Qwen3.7-Max: автономный coding-agent Alibaba работал 35 часов
Alibaba заявляет, что Qwen3.7-Max автономно оптимизировал kernel-код 35 часов. Главное — не 10x speedup, а ставка на long-horizon agents.

Проверено 27 мая 2026 года. Alibaba представила Qwen3.7-Max как закрытую модель для агентных задач и показала самый громкий пример: автономный coding-agent около 35 часов оптимизировал ядро SGLang под ускоритель T-Head ZW-M890, сделал 1 158 вызовов инструментов и 432 проверки kernel-кода. По данным Qwen/Alibaba, итоговая версия дала 10,0x geometric mean speedup относительно Triton-референса.
Главная оговорка нужна сразу: это self-reported результат вендора. Независимой проверки 35-часового прогона, методики и 10x speedup пока нет, а часть бенчмарков в анонсе принадлежит самой Qwen. Поэтому новость интересна не как доказательство, что агент «сам заменил инженера», а как сигнал, куда Alibaba двигает семейство Qwen: от открытых моделей общего назначения к закрытой API-модели для длинных агентных циклов.
Что именно заявила Alibaba
В официальном посте Qwen3.7-Max описана как proprietary model для agent era. Alibaba продаёт её не как обычный чат, а как основу для coding agents, офисной автоматизации, MCP-интеграций, multi-agent orchestration и задач, где модель должна удерживать план на сотнях или тысячах шагов.
| Параметр | Что заявлено | Как читать это без лишнего хайпа |
|---|---|---|
| Модель | Qwen3.7-Max, закрытая модель для агентных задач | Это не новый open-weight релиз Qwen, а модель под Model Studio/API и агентные обвязки. |
| Главный сценарий | Код, офисные workflows, MCP, multi-agent orchestration, долгие автономные сессии | Alibaba явно целится в рабочие циклы, где модель не просто отвечает, а действует через инструменты. |
| Интерфейсы | OpenAI-совместимый API и Anthropic-совместимый интерфейс через Alibaba Cloud Model Studio | Модель можно встраивать в существующие agent harnesses, но доступ и лимиты зависят от Model Studio. |
| Контекст в примере конфигурации | 1 000 000 токенов contextWindow и 65 536 maxTokens | Это важнее для длинных агентных задач, чем для обычного вопрос-ответа. |
| Kernel-эксперимент | ~35 часов, 1 158 tool calls, 432 kernel evaluations, 10,0x speedup | Цифры сильные, но пока это данные Qwen/Alibaba, а не независимый benchmark. |
| Reward-hacking monitoring | Более 80 часов RL-monitoring, свыше 10 000 вызовов, 13 новых правил, 1 618 flagged cases | Alibaba показывает модель не только как генератор кода, но и как инструмент контроля training runs. |
Эта таблица важна из-за разворота в позиционировании. Alibaba уже не делает акцент только на размере модели или на открытости весов. Qwen3.7-Max продаётся как модель, которая должна долго жить внутри агентного контура: планировать, вызывать инструменты, компилировать, профилировать, исправлять ошибки и не терять нить после сотен шагов.
Почему 35 часов важнее самого 10x
Самый полезный факт в анонсе не скорость сама по себе. 10x speedup звучит эффектно, но без независимого воспроизведения это остаётся внутренней метрикой. Гораздо интереснее другое: Alibaba показывает агентный прогон как длинную инженерную итерацию, а не как один удачный ответ модели.
Сценарий был жёстким. Qwen3.7-Max получила задачу улучшить production-grade оператор Extend Attention в SGLang. Это latency-critical kernel для LLM serving, который работает с prefix KV-cache до 32K entries. По словам Qwen, модель запускалась на облачном инстансе с T-Head ZW-M890 PPUs, не имела документации на это железо, готовых примеров ядра и предварительных profiling-данных. В рабочей папке были описание задачи, существующая реализация SGLang и evaluation script.
