.
Результаты на Qwen2.5-32B:
- AIME 2024 Pass@1: с 50.0% до 58.0% (пик), стабильно около 56%
- Средняя длина цепочки рассуждений выросла с ~4 000 до 10 000+ токенов
- Обошёл DeepSeek-R1-Zero-Math-32B (~47%) и o1-mini (~56%)
Код открыт, построен на фреймворке verl. Базовая модель — открытая Qwen2.5-32B, что делает результаты воспроизводимыми без доступа к проприетарным системам.
Потолок RL-обучения LLM, судя по этой работе, во многом определяется гранулярностью вознаграждения. Когда модель получает дифференцированный сигнал по токенам, она учится рассуждать глубже. Скорее всего, это направление подхватят другие группы.
Memori: память агентов через семантические тройки
Второй заметный препринт — Memori, слой персистентной памяти для LLM-агентов. Проблема знакома всем, кто строил чат-ботов или агентные системы: дать модели контекст из прошлых сессий, не раздувая промпт до десятков тысяч токенов.
Стандартный подход — запихнуть историю диалогов в контекст целиком. С ростом истории растёт стоимость, а качество ответов падает: модель начинает «тонуть» в нерелевантном тексте.
Memori предлагает другой путь. Их пайплайн Advanced Augmentation превращает сырые диалоги в компактные семантические тройки (субъект, предикат, объект) и краткие саммари. При запросе система достаёт только релевантные тройки, а не весь текст разговоров.
Цифры на бенчмарке LoCoMo:
- 81.95% точности, лучше существующих систем памяти
- 1 294 токена на запрос, около 5% от полного контекста
- На 67% меньше токенов, чем ближайшие конкуренты
- В 20 раз дешевле полноконтекстных подходов
Memori не привязан к конкретному провайдеру и работает с любой моделью через API. Для тех, кто строит агентов, вывод прямой: структурированное хранение эффективнее расширения контекстного окна. Платить за 128K-контекст, когда хватает 1 300 токенов, незачем.
ИИ-гонка давит на энергосети Европы
WIRED разобрал ситуацию с энергетикой в Европе. Дата-центры массово подключаются к электросетям, и главное ограничение здесь — транспортировка энергии, а не её генерация.
Сетевые операторы экспериментируют: dynamic line rating (использование пропускной способности линий в зависимости от погоды), перенаправление нагрузки в менее загруженные регионы, приоритетное подключение дата-центров к промышленным узлам.
Строительство новых ЛЭП занимает 5–10 лет, а очередь на подключение дата-центров растёт уже сейчас. Даже если генерирующих мощностей формально хватает, «последняя миля» до потребителя становится бутылочным горлышком.
Для ИИ-индустрии это физический потолок. Чипы и модели становятся эффективнее, но без модернизации электросетей Европа будет отставать от США и Азии по вычислительным мощностям. По данным WIRED, некоторым европейским проектам дата-центров уже приходится ждать подключения годами.
Что объединяет эти три темы
Все три истории — про эффективность на разных уровнях. FIPO точнее распределяет reward при обучении. Memori сжимает контекст, заменяя сырой текст структурированными данными. А европейские энергосети показывают, что даже самые элегантные алгоритмы упираются в физику, где оптимизаций пока не хватает.
Ссылки на работы
- FIPO: Eliciting Deep Reasoning with Future-KL Influenced Policy Optimization (arXiv, 20 марта 2026)
- Memori: A Persistent Memory Layer for Efficient, Context-Aware LLM Agents (arXiv, 20 марта 2026)
- The AI Race Is Pressuring Utilities to Squeeze More From Europe's Power Grids (WIRED, 23 марта 2026)



