SubQ LLM: что стоит за заявлениями о sparse attention и 12 млн токенов
SubQ заявляет sparse attention, 12 млн токенов и резкое снижение стоимости длинного контекста. Разбираем, что подтверждено, а что пока остаётся claim.

SubQ LLM: что стоит за заявлениями о sparse attention и 12 млн токенов
По состоянию на 20 июня 2026 года SubQ LLM - это свежая заявка Subquadratic на решение одной из самых дорогих проблем трансформеров: внимание плохо масштабируется на очень длинный контекст. Компания говорит, что её модель SubQ использует Subquadratic Sparse Attention, держит контекст до 12 млн токенов и резко снижает стоимость длинных запросов.
Звучит как материал для пресс-релиза. Но интереснее другое: Subquadratic уже опубликовала технический отчёт SubQ-1.1-Small, а Appen выпустила стороннюю оценку preview-моделей. Этого достаточно, чтобы отнестись к SubQ серьёзно. Недостаточно, чтобы писать, что bottleneck внимания в LLM закрыт.
MIT Technology Review 19 июня описал новость именно в этой рамке: у SubQ появились дополнительные данные, но скепсис остаётся. Для Toolarium здесь важен не хайп вокруг «12 млн токенов», а граница между подтверждённым результатом, вендорским заявлением и тем, что ещё нельзя проверить публично.
Коротко: что заявлено и что подтверждено
| Заявление SubQ | Что подтверждено публично | Что пока не доказано независимо | Практический смысл |
|---|---|---|---|
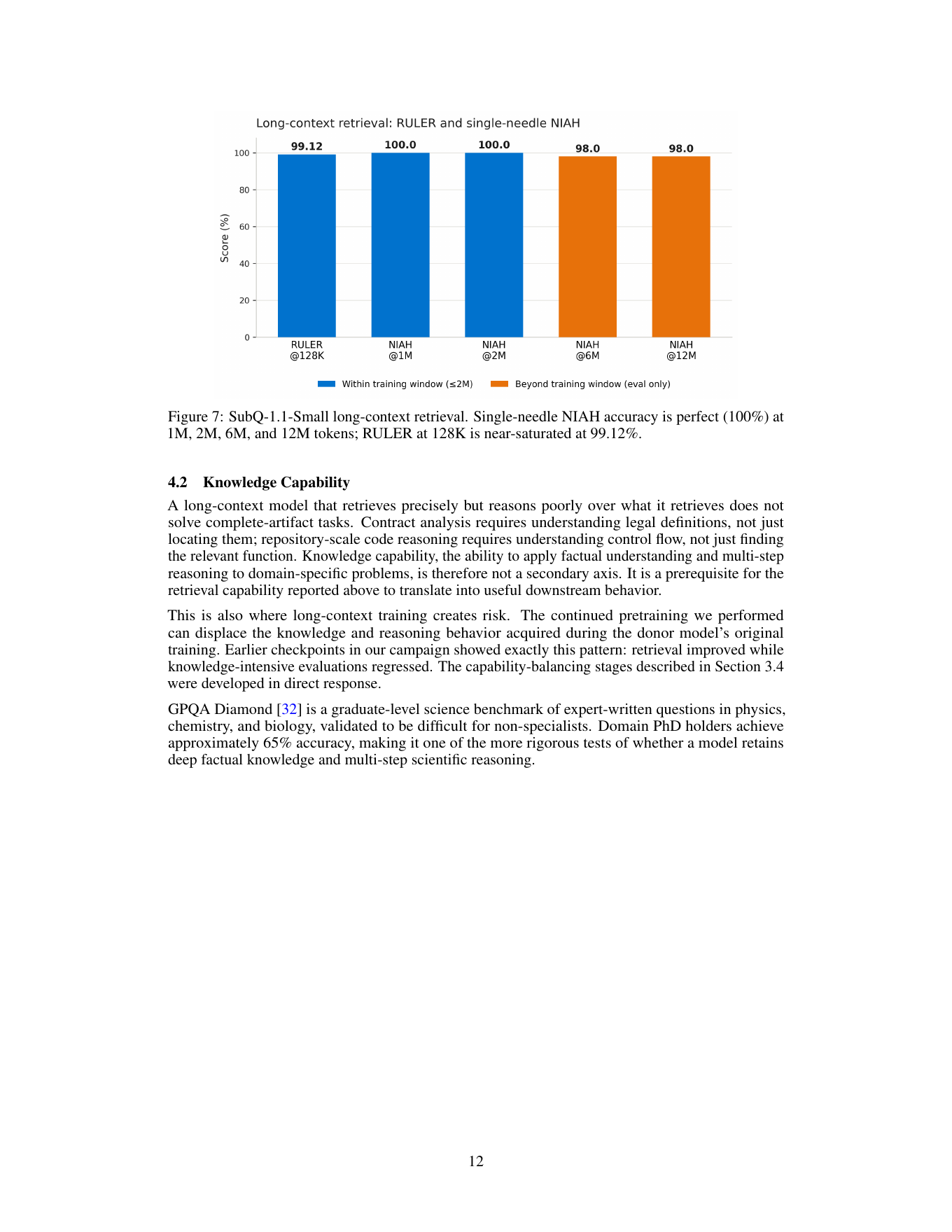