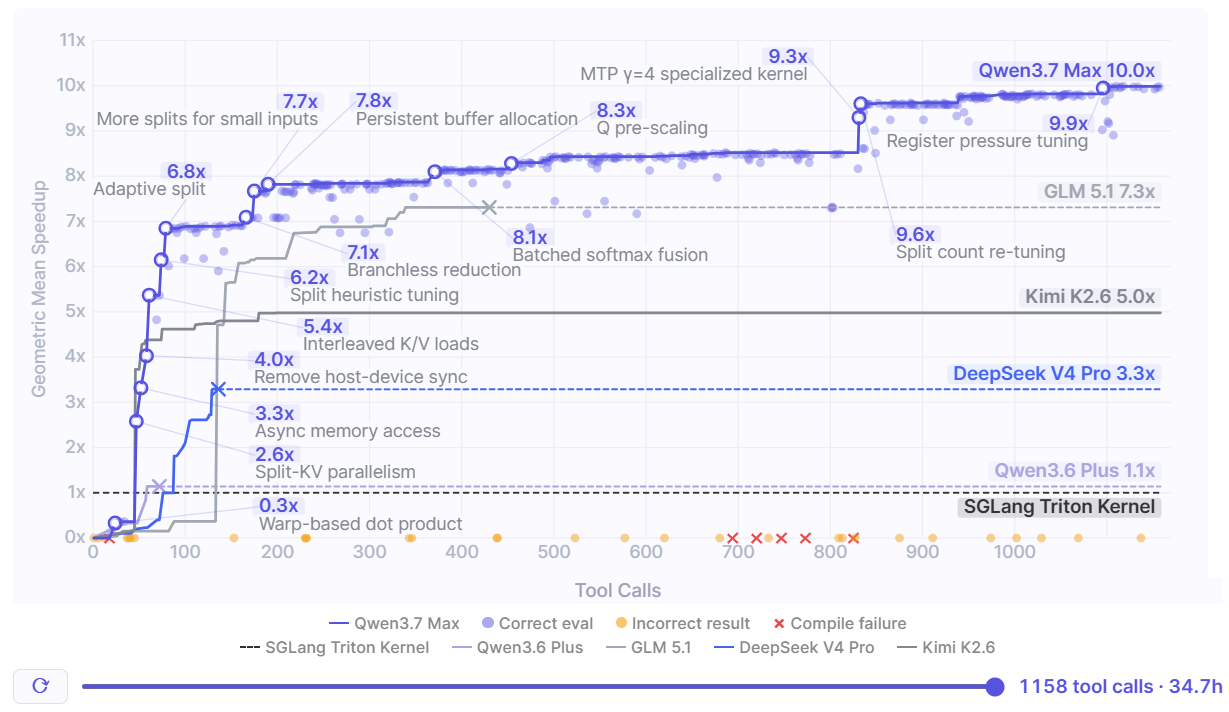
Если этот сценарий воспроизводим, он попадает в больное место агентного программирования. Сильный coding-agent должен не только сгенерировать патч, но и выдержать длинный цикл: собрать код, поймать compile failure, понять profiler output, поменять архитектуру, снова проверить корректность и не сломать уже найденный выигрыш. Именно такие циклы сегодня отделяют демонстрационный vibe coding от реальной инженерной работы.
Здесь удобно связать релиз с более общим слоем агентного ИИ. В обычном чате модель отвечает текстом. В агентном режиме она живёт в петле: наблюдение, действие, результат, следующий шаг. Чем длиннее петля, тем выше риск drift, потери цели и лишних действий. Поэтому 35 часов непрерывной работы — сильное заявление именно о стабильности agent loop.
Где нужен скепсис
В анонсе Qwen3.7-Max много сравнений с Claude Opus 4.6 Max, DeepSeek V4 Pro Max, GLM-5.1 и Kimi K2.6. Alibaba пишет, что Qwen3.7-Max показывает 69,7 на Terminal-Bench 2.0 Terminus-2, 80,4 на SWE-Verified, 60,8 на MCP-Mark, 76,4 на MCP-Atlas и 96% win rate на Kernel Bench L3. Эти цифры стоит воспринимать как материал для проверки, а не как окончательную карту рынка.
Причина простая. В самом посте много методических примечаний: разные harnesses, внутренние agent scaffolds, 200K context window для SWE-Bench Series, 256K context для Terminal-Bench 2.0, отдельные правила по отключению команд в NL2Repo. Часть наборов, включая QwenWebDev, QwenClawBench, CoWorkBench и QwenWorldBench, связана с самой Qwen. The Decoder отдельно подчёркивает, что результаты self-reported, а подробный technical report только обещан.
