DiffusionGemma: Google DeepMind ускоряет локальные LLM
Google DeepMind выпустила DiffusionGemma, открытую diffusion-LLM для быстрых локальных сценариев. Разбираем скорость, ограничения и риски памяти.

DiffusionGemma: Google DeepMind ускоряет локальные LLM
DiffusionGemma - экспериментальная открытая diffusion-LLM Google DeepMind, которая генерирует блоки текста параллельно, а не токен за токеном. По состоянию на 10 июня 2026 года Google выпускает её под Apache 2.0 и позиционирует как модель для быстрых локальных сценариев: inline editing, агентные циклы, код, математика и интерактивные ассистенты на выделенных GPU.
Главная новость не в том, что появилась ещё одна Gemma. Google пробует другой способ вывода текста: меньше ждать последовательную цепочку токенов, больше загружать GPU параллельной работой. Цена этого подхода тоже названа прямо: для максимального качества Google по-прежнему рекомендует стандартную Gemma 4.
Что выпустила Google
Google анонсировала DiffusionGemma 10 июня 2026 года. Это open-weights модель Google DeepMind на базе Gemma 4 26B A4B: в релизе она описана как 26B Mixture-of-Experts, а в официальной model card указаны 25,2 млрд total parameters и 3,8 млрд active parameters.
Модель принимает текст, изображения и видео, а на выходе генерирует текст. В отличие от обычной autoregressive LLM, DiffusionGemma не печатает ответ строго слева направо. Она работает с canvas-блоками: берёт набор случайных токенов, несколько раз уточняет весь блок и фиксирует более уверенные позиции. В документации Google canvas length указан как 256 токенов, контекст - до 256K токенов.
| Что меняется | Где полезно | Ограничение |
|---|---|---|
| 256 токенов обрабатываются блоком | Быстрые локальные ответы, inline editing, code infilling | Выигрыш сильнее при batch size 1 и низкой конкуренции запросов |
| 3,8B active parameters при 25,2B total | Локальный запуск после квантизации, меньше активной нагрузки на шаг | Нужен мощный выделенный ускоритель; notebook Google для полной модели требует более 60GB памяти |
| Apache 2.0 и открытые веса | Исследования, fine-tuning, локальные прототипы | Экспериментальный статус и качество ниже стандартной Gemma 4 |
Почему DiffusionGemma быстрее в локальных сценариях
Обычная LLM при генерации чаще упирается не в вычисления, а в память: каждый новый токен требует снова двигать веса через железо. В облаке это маскируется батчингом тысяч пользователей. На локальной GPU одного пользователя батчинг почти не помогает, и часть вычислительной мощности простаивает.
DiffusionGemma пытается занять этот простой. Модель обрабатывает блок текста целиком и использует bidirectional attention внутри canvas. Google заявляет до 4x более быструю генерацию на выделенных GPU: 1000+ tokens/s на NVIDIA H100 и 700+ tokens/s на GeForce RTX 5090. На официальном графике для H100 показаны 1107 tokens/s у DiffusionGemma 26B A4B против 303 tokens/s у Gemma 4 26B A4B в выбранном режиме.
