Kimi K2.7 Code: открытые веса против закрытых coding-моделей
Kimi K2.7 Code делает ставку на цену, открытые веса и самостоятельный запуск. Fable/Mythos здесь важны только как контраст риска закрытых API.

Kimi K2.7 Code: открытые веса против закрытых coding-моделей
Kimi K2.7 Code - coding-focused open-weight модель Moonshot AI для агентного программирования и long-context задач с кодом. По состоянию на 13 июня 2026 года её карточка уже опубликована на Hugging Face: 1T параметров в MoE-архитектуре, 32B активных параметров на токен, контекст 256K и отдельный упор на coding agents.
Интрига в том, что Moonshot пытается ударить по закрытым coding-моделям сразу с двух сторон: дешевле API и больше контроля через открытые веса. История с внезапным отключением Claude Fable 5 и Mythos 5 в тот же новостной цикл только усиливает контраст: доступ к закрытой frontier API может оборваться не по технической, а по политико-регуляторной причине.
Что выпустила Moonshot
В официальной карточке Hugging Face Moonshot описывает Kimi K2.7 Code как агентную модель для программирования, построенную поверх Kimi K2.6. Компания заявляет улучшения в long-horizon coding tasks и примерно на 30% меньшее использование thinking-токенов по сравнению с Kimi K2.6.
Технически это Mixture-of-Experts: 1 трлн параметров всего и 32 млрд активных параметров на токен. В карточке также указаны 384 эксперта, 8 выбранных экспертов на токен, 61 слой, словарь 160K и vision encoder MoonViT. Контекстное окно в model card обозначено как 256K, а на странице pricing - как 262 144 токена.
Лицензия на Hugging Face указана как modified-mit. Это важная оговорка: модель можно обсуждать как open-weight, но не стоит автоматически называть её "полностью open source" без чтения конкретных условий лицензии и third-party notices.
Цена: где появляется давление на закрытые модели
По состоянию на 13 июня 2026 года страница Kimi API Pricing показывает для kimi-k2.7-code такие цены за 1 млн токенов: $0.19 за input при cache hit, $0.95 за input при cache miss и $4.00 за output. На той же странице указано, что цены не включают применимые налоги.
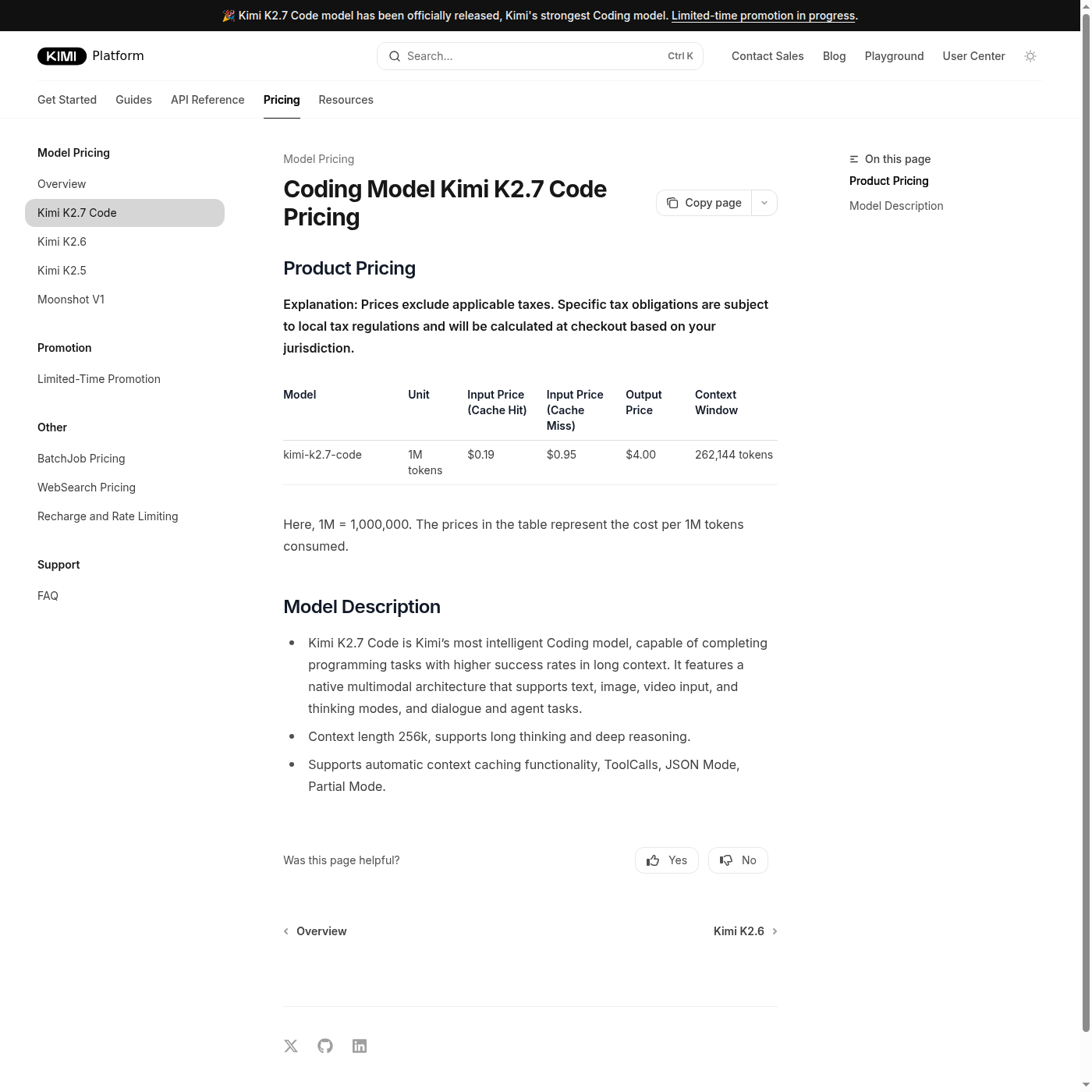