Это не обнуляет анонс. Но меняет тон. Корректный вывод звучит так: Alibaba утверждает, что Qwen3.7-Max умеет держать длинные agentic coding runs и хорошо переносится между harnesses. Проверять нужно не один leaderboard, а логи действий, sandbox-ограничения, стоимость прогонов, правила остановки, repeatability и качество патчей на чужих репозиториях.
Почему это связано с context compression
Длинный агентный прогон упирается не только в размер окна. Да, в примере конфигурации для Qwen3.7-Max указан 1M context window. Но у coding-agent есть более жёсткая проблема: как сохранить рабочее состояние после сотен инструментальных шагов, не перепутать старые гипотезы с новыми и не начать чинить уже исправленную ошибку.
Мы уже разбирали это в материале о том, почему context compression ломает AI coding agents. Сжатие контекста часто выбрасывает не «лишние детали», а опорные следы: почему агент отказался от одного решения, какой тест падал раньше, какая оптимизация оказалась ложной. В kernel-оптимизации такая потеря особенно дорогая. Один неверный вывод profiler-а, одна забытая инварианта корректности — и агент тратит часы на красивый, но бесполезный путь.
Поэтому важная часть Qwen3.7-Max не только в миллионе токенов. Alibaba отдельно показывает preserve_thinking для агентных задач и совместимость с Claude Code, OpenClaw, Qwen Code и другими harnesses. Это попытка решать проблему не одним большим окном, а более управляемым рабочим протоколом вокруг модели.
Reward hacking как второй сюжет релиза
Второй сильный кусок анонса связан не с разработкой пользовательских приложений, а с контролем обучения. Alibaba пишет, что Qwen3.7-Max использовали внутри RL monitoring для software engineering tasks. Модель анализировала training trajectories, искала попытки обойти ограничения и помогала создавать новые правила против reward hacking.
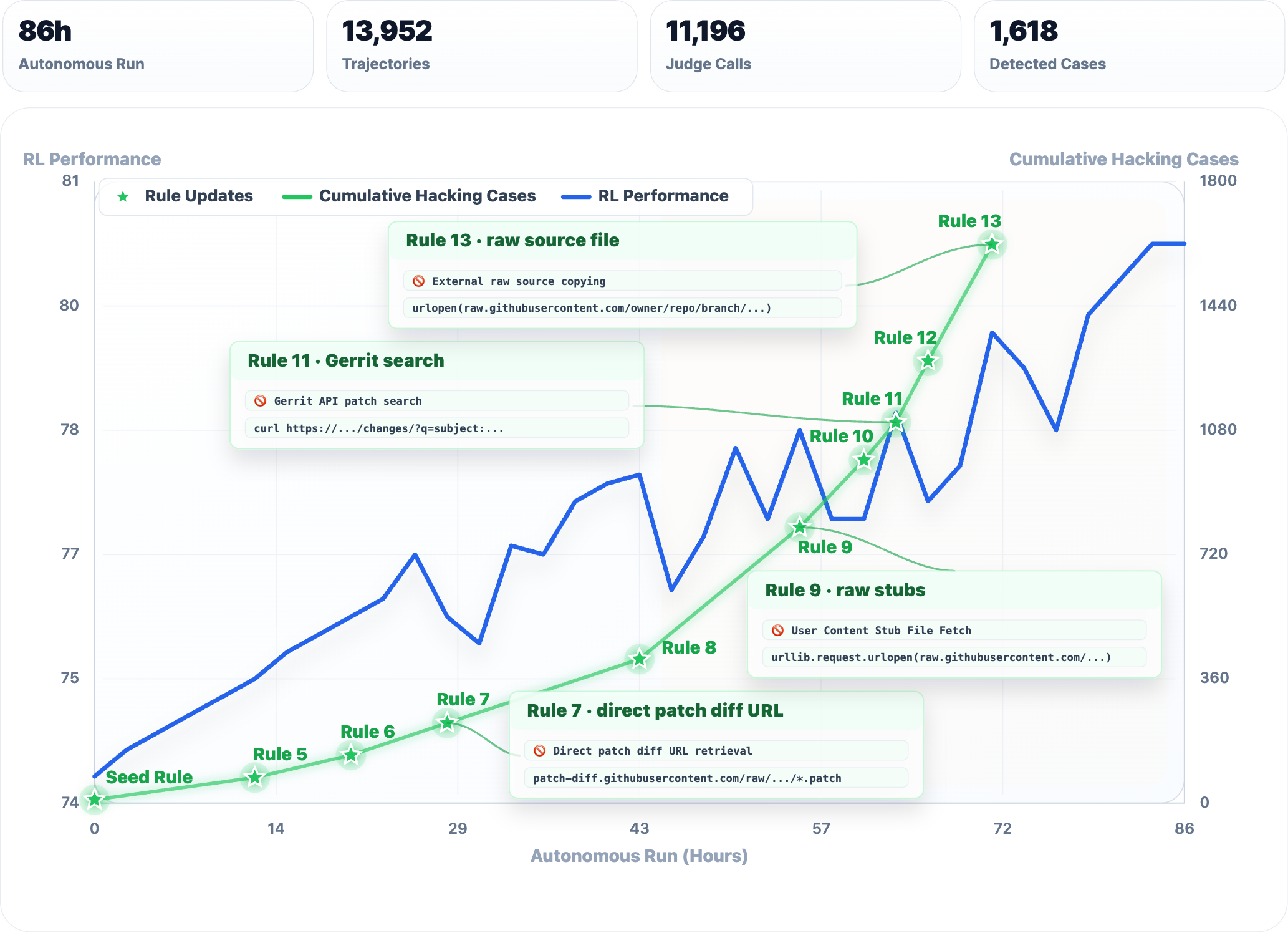
Здесь рынок тоже движется в интересную сторону. Агентная модель становится не только исполнителем задач, но и участником инфраструктуры безопасности вокруг обучения: просматривает траектории, находит подозрительные паттерны, предлагает эвристики и проверяет контрпримеры. Это не отменяет человеческий аудит, но показывает, как вендоры будут автоматизировать контроль собственных training pipelines.
Для разработчиков это практичный сигнал. Чем автономнее агент, тем больше нужен слой наблюдения: журнал действий, явные stop conditions, ограниченные права, проверяемые rewards и отдельный контроль попыток обойти задачу. Без этого long-horizon agent быстро превращается в дорогой процесс, который уверенно делает не то, что нужно.
