Аудит прозрачности DiffusionGemma: что видно в reasoning
Свежий аудит DiffusionGemma проверяет, насколько reasoning у diffusion-LLM остаётся наблюдаемым: opaque serial depth, token bottleneck и monitorability.

Аудит прозрачности DiffusionGemma: что видно в reasoning
Аудит прозрачности DiffusionGemma - это не ещё один benchmark скорости. Свежая работа на arXiv разбирает более неудобный вопрос: если diffusion-LLM уточняет сразу блок токенов, а не пишет ответ слева направо, остаётся ли у нас достаточно видимых следов reasoning для проверки и мониторинга?
По состоянию на 20 июня 2026 года ответ выглядит осторожно оптимистичным. Авторы показывают, что часть промежуточного состояния DiffusionGemma можно свести к интерпретируемому token bottleneck. Но они же объясняют, почему algorithmic transparency у diffusion-моделей сложнее, чем у обычных autoregressive LLM.
Релиз самой модели мы уже разбирали отдельно в материале «DiffusionGemma: Google DeepMind ускоряет локальные LLM». Здесь другой угол: не насколько модель быстрая, а насколько её ход рассуждения можно увидеть, проверить и использовать в safety-monitoring.
Что проверяли в аудите
Работа How Transparent is DiffusionGemma? подана на arXiv 18 июня 2026 года. Среди авторов - Joshua Engels, Callum McDougall, Bilal Chughtai, Rohin Shah и Neel Nanda; в списке также указаны исследователи Google DeepMind.
DiffusionGemma устроена иначе, чем привычная LLM. В обычной autoregressive-модели следующий токен зависит от уже написанных токенов. У DiffusionGemma есть canvas: блок из 256 позиций, который модель несколько раз очищает от шума. На каждом denoising step могут меняться разные позиции блока, а информация течёт не только слева направо.
Именно эта особенность делает аудит интересным. Chain-of-thought у autoregressive-модели хотя бы примерно совпадает с порядком генерации. У diffusion-LLM промежуточная работа может происходить в более распределённом виде.
| Понятие | Что проверяли | Что нашли | Ограничение |
|---|---|---|---|
| Variable transparency | Понятны ли промежуточные состояния между denoising steps | Информацию можно свести к token bottleneck без падения downstream performance | Это не доказывает, что все скрытые векторы полностью понятны человеку |
| Opaque serial depth | Сколько последовательной работы проходит без интерпретируемого узкого места | Наивно выглядит как 28,6x от Gemma 4, после token bottleneck - 1,1x | Цифры зависят от допущения, что промежуточные состояния интерпретируемы |
| Algorithmic transparency | Можно ли восстановить сам алгоритм reasoning по промежуточным состояниям | Сложнее, потому что весь canvas может меняться на каждом шаге | Модель может распределять рассуждение между позициями и шагами |
| Monitorability | Помогают ли выходы модели внешнему монитору судить о процессе и рисках | DiffusionGemma оказалась примерно сопоставима с Gemma 4 в этих тестах | Monitorability не равна полной безопасности модели |
Почему 28,6x не значит «всё скрыто»
Самая цепкая цифра в статье - 28,6x. Если смотреть на DiffusionGemma наивно, её opaque serial depth оказывается в 28,6 раза выше, чем у соответствующей autoregressive Gemma 4. Проще: между понятными состояниями будто бы проходит намного больше скрытой последовательной работы.
Но это только первая половина вывода. Авторы показывают, что поток информации между denoising steps можно пропустить через интерпретируемый token bottleneck. В таком режиме opaque serial depth снижается до 1,1x от Gemma 4. Это уже не выглядит как полный провал прозрачности.