| Контекст до 12 млн токенов | В техническом отчёте и brief Appen: 98% exact-match на NIAH при 6M и 12M токенов; 100% при 1M и 2M. | Что такая длина стабильно помогает в широком наборе реальных задач, а не только в контролируемом retrieval-тесте. | Можно анализировать более крупные артефакты без агрессивного разбиения на куски. |
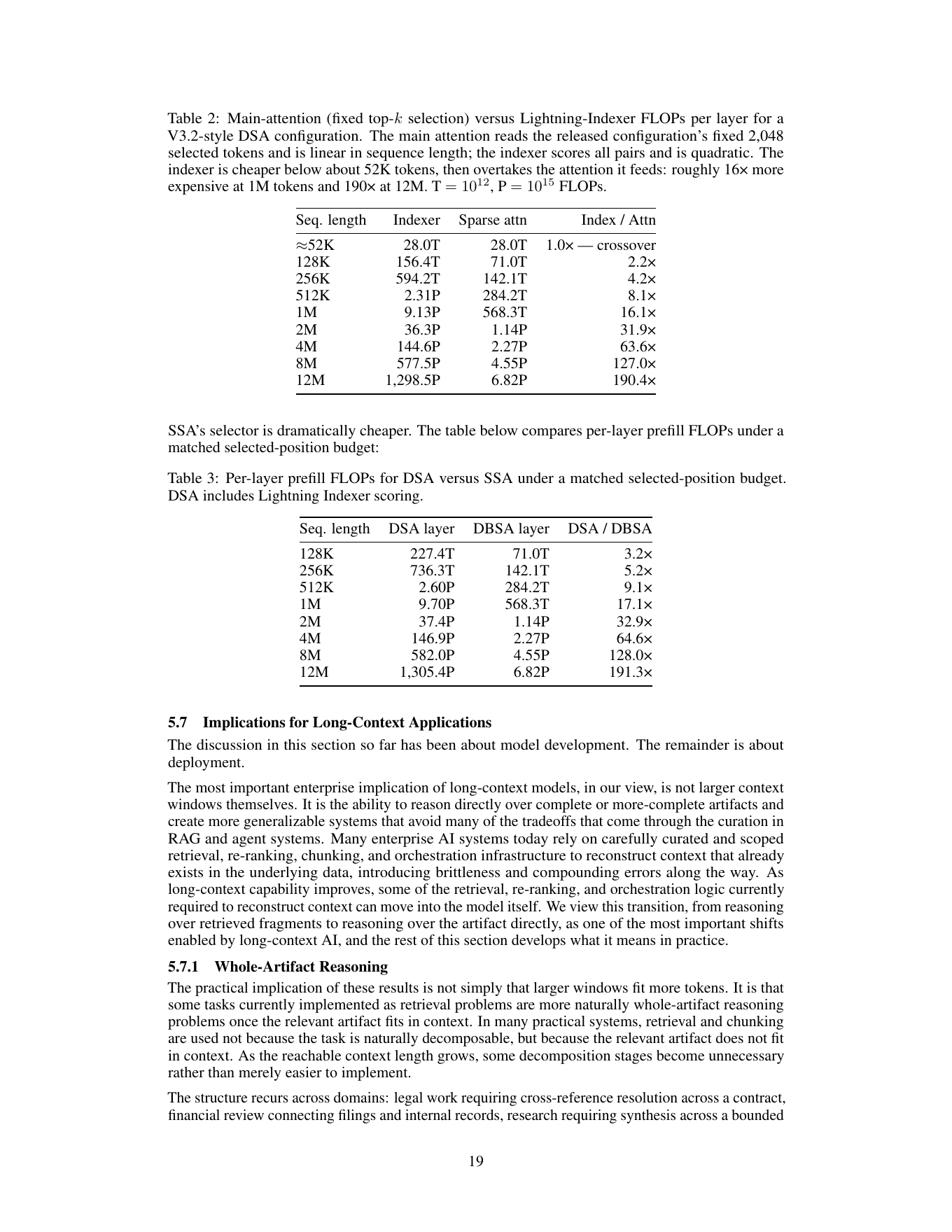
| Subquadratic Sparse Attention снижает стоимость внимания | Отчёт SubQ-1.1-Small: 64,5x меньше attention FLOPs, чем dense attention, на 1M токенов. Сайт Subquadratic также заявляет 56x ускорение относительно FlashAttention-2 на 1M-token attention layer. | Полная экономика продукта: цена API, latency на рабочих нагрузках, стоимость tool-use и всей agent pipeline. | Если результат воспроизводится, long-context prefill перестаёт быть главным тормозом для части задач. |
| Модель сохраняет coding-качество | Appen оценила 1 055 задач LiveCodeBench с четырьмя completions на задачу; `subq-2m-preview-small` получил 89,7% pass@4. | Поведение в production-репозиториях, SWE-задачах с долгим горизонтом и интерактивных coding agents. | SubQ пытается быть не только «поиском иголки», но и рабочим слоем для кодовых баз. |
| SubQ готов для разработчиков и enterprise | Официальные страницы говорят о private beta, design partners и waitlist. | Широкий публичный доступ, SLA, цены, лимиты и воспроизводимость результатов внешними командами. | Переезжать на SubQ пока нельзя; можно отслеживать и тестировать через early access. |
