GLM-5.2: open-source AI coding с контекстом 1M токенов
GLM-5.2 делает ставку на long-horizon AI coding: 1M-token context, открытые веса, локальный serving и benchmark claims против закрытых frontier-моделей.
GLM-5.2: open-source AI coding с контекстом 1M токенов
GLM-5.2 - новая модель Z.ai для долгих агентных задач с кодом. По состоянию на 17 июня 2026 года официальная документация Z.ai указывает для неё контекст 1M токенов и максимум 128K output tokens, а карточка на Hugging Face показывает лицензию MIT и публично доступные веса.
Z.ai пытается доказать конкретный тезис: open-source AI coding-модель может работать в режиме длинного инженерного цикла - прочитать крупный проект, удержать ограничения, выполнить серию изменений и не развалиться на середине. Это уже территория coding agents, где обычно сильнее закрытые frontier-модели.
Что именно выпустила Z.ai
Официальный блог Z.ai датирован 16 июня 2026 года и описывает GLM-5.2 как флагманскую модель для long-horizon tasks. В документации та же модель вынесена в отдельную страницу GLM-5.2: текстовый ввод, текстовый вывод, контекст 1M и максимальная длина ответа 128K. В карточке Hugging Face модель проходит как zai-org/GLM-5.2, с тегами Transformers и Safetensors.
Важно развести два слова, которые часто смешивают. Z.ai называет релиз "Pure Open" и указывает MIT license. При этом для практики разработчика всё равно остаются обычные вопросы open-source внедрения: размер модели, инфраструктура для инференса, лицензии зависимостей, качество на вашем коде и режимы использования в корпоративном контуре.