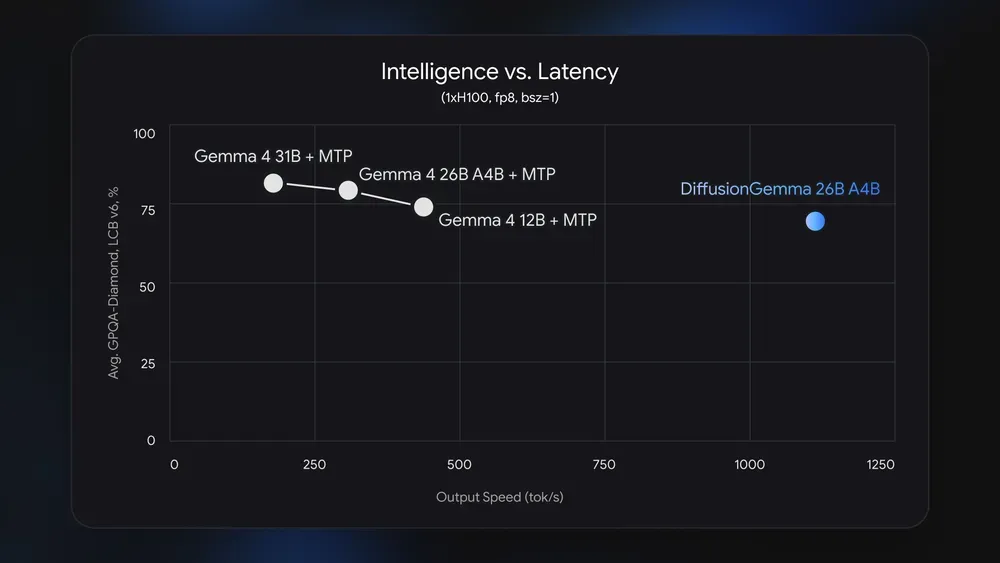
Здесь важно не перепродать цифру. Google отдельно уточняет, что преимущество рассчитано на local и low-concurrency inference. В high-QPS cloud-serving autoregressive-модели можно эффективно загрузить батчами, поэтому параллельное декодирование DiffusionGemma даёт меньше пользы и может стоить дороже. На unified-memory архитектурах вроде Apple Silicon ускорение тоже не гарантировано.
Чем DiffusionGemma отличается от обычной LLM
Autoregressive-модель выбирает следующий токен, добавляет его к контексту и идёт дальше. Ошибка в начале ответа часто остаётся в тексте, потому что модель уже ушла вправо. DiffusionGemma работает ближе к черновику: сначала весь блок шумный, затем модель несколько раз очищает его и может пересмотреть позиции внутри canvas.
Google описывает это как discrete text diffusion и block-autoregressive multi-canvas sampling. Сначала encoder обрабатывает запрос и создаёт KV-cache. Затем denoiser с bidirectional attention уточняет блок токенов, после чего готовый canvas добавляется в контекст, и модель переходит к следующему блоку.
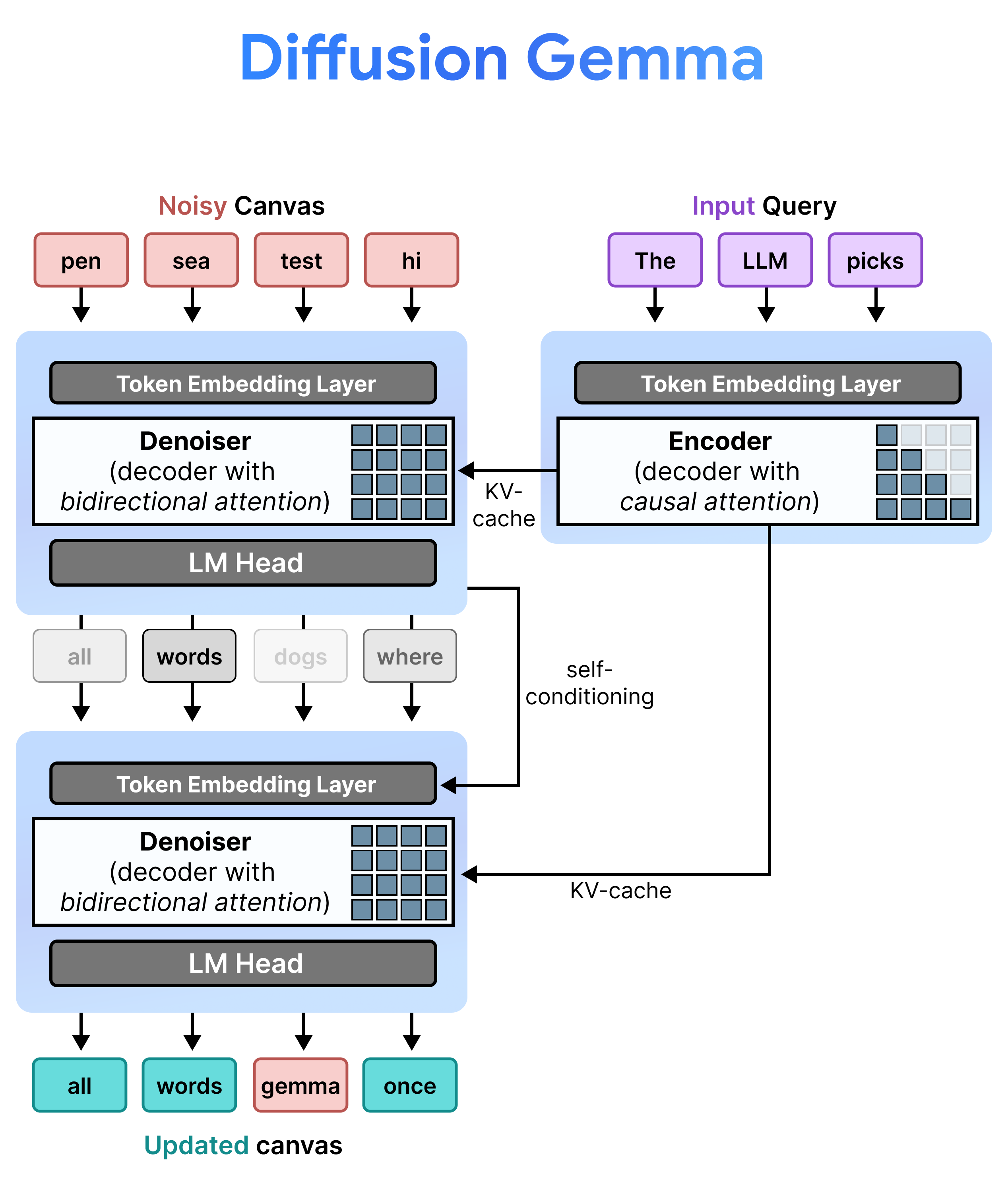
Для читателей Toolarium это продолжение темы, которую мы уже разбирали на примере NVIDIA Nemotron-Labs Diffusion. Разница в том, что DiffusionGemma приходит из семейства Gemma и сразу получает официальные пути запуска через Hugging Face, vLLM, Vertex и NVIDIA-стек.