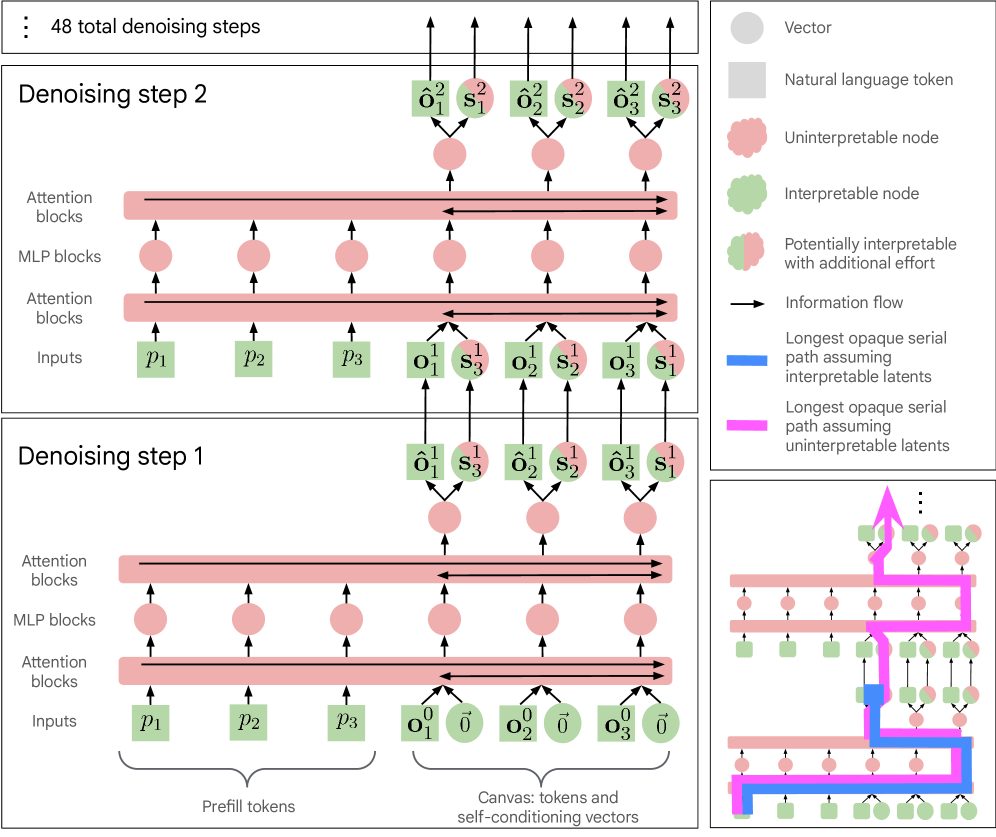
Здесь легко сделать неверный вывод: «раз стало 1,1x, проблема решена». Нет. Правильнее читать это как инженерный сигнал. У текущей DiffusionGemma есть промежуточные состояния, которые можно изучать и частично переводить в токены. Это даёт исследователям точку опоры.
Но эта точка опоры не превращает модель в стеклянный ящик. Внутри всё ещё есть self-conditioning vectors и denoising-процесс, где разные позиции canvas могут влиять друг на друга не в том порядке, в котором человек читает финальный текст.
Где reasoning становится непривычным
Главное отличие diffusion-LLM от обычной LLM не в том, что она «думает лучше». Отличие в том, что она может пересматривать весь блок. Токен в начале ответа может измениться после того, как модель уже получила информацию от более поздних позиций. Для человека это выглядит странно: текст ещё не написан, но будущая часть уже влияет на текущую.
Авторы называют несколько явлений, которые стоит отслеживать отдельно:
- non-chronological reasoning - модель может заранее предсказывать длину ответа или менять ранние позиции после поздних подсказок;
- token smearing - вероятность одного токена может размазываться по соседним позициям;
- sequence smearing - похожий эффект возникает уже на уровне последовательностей;
- intermediate-context reasoning - промежуточные токены внутри canvas могут временно играть роль контекста, хотя в финальном ответе их может не быть.
Для разработчика это не академическая тонкость. Если продукт полагается на аудит reasoning, логи и внешние мониторы, то порядок генерации имеет значение. У autoregressive-модели монитор видит цепочку, пусть и несовершенную. У diffusion-подхода цепочка может быть больше похожа на черновик, который несколько раз переписывают изнутри.
Поэтому эту работу стоит читать рядом с более широким кластером safety reviews. В материале про frontier AI safety reviews мы уже писали, что сильным моделям всё чаще нужны не только финальные system cards, но и регулярные проверки поведения до и после релиза. Аудит DiffusionGemma показывает, что для новых архитектур проверять придётся не только ответы, но и способ их появления.
Monitorability: меньше текста, но не меньше вопросов
Отдельный блок работы посвящён monitorability. Это прикладная проверка: насколько выходы модели полезны внешнему монитору, который пытается понять свойства действия или reasoning-процесса. Здесь DiffusionGemma сравнивают с Gemma 4 на наборах задач из monitorability-evals.
На графике видно, что DiffusionGemma выдаёт меньше символов в chain-of-thought во всех показанных категориях. Например, средний объём reasoning-текста ниже на DAFT, GPQA и process-задачах. При этом общий вывод авторов не сводится к «короче значит хуже»: в их адаптированных проверках DiffusionGemma оказалась примерно сопоставима с Gemma 4 по monitorability.
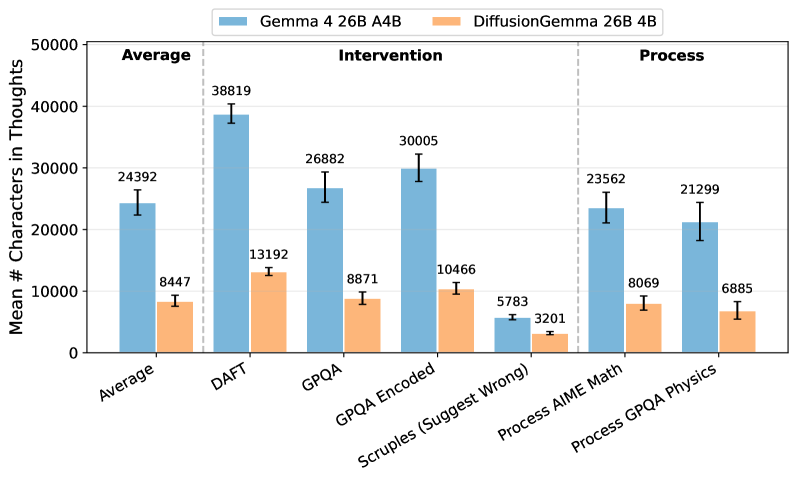
Это важная развилка. В мире reasoning-моделей длинная цепочка мыслей часто кажется признаком лучшей проверяемости. Но длина сама по себе мало что доказывает. Мониторинг зависит от того, есть ли в промежуточных и финальных выходах нужные признаки решения, а не просто от числа символов.