Есть и небольшая несостыковка в отображении масштаба модели. Hugging Face показывает "753B params", а таблица скачивания в GitHub-репозитории Z.ai маркирует GLM-5.2 как "744B-A40B". Для читателя вывод один: это крупная MoE-модель, которую локально запускают как инфраструктурный проект, а не как модель для рабочего ноутбука.
Что изменилось для разработчиков
| Фактор | Что заявлено | Почему важно разработчикам | Ограничение |
|---|---|---|---|
| Контекст | 1M input context и до 128K output tokens в документации Z.ai. | Можно давать модели больше кода, логов, требований, тестов и архитектурных правил в одном цикле. | Длинный контекст сам по себе не доказывает качество. Нужно проверять удержание требований на реальных задачах. |
| Архитектура | IndexShare для DSA и улучшенный MTP для speculative decoding; Z.ai заявляет 2.9x меньше FLOPs у indexer на 1M context и до 20% прироста acceptance length. | Если это работает в production-нагрузке, длинный контекст становится менее дорогим и более пригодным для агентных циклов. | Это технические заявления вендора и paper-методика; нужно смотреть latency, память и throughput в вашей инфраструктуре. |
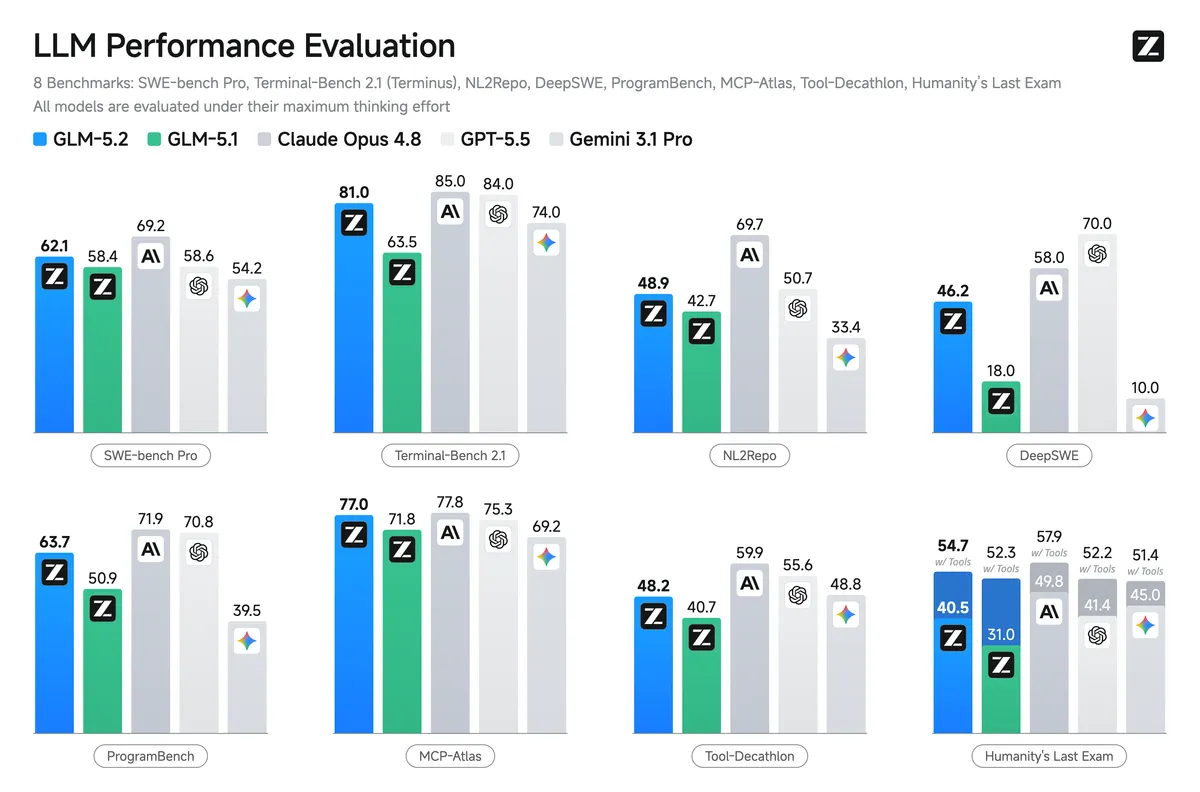
| Coding benchmarks | В таблице Z.ai: 62.1 на SWE-bench Pro, 81.0 на Terminal-Bench 2.1, 74.4 на FrontierSWE Dominance. | Модель выглядит сильной именно в задачах с репозиториями, терминалом и длинным инженерным контекстом. | Это vendor-reported benchmark claims. Нельзя писать, что GLM-5.2 "победила Claude" без независимой проверки. |