Где модель может быть полезна
DiffusionGemma лучше всего выглядит там, где человек или агент ждёт короткую реакцию от локальной модели. Это автодополнение кода, исправление блоков Markdown, генерация SVG или HTML, быстрые черновики, математические структуры и циклы, где агенту нужно много раз думать, проверять и править.
Для локального запуска важны две детали. Во-первых, Google пишет, что после квантизации модель помещается в 18GB VRAM на consumer GPU. Во-вторых, NVIDIA уже заявляет поддержку на GeForce RTX, RTX PRO, DGX Spark и DGX Station, а также day-zero support в Hugging Face Transformers, vLLM и Unsloth. Если вам нужен общий контекст по локальным моделям, полезно начать с нашего гайда как запустить локальную LLM через Ollama, но DiffusionGemma пока не выглядит как модель для новичкового ноутбука.
Техническая планка подтверждается и в документации Google: пример с Hugging Face Transformers требует GPU с более чем 60GB памяти. Разница с 18GB после квантизации показывает, насколько сильно итоговые требования зависят от формата весов и режима запуска.
Почему DiffusionGemma не заменяет Gemma 4
Google не пытается представить DiffusionGemma как универсальную замену Gemma 4. В релизе прямо сказано: autoregressive Gemma 4 остаётся стандартом для production-выходов, где важнее максимальное качество. DiffusionGemma делает ставку на скорость и параллельную разметку текста, поэтому часть benchmark-показателей ниже.