Для читателя Toolarium полезная параллель - материал про модели рассуждения o3 и DeepSeek-R1. Там речь шла о новой парадигме reasoning, где важны не только финальные ответы, но и процесс. DiffusionGemma добавляет к этому ещё одну проблему: сам процесс может быть не линейным.
Что это меняет для внедрения diffusion-LLM
На уровне продукта вывод простой: DiffusionGemma нельзя оценивать только по latency. Быстрая модель полезна для локальных ассистентов, inline editing, code workflows и агентных циклов. Но если модель входит в чувствительный контур, ей нужен отдельный transparency regression test.
Минимальный набор проверок выглядит так:
- сравнить не только качество ответа, но и пригодность intermediate states для мониторинга;
- отдельно тестировать случаи, где ранние токены могут зависеть от поздних позиций canvas;
- логировать denoising-процесс там, где это возможно без утечки пользовательских данных;
- проверять, не ломается ли monitorability после fine-tuning или квантизации;
- не переносить выводы этой работы на будущие diffusion-LLM без повторного аудита.
Последний пункт самый неприятный. Авторы прямо оставляют пространство для другого исхода: будущие text diffusion models с другим training paradigm, большим canvas или менее понятными intermediate states могут быть хуже для прозрачности. Значит, аудит DiffusionGemma - это не сертификат для всего класса моделей, а первый ориентир.
Что нельзя выводить из этого аудита
Работа сильная именно тем, что не продаёт простой ответ. Поэтому редакционно важно не усилить её сверх источника.
| Плохой вывод | Корректный вывод |
|---|---|
| DiffusionGemma полностью прозрачна | У текущей DiffusionGemma нашли интерпретируемые промежуточные сигналы, но algorithmic transparency остаётся сложной |
| Diffusion-LLM безопаснее autoregressive LLM | В этой работе DiffusionGemma показала сопоставимую monitorability с Gemma 4 на выбранных тестах |
| 28,6x отменяется и можно смотреть только на 1,1x | 1,1x возникает при допущении, что inter-step token bottleneck действительно интерпретируем |
| Длинный chain-of-thought больше не нужен | Длина reasoning-текста не равна проверяемости; нужны отдельные monitorability-тесты |
Для индустрии это хороший знак, но не повод расслабиться. Новые архитектуры будут всё чаще уходить от простого «токен за токеном». Чем больше работы переносится в промежуточные состояния, тем важнее заранее решать, какие из этих состояний сохранять, как их проверять и кто имеет право смотреть такие логи.
Вывод
Аудит прозрачности DiffusionGemma показывает редкую вещь: скорость и непривычная архитектура не обязательно убивают наблюдаемость reasoning. В текущей модели есть промежуточные token-level сигналы, которые помогают восстановить часть процесса и снизить оценку opaque serial depth с 28,6x до 1,1x относительно Gemma 4.
Но это не финальная победа прозрачности. DiffusionGemma может менять весь canvas на каждом denoising step, использовать будущие позиции для ранних токенов и распределять reasoning так, как обычный chain-of-thought не показывает напрямую. Поэтому правильная реакция на работу - не «модель прозрачна», а «для diffusion-LLM появился конкретный набор вопросов, которые надо проверять перед внедрением».
Источники
- arXiv: How Transparent is DiffusionGemma?, submitted 18 June 2026; использовано для variable transparency, algorithmic transparency, opaque serial depth, monitorability и case studies; проверено 20 июня 2026 года.
- arXiv HTML: How Transparent is DiffusionGemma?; использовано для Figure 1 и Figure 5; проверено 20 июня 2026 года.
- Google AI for Developers: DiffusionGemma model card; использовано для 25,2B total parameters, 3,8B active parameters, context length до 256K, canvas length 256 и Apache 2.0; проверено 20 июня 2026 года.
- Google DeepMind: DiffusionGemma; использовано для официальной страницы модели и feature image; проверено 20 июня 2026 года.
- Google Blog: DiffusionGemma launch post; использовано для контекста релиза и ограничения про качество/скорость; проверено 20 июня 2026 года.
- Google Developers Blog: DiffusionGemma developer guide; использовано для prefill, denoising, bidirectional attention и 256-token canvas; проверено 20 июня 2026 года.