| Открытый доступ | Веса опубликованы на Hugging Face и ModelScope; лицензия на Hugging Face указана как MIT. | Команда может строить self-hosted контур для чувствительного кода и не зависеть полностью от закрытого API. | Self-host не бесплатен: нужны GPU/NPU, память, обслуживание инференса и проверка compliance. |
| Local serving | В README перечислены SGLang, vLLM, Transformers, KTransformers, xLLM и Ascend-сценарии. | Модель можно встроить в существующий стек inference engines, а не ждать отдельного SaaS-продукта. | Поддержка в README не заменяет нагрузочное тестирование и измерение качества на ваших workflow. |
Benchmark стоит читать с тормозами
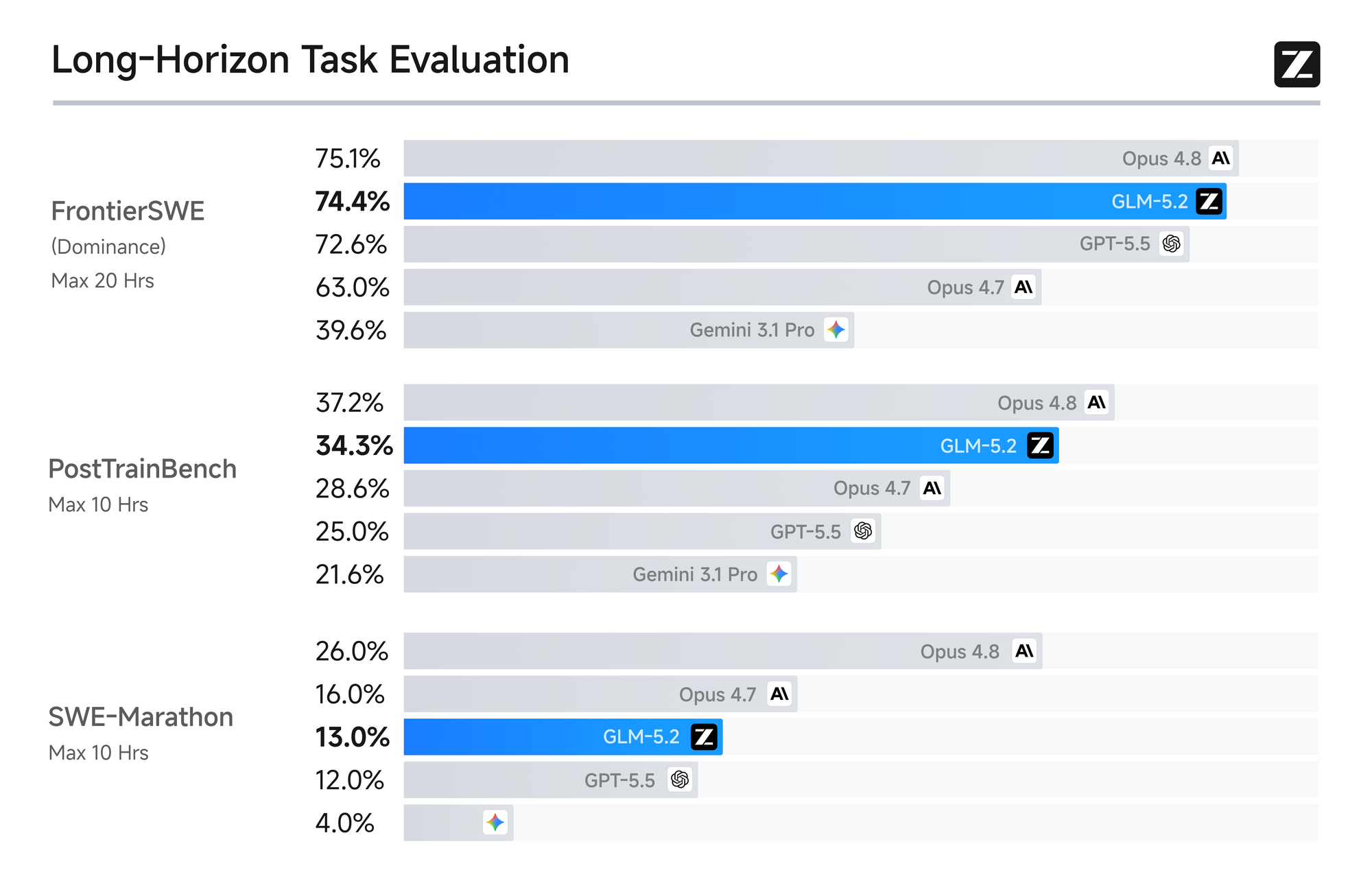
Z.ai приводит сильные цифры. В таблице model card GLM-5.2 получает 81.0 на Terminal-Bench 2.1, 62.1 на SWE-bench Pro, 48.9 на NL2Repo и 76.8 на MCP-Atlas Public Set. В long-horizon блоке компания отдельно выделяет FrontierSWE, PostTrainBench и SWE-Marathon. Для FrontierSWE в блоге указано, что dominance score приведён по состоянию на 16 июня 2026 года.
Эти числа полезны как сигнал, но не как готовый ответ "какую модель брать". В coding agents итоговая ценность считается не только баллом в benchmark. Важны число итераций, цена завершённой задачи, количество ручных правок, стабильность tool calls, качество тестов, поведение на приватном репозитории и то, насколько модель соблюдает внутренние правила команды.
Поэтому GLM-5.2 лучше сравнивать не с лозунгом "замена Claude Code", а с конкретным набором задач: миграция API, рефакторинг модуля, исправление flaky-теста, анализ большого монорепозитория, генерация mini-app или воспроизведение ML-paper. Если модель держит контекст проекта и не теряет ограничения через час работы, это важнее красивой строчки в таблице.