На опубликованном графике DiffusionGemma выигрывает по скорости, но уступает Gemma 4 26B A4B в ряде задач: MMLU Pro, AIME 2026, LiveCodeBench v6, GPQA Diamond и tau2. В model card есть и более полный список: например, 77,6% против 82,6% на MMLU Pro, 69,1% против 88,3% на AIME 2026 без инструментов, 69,1% против 77,1% на LiveCodeBench v6.
Практический вывод простой: DiffusionGemma стоит тестировать не как "самую умную Gemma", а как быстрый движок для отдельных интерактивных задач. Если задача требует максимальной точности, сложного рассуждения без права на ошибку или дешёвого cloud-serving при большом потоке запросов, стандартная Gemma 4 может быть рациональнее.
Где тут риски AI memory
Ускорение локальных моделей не отменяет проблем памяти AI-агентов. Когда ассистент работает на устройстве, читает документы, помнит прошлые сессии и вызывает инструменты, граница доверия проходит не только через модель, но и через retrieval. Неправильно извлечённая память может принести старый контекст в новый домен, усилить sycophancy или сбить tool-call.
Такие сбои уже изучают в экспериментах. В феврале 2026 года MIT News описал исследование MIT и Penn State: 38 участников общались с чатботом две недели, в среднем по 90 запросов на человека, и long-term interaction context повышал agreeableness в четырёх из пяти моделей. Особенно сильный эффект давал сжатый user profile в памяти. Поэтому тема новой памяти ChatGPT и исследования про подхалимство чатботов становятся важнее по мере того, как локальные модели ускоряются.
В свежей работе Beyond Similarity: Trustworthy Memory Search for Personal AI Agents memory search прямо описан как trust boundary. Авторы выделяют cross-domain leakage, sycophancy, tool-call drift и memory-induced jailbreaks. Для DiffusionGemma это не недостаток самой модели, а инженерное предупреждение: быстрый локальный цикл делает плохую память быстрее, а не безопаснее.
Что проверять перед внедрением
DiffusionGemma выглядит сильным исследовательским релизом, но перед внедрением в продукт нужен короткий чек-лист.
- Проверьте свою задачу на batch size 1: именно там обещанный выигрыш должен быть заметнее.
- Сравните не только tokens/s, но и качество финального ответа: Google сама предупреждает о trade-off.
- Отдельно измерьте Apple Silicon, если целевая аудитория сидит на Mac: официальный релиз не обещает тот же прирост.
- Разделите память агента по доменам: рабочие документы, личный профиль, инструменты и временный контекст не должны смешиваться без правил.
- Логируйте случаи, когда memory retrieval меняет решение агента. Иначе sycophancy и tool-call drift будет сложно поймать.
FAQ
Что такое DiffusionGemma?
DiffusionGemma - экспериментальная открытая diffusion-LLM Google DeepMind на базе Gemma 4 26B A4B. Она генерирует текст блоками через discrete diffusion и рассчитана на быстрые локальные сценарии на выделенных GPU.
Почему DiffusionGemma не заменяет Gemma 4?
Потому что её преимущество - скорость в низкопараллельных локальных сценариях, а не максимальное качество во всех задачах. Google прямо рекомендует стандартную Gemma 4 для production-выходов, где качество важнее latency.
Вывод
DiffusionGemma показывает, куда движутся локальные LLM: меньше ожидания между токенами, больше параллельной работы на GPU, больше экспериментов с агентными циклами на устройстве. Для разработчиков это интересный новый инструмент, особенно если продукт упирается в latency.
Но релиз не делает обычные LLM устаревшими. DiffusionGemma надо оценивать как специализированную модель: быструю, открытую, экспериментальную и требовательную к инженерным guardrails. Если в системе есть долговременная память, эти guardrails должны покрывать не только inference, но и то, какие воспоминания агент вообще имеет право поднимать в контекст.