Почему bottleneck внимания вообще мешает LLM
Обычный transformer сравнивает токены друг с другом через attention. При плотном внимании стоимость растёт квадратично: в два раза больше контекст - примерно в четыре раза больше парных сравнений. Для короткого диалога это не драма. Для целого репозитория, финансового архива или длинной памяти агента это быстро становится счётом за вычисления.
FlashAttention и похожие оптимизации сделали dense attention практичнее: меньше лишних обращений к памяти, лучше работа на GPU, быстрее ядра. Но асимптотика не меняется. В отчёте SubQ-1.1-Small прямо сказано: FlashAttention снижает memory footprint, но сохраняет квадратичный рост compute.
SubQ атакует проблему ниже уровнем. Вместо того чтобы ускорять плотное внимание, Subquadratic пытается научить модель выбирать только важные связи между токенами. В их формулировке SSA - content-dependent sparse attention: механизм отбора зависит от содержимого входа, а не от заранее заданного шаблона позиций.
Что такое Subquadratic Sparse Attention
Subquadratic Sparse Attention, или SSA, не стоит путать с RAG, context compression или обычным chunking. RAG сначала выбирает фрагменты извне, а потом отдаёт их модели. Context compression пытается сжать уже найденный контекст. SSA меняет сам механизм внимания внутри модели: она должна решать, на какие пары токенов смотреть, в процессе обработки длинной последовательности.