Почему 1M context здесь не маркетинговая мелочь
Большой контекст для coding-модели нужен не ради того, чтобы скормить ей весь репозиторий "на всякий случай". Он нужен для задач, где агент должен помнить карту проекта, контракт API, исторические решения, правила тестирования, логи падений и ограничения, которые нельзя нарушить при следующих шагах.
В документации Z.ai прямо предлагаются такие сценарии: project-level codebase takeover, long-horizon refactoring, проверка production-grade standards, мобильная отладка с ADB/logcat/screenshots, миграция в WeChat Mini Program, mini game development, research reproduction и code-to-video через Remotion. Это не типичный список "попросите модель написать функцию". Это попытка продать GLM-5.2 как рабочий слой для агентного инженерного процесса.
Именно поэтому важна связка с открытыми coding-моделями вроде Kimi K2.7 Code. Open-weight релизы перестают соревноваться только в цене API или размере контекста. Они начинают отвечать на более взрослый вопрос: можно ли строить долгие автономные coding-agent задачи без полной зависимости от закрытого endpoint.
Архитектура: IndexShare и MTP простыми словами
В GLM-5.2 Z.ai делает упор на две технические детали. Первая - IndexShare для sparse attention. По описанию в блоге и README, модель переиспользует один indexer на каждые четыре sparse attention layers. Это должно снижать вычислительные затраты при длинном контексте, особенно на 1M tokens.
Вторая - улучшенный MTP layer для speculative decoding. Идея speculative decoding знакомая: черновая часть модели предлагает несколько следующих токенов, основная модель быстрее принимает или отклоняет их. Z.ai пишет, что в GLM-5.2 acceptance length вырос до 20% относительно baseline в coding scenarios. Для пользователя это должно выражаться не в красивом названии, а в меньшей задержке и более управляемой цене длинных ответов.
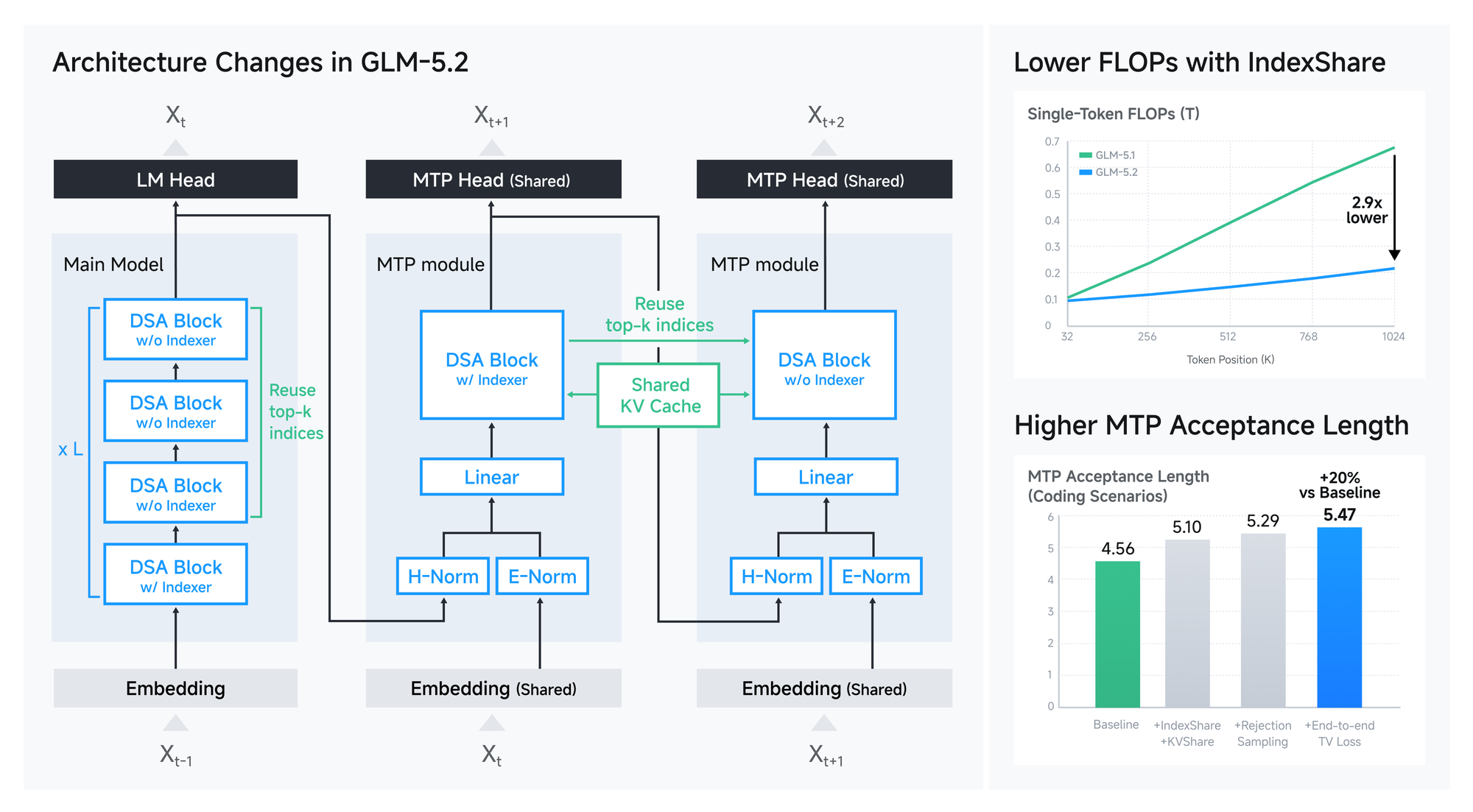
Это место, где релиз становится интереснее обычного "мы увеличили контекст". Если модель действительно удерживает качество на длинных задачах и при этом не превращает каждый агентный запуск в дорогой эксперимент, open-source AI coding получает более практичную основу. Но проверять это нужно в своей среде: на ваших репозиториях, с вашими лимитами и вашим CI.