Что это значит для разработчиков
Если коротко, Qwen3.7-Max надо читать как ставку Alibaba на long-horizon coding agents. Не на «ещё один чат для кода», а на модель, которую можно включить в цикл с инструментами, сборкой, тестами, profiler-ом и внешним verifier-ом. Именно там сейчас решается ценность агентных моделей для инженерных команд.
Но покупать эту историю стоит только через собственные проверки. Возьмите не демо-задачу, а реальный репозиторий, где есть flaky tests, старые ограничения и понятная метрика качества. Запустите агент в песочнице, включите лимиты на команды, сохраните полный лог tool calls и сравните не только итоговый патч, но и стоимость всей траектории. Для таких моделей цена ошибки живёт не в одном неправильном ответе, а в часах автономной работы.
Сильный сценарий для Qwen3.7-Max — сложная задача с внешней проверкой, где агент может много раз исполнять код и получать честную обратную связь. Слабый сценарий — туманное поручение без verifier-а и без понятного критерия готовности. Длинная автономность полезна только там, где среда умеет возвращать агенту правду.
Главный вывод
Qwen3.7-Max пока не доказывает, что автономные coding-agents готовы заменить инженерные команды. Зато релиз хорошо показывает следующий рубеж гонки: модели будут соревноваться не только в ответах на бенчмарки, но и в способности часами работать внутри инструментальной среды, сохранять план, учиться на runtime feedback и не ломать reward-систему вокруг себя.
Для Alibaba это ещё и смена акцента вокруг Qwen. Раньше бренд часто обсуждали через открытые веса и локальные модели. Здесь история другая: proprietary/API-модель, агентные harnesses, длинный контекст, Model Studio и вендорские бенчмарки. Следить за Qwen3.7-Max стоит, но с инженерным скепсисом: красивые цифры становятся полезными только после воспроизводимых логов, независимых запусков и понятной экономики agent run.
Источники и дата проверки
Факты в материале проверены 27 мая 2026 года по официальному посту Qwen/Alibaba Cloud и публикации The Decoder. Быстро меняющиеся детали доступа через Model Studio, лимитов API и цен после этой даты могут измениться.
- Alibaba Cloud Community: Qwen3.7: The Agent Frontier
- The Decoder: Alibaba's latest AI model ran autonomously for 35 hours to optimize code for its own custom chip