Для разработчика coding agents это не абстрактная экономия. Агентные циклы с кодом обычно тратят много входного контекста: репозиторий, логи, диффы, инструкции, вывод тестов. Если cache hit действительно используется стабильно, стоимость повторных проходов по одному и тому же контексту становится заметно ниже. Для более широкого фона по лимитам и тарифам см. наш разбор цен на ИИ-агенты для программирования.
Но цену нельзя читать отдельно от качества. Вендор может предложить дешёвый миллион токенов, а итоговая задача всё равно станет дороже, если модель чаще застревает, делает лишние tool calls или требует больше итераций. Поэтому Kimi K2.7 Code стоит сравнивать не только по $/MTok, а по цене завершённой задачи: сколько попыток, сколько исправлений и сколько ручного контроля нужно после ответа модели.
Открытые веса и самостоятельный запуск
В карточке модели Moonshot пишет, что API доступен через platform.moonshot.ai и совместим с OpenAI/Anthropic API. Для самостоятельного запуска перечислены vLLM, SGLang и KTransformers; deployment-подход можно переиспользовать из Kimi K2.5/Kimi K2.6. Это делает релиз интересным не только для пользователей API, но и для команд, которые хотят держать часть агентного стека под собственным контролем.
| Вариант | Что получает команда | Где риск |
|---|---|---|
| Kimi API | Быстрый доступ к Kimi K2.7 Code, контекст 256K, кэширование, совместимость с привычными API-паттернами | Зависимость от внешней платформы, тарифов, лимитов и региональной доступности |
| Self-host на открытых весах | Больше контроля над данными, окружением, версией модели и интеграцией в агентный пайплайн | Нужно железо, инженеры для инференса, мониторинг качества и понимание лицензии modified-mit |
| Закрытая frontier API | Часто сильное качество "из коробки" и меньше работы с инфраструктурой | Меньше контроля над доступом, изменениями модели и policy-решениями провайдера |
Самостоятельный запуск не превращает модель в бесплатную. Большая MoE-модель остаётся тяжёлой системой: нужны ускорители, память, квантизация, настройка throughput и отдельная проверка качества на ваших задачах. Зато появляется возможность строить внутренний агентный контур без полной зависимости от одного закрытого endpoint.
У Toolarium уже был похожий сюжет вокруг Composer 2 на базе Kimi K2.5: когда модель становится частью coding-инструмента, разработчикам важно понимать не только качество ответа, но и кто поставляет базовую модель, как она обновляется и какие ограничения могут всплыть в продукте.