Open-source AI coding упирается не только в модель
Параллельно с релизами Kimi, Qwen и GLM в open source идёт другой спор: что делать с кодом, который прислал ИИ-агент. На Хабре 17 июня вышел разбор про Zig, NetBSD, curl, Vouch и проблему "denial of attention" - когда мейнтейнеров заваливают правдоподобными, но низкокачественными PR. Это хороший фон для GLM-5.2: сильная открытая модель не отменяет необходимость проверяемого pipeline.
Для команд это означает простую вещь. Если вы запускаете self-hosted coding agent на GLM-5.2, качество нельзя держать только на доверии к модели. Нужны тесты, линтеры, secret scanning, license scanning, правила ревью, запрет на произвольные коммиты и понятные границы задачи. Модель может ускорить разработку, но ответственность всё равно остаётся у команды.
В этом смысле GLM-5.2 ближе к теме долгих автономных coding-agent задач, чем к списку "лучшие open-source модели 2026". Её надо оценивать как часть инженерного контура: модель, inference engine, агентная оболочка, CI, хранилище контекста, политика доступа и fallback на другую модель.
Можно ли запустить GLM-5.2 локально
Да, но слово "локально" здесь не означает "на MacBook за пять минут". В README Z.ai перечислены SGLang, vLLM, Transformers, KTransformers, xLLM и Ascend-сценарии; Hugging Face показывает Safetensors и model card для zai-org/GLM-5.2. Это база для self-hosted развёртывания, но сама модель большая.
Практический маршрут такой: сначала проверить API или managed-доступ, затем прогнать несколько собственных engineering tasks, потом считать, окупается ли self-host. Если у вас чувствительный код, юридические ограничения или дорогие long-context циклы, свой inference-контур может иметь смысл. Если задача - редкие запросы к агенту, закрытая API или гибридный роутинг могут быть дешевле.
Для технического развёртывания полезно опираться на уже знакомый слой serving. У нас есть отдельный материал про локальный serving LLM через vLLM; GLM-5.2 не стоит превращать в install guide внутри новости, но направление то же: сначала воспроизводимый inference, потом агентные сценарии.