В техническом отчёте Subquadratic пишет, что SubQ-1.1-Small не обучали с нуля. Команда взяла существующую open-weight frontier model и заменила dense attention на SSA, после чего провела staged context extension: 262K, 512K, 1M и 2M токенов. MIT Technology Review дополнительно указывает, что для bootstrap использовались веса одной из версий Qwen. Это нормальная практика для модельных команд, но она делает сильные формулировки про «полностью новую архитектуру» менее чистыми.
Главное число в отчёте: при 12M токенов модель смотрит только на 0,13% пар токенов и всё равно держит 98% на single-needle retrieval. Это сильный результат. Но это не означает, что модель одинаково хорошо рассуждает на любой задаче с 12 млн токенов. Retrieval-тест проверяет, нашла ли модель нужный факт. Реальная работа с репозиторием или контрактом требует ещё и правильной композиции фактов.
Что именно проверяла Appen
Appen опубликовала brief 16 июня 2026 года. Оговорка важна: Subquadratic привлекла Appen для независимой оценки своих preview-моделей. До полного воспроизведения сообществом ещё далеко, зато это сильнее, чем набор только внутренних скриншотов и self-reported scores.
По long-context retrieval Appen использовала `niah_single_1` из RULER: 50 samples на каждый context tier, temperature 0, zero execution errors. На 1M и 2M SubQ вернул целевое значение verbatim на каждом sample. На 6M и 12M nano-вариант удержал 98% exact-match.
По coding Appen взяла LiveCodeBench. Это лучше, чем статический набор задач, потому что benchmark регулярно пополняется задачами из реальных соревнований и сложнее поддаётся заучиванию. Appen оценила 1 055 задач, четыре completion на каждую, всего 4 220 прогонов. Итог для `subq-2m-preview-small` - 89,7% pass@4.
Эти данные хорошо защищают узкий тезис: SubQ умеет держать очень длинный retrieval и не разваливается на части coding-бенчмарков. Они не закрывают более широкий тезис: «SubQ решила long-context reasoning». Для этого нужны публичный доступ, внешние повторения, реальные задачи с несколькими этапами и сравнение полной стоимости, а не только attention layer.
Почему это важно для coding agents
Если claim SubQ выдержит проверку, главный выигрыш будет не в красивом числе 12M. Практический выигрыш - меньше разрывов контекста. У coding agents сегодня много инженерной обвязки уходит на то, чтобы решить, какие файлы, диффы, issue, тесты и логи показать модели прямо сейчас. Мы уже разбирали это в материале о том, почему context compression ломает AI coding agents: когда важный фрагмент выкинут или сжат неправильно, агент начинает уверенно работать по неполной картине.
Длинный контекст помогает иначе поставить задачу. Вместо «найди пять релевантных кусков и надейся, что они достаточны» появляется режим «положи в контекст весь ограниченный артефакт». Для кода это может быть модуль или репозиторий, для юристов - договор и приложения, для финансов - набор отчётов и внутренних таблиц.
Похожую гонку за длинным контекстом мы видели в статье про GLM-5.2 с контекстом 1M токенов. Разница в том, что SubQ делает ставку не только на размер окна, а на стоимость его обработки. Поэтому тема пересекается и с экономикой LLM: если prefill длинного контекста дешевеет, меняется расчёт, который мы разбирали в материале про стоимость токенов в enterprise AI.
Где нужен скепсис
Первое ограничение - доступ. Subquadratic говорит о private beta, design partners и waitlist. Пока модель нельзя просто открыть, прогнать свой репозиторий, сравнить latency и получить счёт за API. Для редакционной оценки это значит одно: мы можем анализировать опубликованные материалы, но не можем проверить продукт как пользователь.
Второе - тип доказательства. NIAH и RULER полезны, но они не заменяют длинные рабочие сценарии. Модель может отлично достать UUID из 12M токенов и хуже справиться с задачей, где нужно удержать несколько противоречивых требований, перепроверить изменения в коде и не сломать тесты. Benchmark показывает ось способности, а не всю поверхность поведения.