Benchmark без рекламного тумана
Moonshot приводит таблицу оценок против Kimi K2.6, GPT-5.5 и Claude Opus 4.8. В ней Kimi K2.7 Code заметно прибавляет относительно K2.6: например, на Kimi Code Bench v2 указано 62.0 против 50.9, на MCP Atlas - 76.0 против 69.4, на MCP Mark Verified - 81.1 против 72.8.
Эти цифры полезны как сигнал направления, но это vendor benchmark. В самой карточке есть важные детали методики: Kimi K2.7 Code и K2.6 тестировались через Kimi Code CLI с thinking mode, GPT-5.5 - в Codex с xhigh mode, Claude Opus 4.8 - в Claude Code с xhigh mode. Такие условия можно сравнивать, но нельзя превращать в лозунг "Kimi победила GPT-5.5 и Claude".
Для практического выбора лучше взять свой набор задач: реальный репозиторий, типичные баги, миграции, flaky-тесты, code review, работу с MCP-инструментами. Если Kimi K2.7 Code экономит деньги на токенах, но проигрывает на количестве итераций, итоговая экономика может быть хуже. Если же модель закрывает типичные задачи за сопоставимое число шагов, дешёвый input и открытые веса становятся сильным аргументом.
Зачем здесь Fable и Mythos
Fable/Mythos здесь нужны как контраст к Kimi-first сюжету. Anthropic дала редкий пример того, почему разработчики всё чаще думают о platform risk.
12 июня 2026 года Anthropic опубликовала заявление: правительство США, ссылаясь на национальную безопасность, выпустило export-control directive о приостановке доступа к Fable 5 и Mythos 5 для foreign nationals. По словам Anthropic, практический эффект директивы - отключение Fable 5 и Mythos 5 для всех клиентов ради compliance; доступ к другим моделям Anthropic не должен быть затронут.
Закрытые модели остаются полезными, но у frontier API есть слой риска, который не сводится к цене и benchmark. Провайдер может изменить доступ, retention policy, safeguards, региональные ограничения или саму модель. Мы подробно разбирали этот тип зависимости в материале про платформенный риск Anthropic.
Что это значит для разработчиков
Kimi K2.7 Code стоит воспринимать как повод пересчитать архитектуру coding-agent стека. Не обязательно мигрировать всё на новую модель. Рациональнее проверить три сценария: дешёвый long-context анализ через API, self-host для чувствительных репозиториев и гибридный маршрутизатор, где закрытая frontier-модель вызывается только для задач, где она реально окупает цену.
- Проверьте модель на собственных задачах, а не только на публичных benchmark.
- Считайте стоимость завершённой задачи, включая повторные попытки и ручные исправления.
- Отдельно протестируйте cache hit: в агентных workflow это может быть главным источником экономии.
- Прочитайте modified-mit license и third-party notices до self-host в продукте.
- Для закрытых API заранее опишите fallback: что делает агент, если нужная модель внезапно недоступна.
FAQ
Что такое Kimi K2.7 Code?
Kimi K2.7 Code - open-weight агентная модель Moonshot AI для задач программирования. В официальной карточке указаны MoE-архитектура, 1T total parameters, 32B activated parameters и контекст 256K.
Сколько стоит Kimi K2.7 Code API?
По состоянию на 13 июня 2026 года официальный pricing показывает $0.19 за 1M input tokens при cache hit, $0.95 за 1M input tokens при cache miss и $4.00 за 1M output tokens. Цены быстро меняются, поэтому перед внедрением нужно смотреть текущую страницу Kimi API Platform.
Можно ли запускать Kimi K2.7 Code самостоятельно?
Да, веса опубликованы на Hugging Face, а карточка модели перечисляет vLLM, SGLang и KTransformers как рекомендуемые inference engines. Но self-host требует своей инфраструктуры, проверки лицензии и измерения качества на ваших задачах.
Вывод
Kimi K2.7 Code важна не как "убийца Claude" или "самая дешёвая модель для кода". Её ценность в другом: Moonshot связывает низкую цену API, открытые веса и long-context coding в одном релизе. Для команд, которые строят coding agents, это хороший повод перестать выбирать модель только по таблице benchmark и начать считать контроль, стоимость задачи и риск зависимости от закрытого endpoint.