Что делать разработчику прямо сейчас
- Не переносить весь coding stack на GLM-5.2 по benchmark-таблице. Сначала собрать свой eval-набор из реальных задач.
- Отдельно тестировать long-horizon сценарии: рефакторинг, миграции, работу с логами, запуск тестов и повторное исправление ошибок.
- Считать стоимость завершённой задачи, а не только стоимость токенов или наличие открытых весов.
- Проверить лицензию MIT и third-party зависимости до использования в коммерческом self-hosted контуре.
- Оставить fallback на закрытую frontier-модель там, где нужна максимальная надёжность или независимая проверка сложного изменения.
FAQ
Что такое GLM-5.2?
GLM-5.2 - флагманская LLM Z.ai для long-horizon задач. Официальная документация указывает контекст 1M токенов и максимум 128K output tokens. В релизе отдельно выделены coding agents, длинный инженерный контекст и локальное развёртывание.
GLM-5.2 действительно open-source?
На Hugging Face для zai-org/GLM-5.2 указана лицензия MIT, а README Z.ai описывает релиз как Pure Open. При этом перед внедрением всё равно нужно читать конкретные license-файлы, third-party notices и условия использования инфраструктуры.
Можно ли запустить GLM-5.2 локально?
Да. В официальном README перечислены SGLang, vLLM, Transformers, KTransformers, xLLM и Ascend-сценарии. Но это крупная MoE-модель, поэтому self-host требует серьёзной инфраструктуры, а не просто установки пакета.
Чем GLM-5.2 отличается от Kimi и Qwen?
В этой статье GLM-5.2 важна не как "ещё одна открытая модель", а как релиз с акцентом на 1M context и long-horizon engineering. Kimi K2.7 Code сильнее связан с ценой API и открытыми весами, Qwen3.7-Max - с длительными автономными coding-agent задачами. Это соседние, но разные интенты.
Заменяет ли GLM-5.2 Claude Code?
Так писать нельзя без независимых проверок. Z.ai показывает сильные vendor-reported результаты и сценарии использования в Claude Code/OpenCode, но замена зависит от ваших задач, инфраструктуры, качества tool calls, стоимости и требований к безопасности.
Главное
GLM-5.2 стоит читать как серьёзный сигнал для open-source AI coding. Z.ai связывает в одном релизе 1M context, MIT-веса, long-horizon coding benchmarks, IndexShare/MTP и local serving. Это не делает модель автоматической заменой Claude или GPT, но поднимает планку для открытых coding-моделей.
Для разработчиков вывод прагматичный: GLM-5.2 надо не обсуждать абстрактно, а тестировать на своих длинных инженерных задачах. Если модель удерживает контекст проекта, соблюдает правила команды и закрывает задачу с меньшим числом ручных вмешательств, тогда open-source AI coding получает настоящий аргумент. Если нет - красивый 1M context останется строкой в спецификации.
Источники и проверка фактов
Факты, характеристики, benchmark-цифры, изображения и ссылки проверены 17 июня 2026 года. Показатели моделей и условия доступа могут быстро измениться; benchmark claims в тексте помечены как заявления Z.ai до независимой проверки.
- Z.ai blog: GLM-5.2: Built for Long-Horizon Tasks, дата страницы 16 июня 2026 года; использовано для угла релиза, IndexShare/MTP, long-horizon benchmark и изображений.
- Z.ai docs: GLM-5.2, использовано для 1M context, 128K maximum output tokens, capabilities и сценариев использования.
- Hugging Face: zai-org/GLM-5.2, использовано для лицензии MIT, публичной карточки модели, Safetensors и отображения размера модели.
- Z.ai / GLM-5 GitHub, использовано для README, benchmark table, download table, local serving frameworks и официальных изображений.
- IndexCache: Accelerating Sparse Attention via Cross-Layer Index Reuse, использовано как paper-источник по IndexShare/IndexCache.
- GLM-5: from Vibe Coding to Agentic Engineering, использовано как технический отчёт семейства GLM-5.
- Хабр: Гейткипинг 2.0: почему open source воюет с ИИ, использовано как контекст по AI-коду, open source и pipeline-подходу.