Третье - архитектурный claim. SubQ-1.1-Small, по отчёту, построен через conversion существующей open-weight модели. MIT Technology Review пишет про bootstrap от Qwen. Результат остаётся важным, а формулировку «мы построили всё с нуля» после этого лучше читать осторожно. Для рынка важнее не чистота происхождения весов, а воспроизводимость: сможет ли Subquadratic стабильно выпускать модели разных размеров и давать внешним командам проверять цифры.
Четвёртое - стоимость. Subquadratic показывает сильные compute-числа, но публичной страницы pricing нет. Пока нет тарифов, SLA и воспроизводимых end-to-end тестов, нельзя уверенно считать, во сколько SubQ обойдётся в production. Экономия attention layer может раствориться в orchestration, tool calls, повторных запросах, кэше и ограничениях доступности.
FAQ: три частых вопроса про SubQ LLM
Что такое bottleneck внимания в LLM?
Это проблема стоимости attention на длинных входах. В dense attention каждый токен сравнивается со многими другими токенами, поэтому вычисления растут примерно как квадрат длины контекста. Чем длиннее prompt, тем дороже prefill и тем сложнее держать latency в разумных пределах.
Чем sparse attention отличается от FlashAttention?
FlashAttention ускоряет выполнение dense attention и снижает нагрузку на память, но не меняет сам факт, что модель считает плотные связи. Sparse attention пытается считать меньше связей: выбрать те пары токенов, которые действительно нужны. SubQ заявляет именно такой архитектурный ход, а не только оптимизацию GPU-ядра.
12 млн токенов заменят RAG?
Нет. Технический отчёт SubQ аккуратно формулирует более узкий тезис: часть scaffolding существует потому, что артефакт не помещается в контекст. Если артефакт помещается целиком, некоторые retrieval-этапы могут стать лишними. Но для корпусов больше любого окна, для быстро меняющихся данных и для многоэтапных workflow RAG и orchestration всё равно остаются нужными.
Что смотреть дальше
Для SubQ главный тест впереди. Нужны публичный API, понятные цены, внешние повторения benchmark-результатов и независимые проверки на реальных задачах: большие репозитории, legal due diligence, финансовые наборы, длинная память агентов. Пока этого нет, корректная формула такая: SubQ показала сильные публичные сигналы по длинному retrieval и efficiency, но ещё не доказала, что решила bottleneck внимания как продуктовую проблему.
Если всё подтвердится, последствия будут заметными. Длинный контекст станет не дорогой роскошью для редких запросов, а рабочим режимом для агентных систем. Тогда часть инженерии вокруг chunking, reranking и context compression уйдёт внутрь модели. Если не подтвердится, SubQ останется полезным напоминанием: рынок больше не верит в красивые числа без доступа, воспроизводимости и честного сравнения полной стоимости.
Читайте также
- GLM-5.2: open-source AI coding с контекстом 1M токенов
- Почему context compression ломает AI coding agents
- Стоимость токенов в enterprise AI: почему счёт за LLM растёт
Источники и проверка фактов
Факты и ссылки проверены 20 июня 2026 года. Данные о доступности, ценах и линейке SubQ могут измениться, поэтому перед публикацией или обновлением стоит повторно проверить официальный сайт Subquadratic и страницу Appen.
- MIT Technology Review: A startup claims it broke through a bottleneck that’s holding back LLMs - использовано для новостного повода, статуса скепсиса, ограниченной доступности и контекста Qwen weights.
- Subquadratic official site - использовано для позиционирования SubQ, 12M context, 64,5x compute claim, 56x FlashAttention-2 claim и статуса private preview.
- Subquadratic: Introducing SubQ - использовано для первого объявления SubQ, API, SubQ Code, SubQ Search и private beta.
- Subquadratic: Introducing SubQ 1.1 Small - использовано для статуса release от 16 июня 2026 года, design partners и планов broader lineup.
- SubQ-1.1-Small Technical Report - использовано для SSA, training context, RULER/NIAH, LiveCodeBench, 0,13% token pairs и FLOPs tables.
- Appen: Putting SubQ 1.1 Small Preview to the Test - использовано для сторонней оценки, NIAH methodology, 50 samples per tier и LiveCodeBench pass@4.